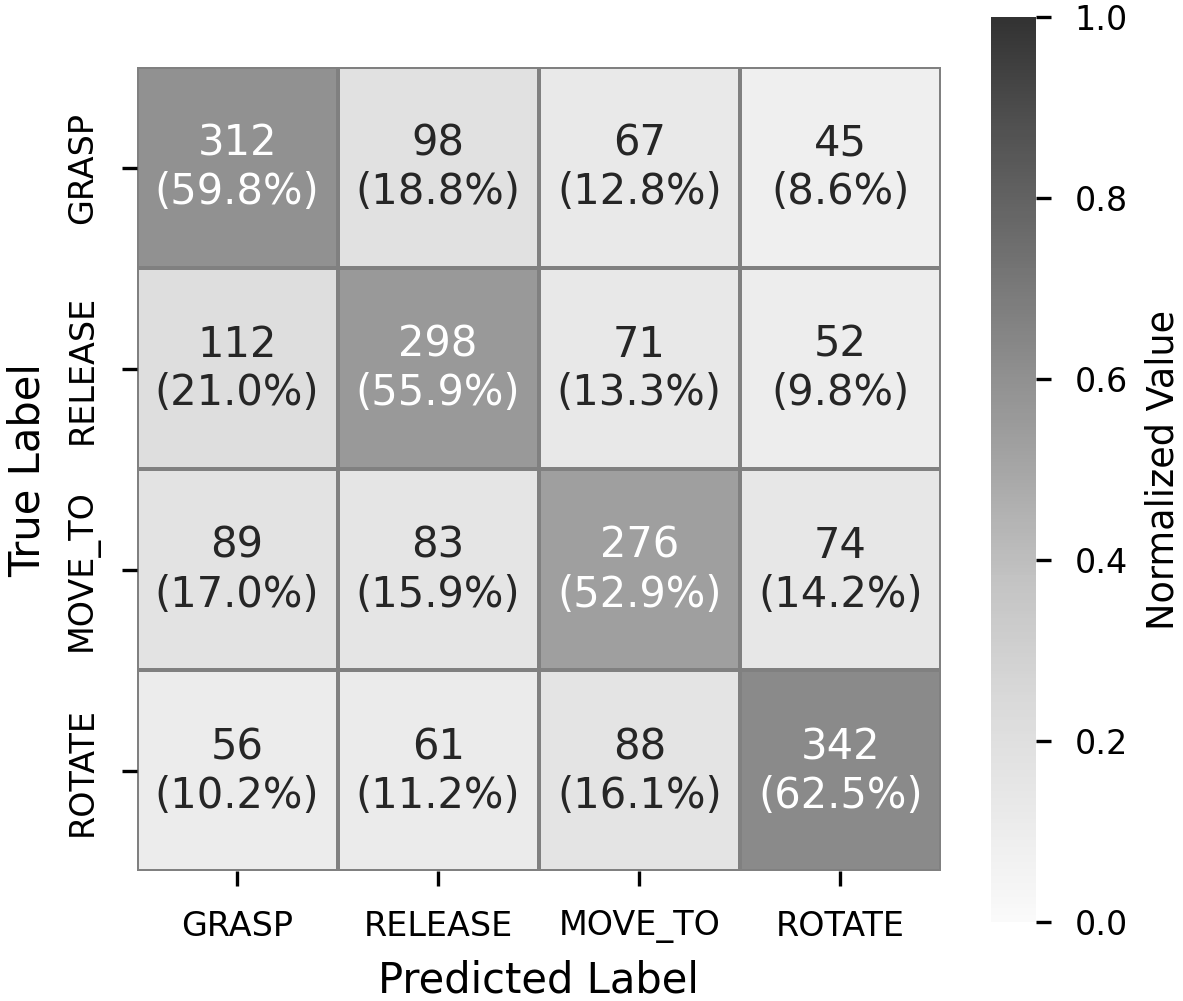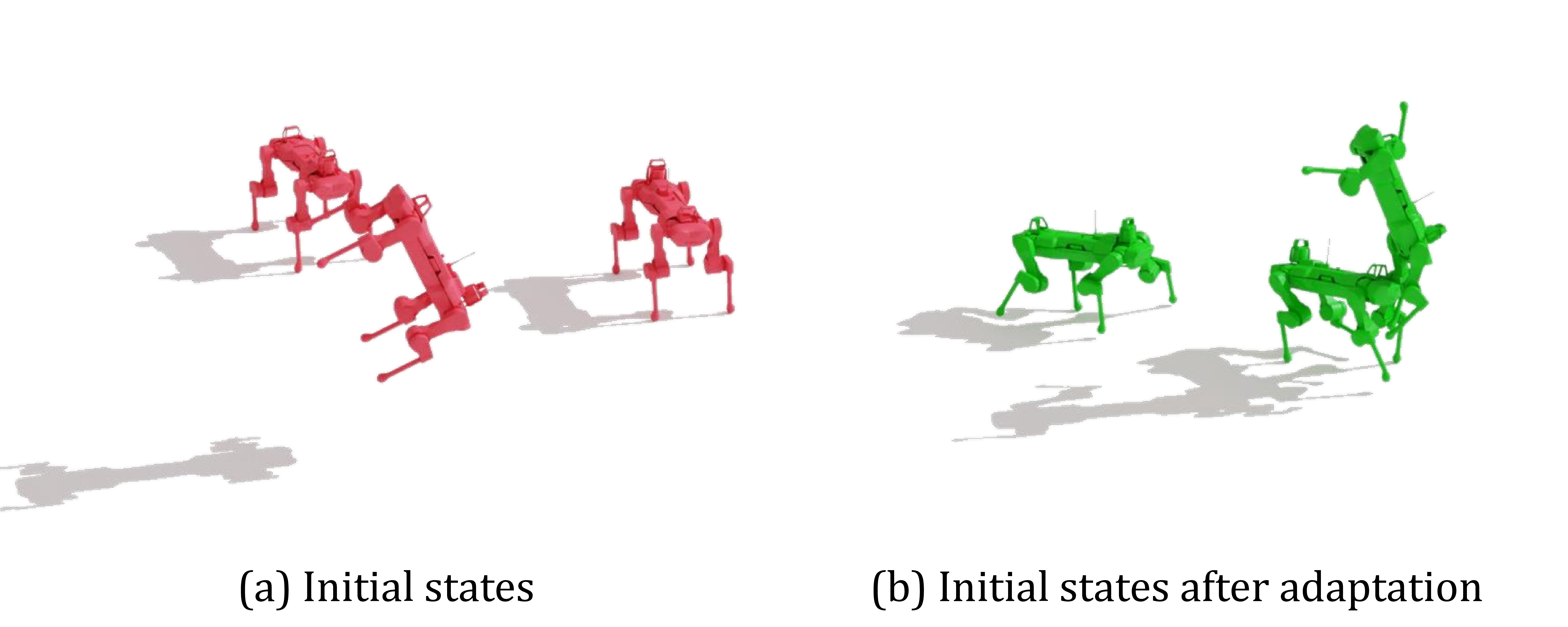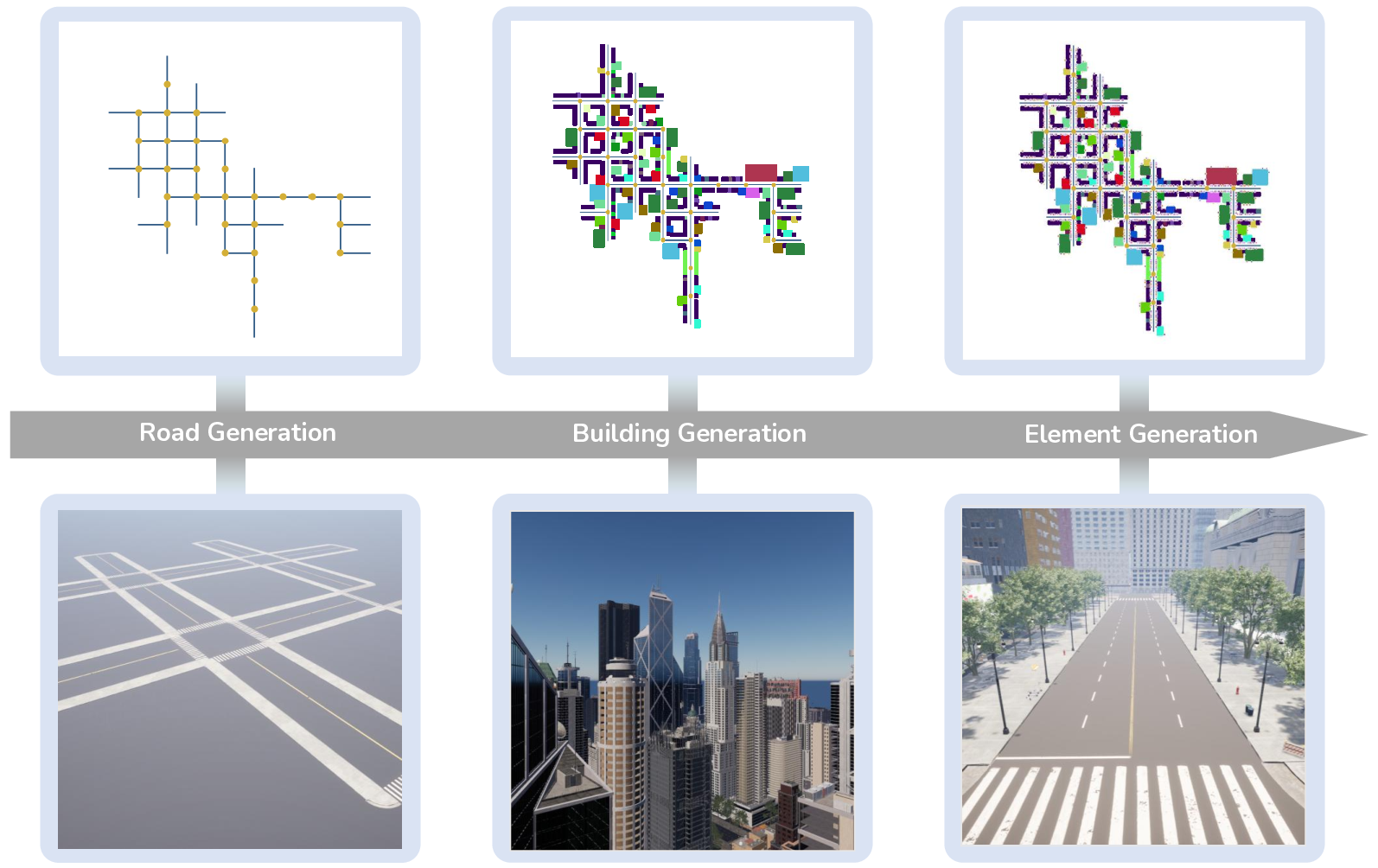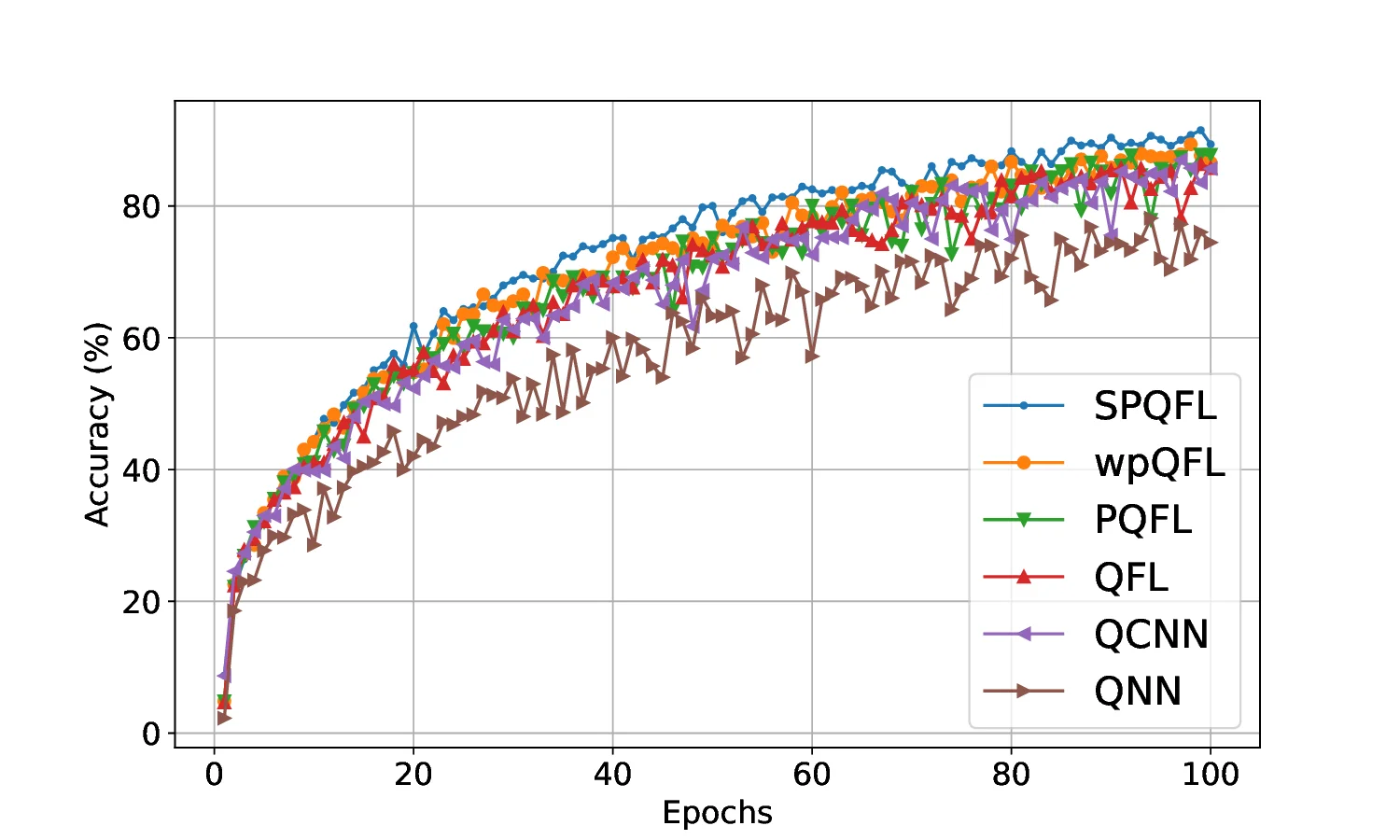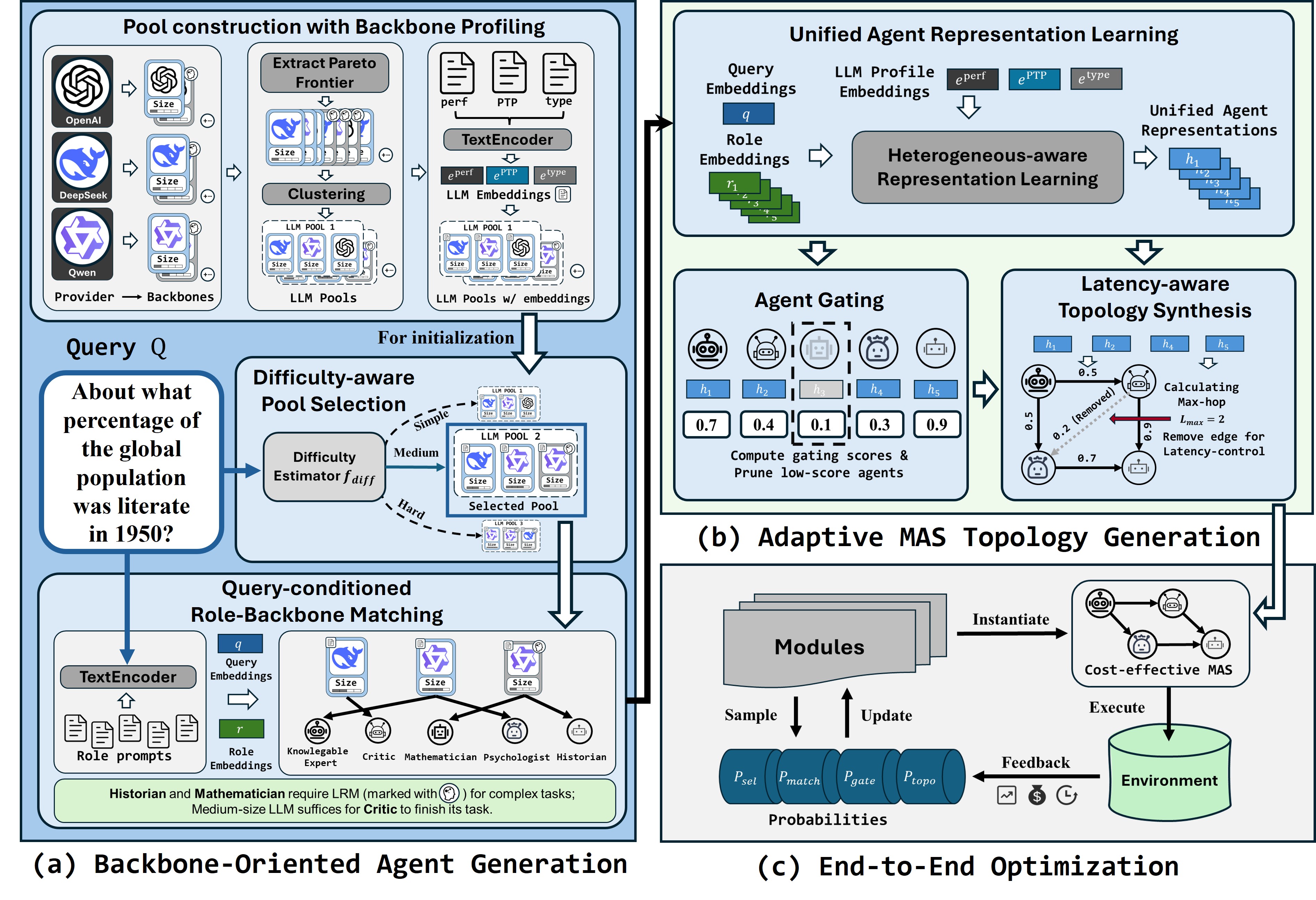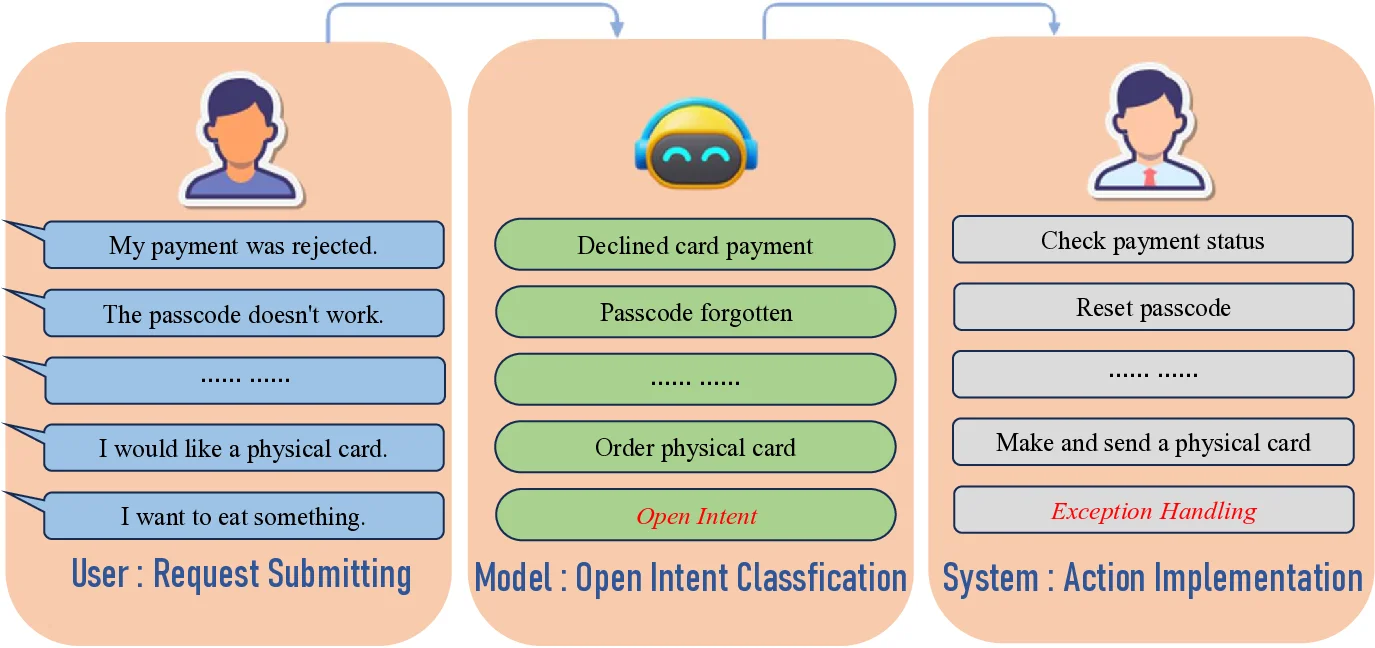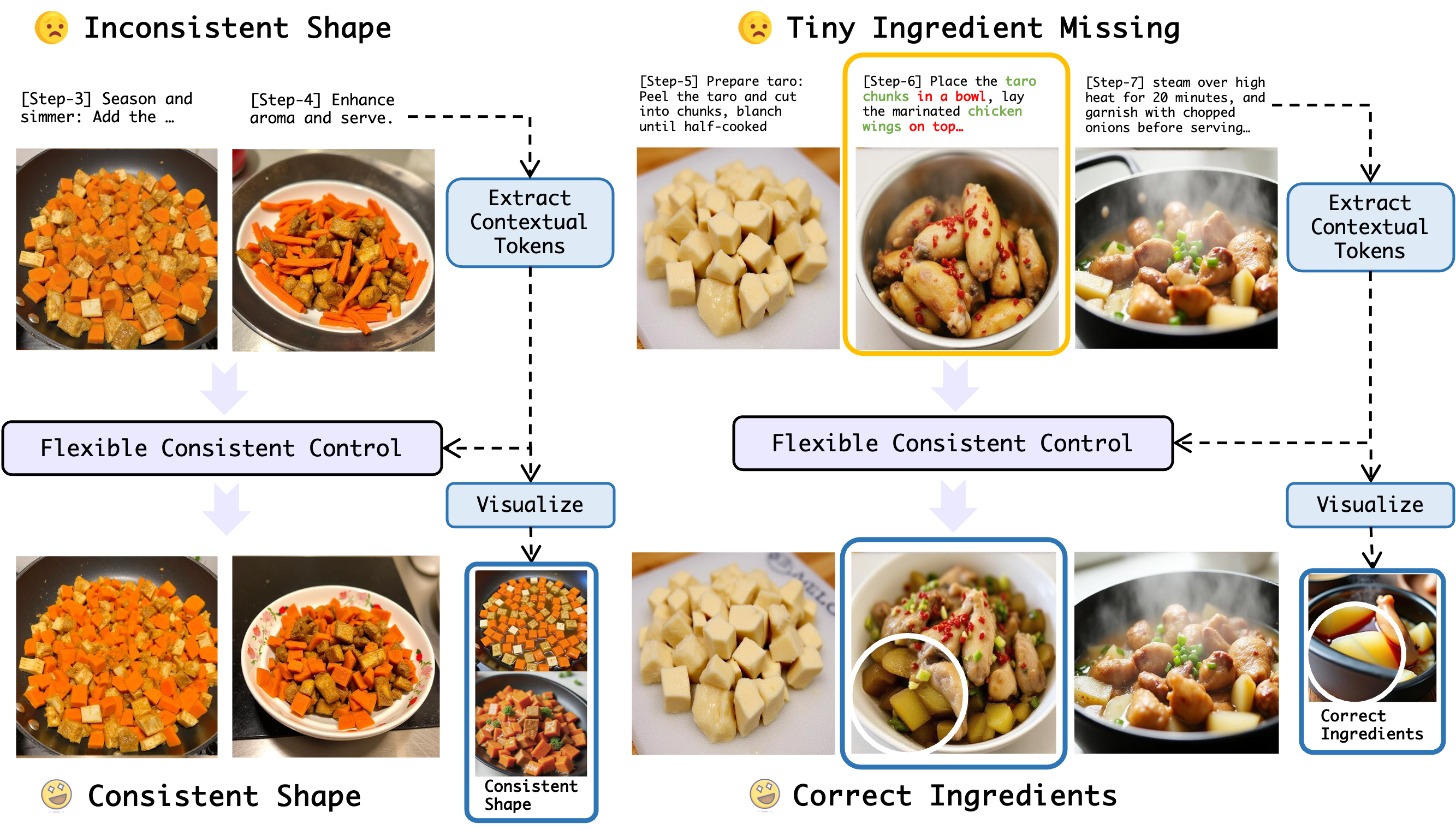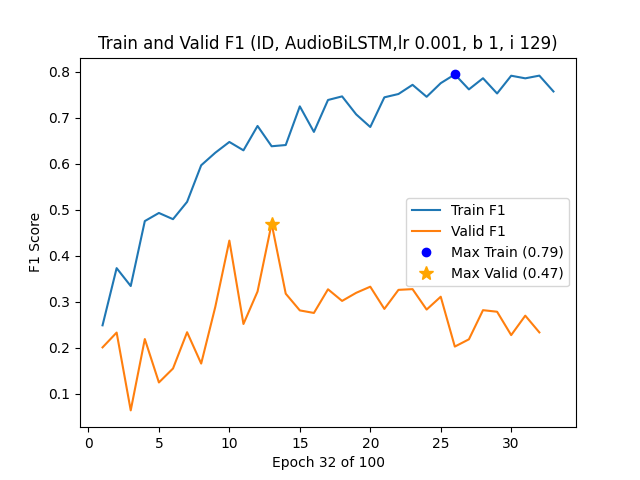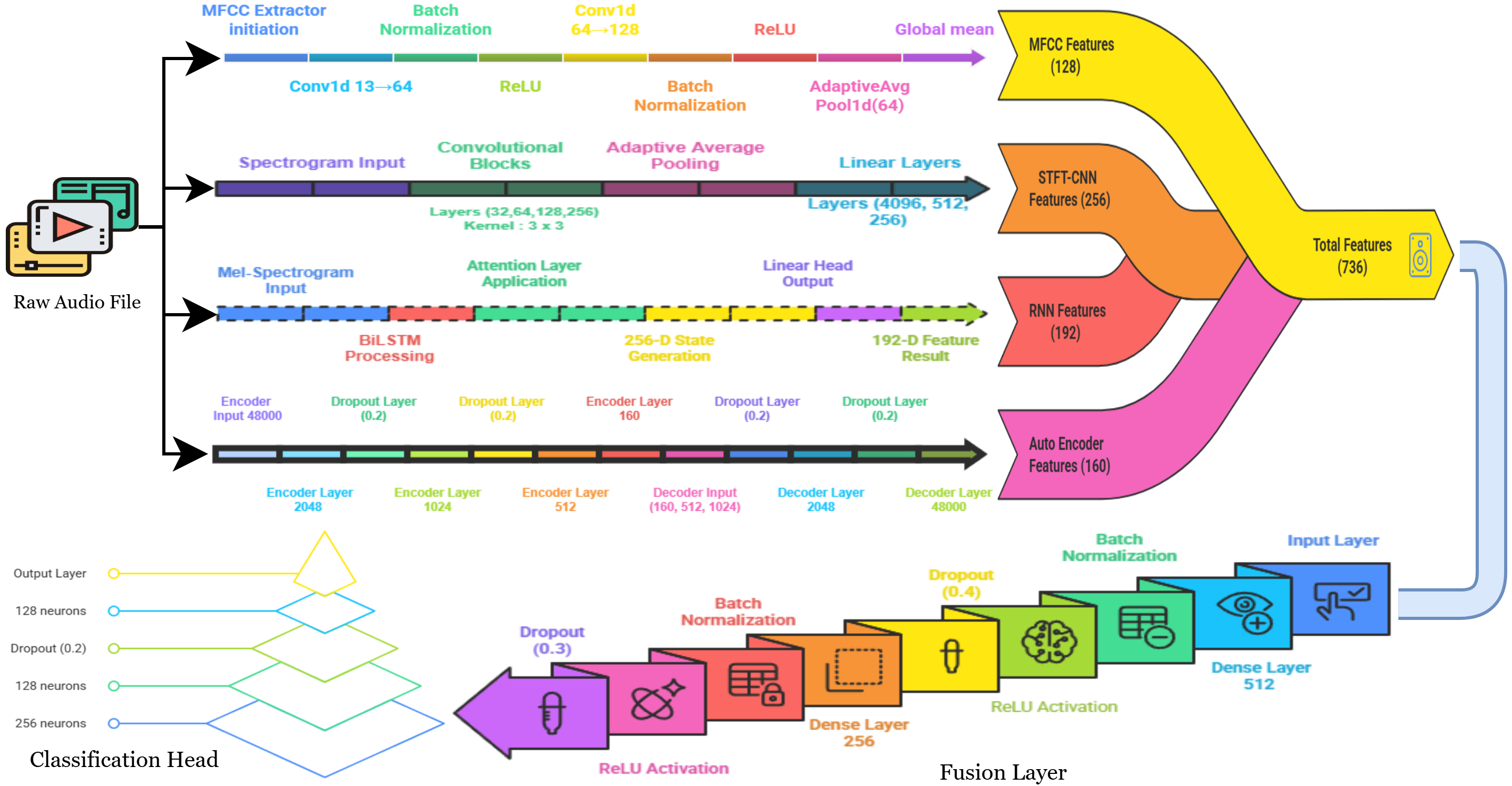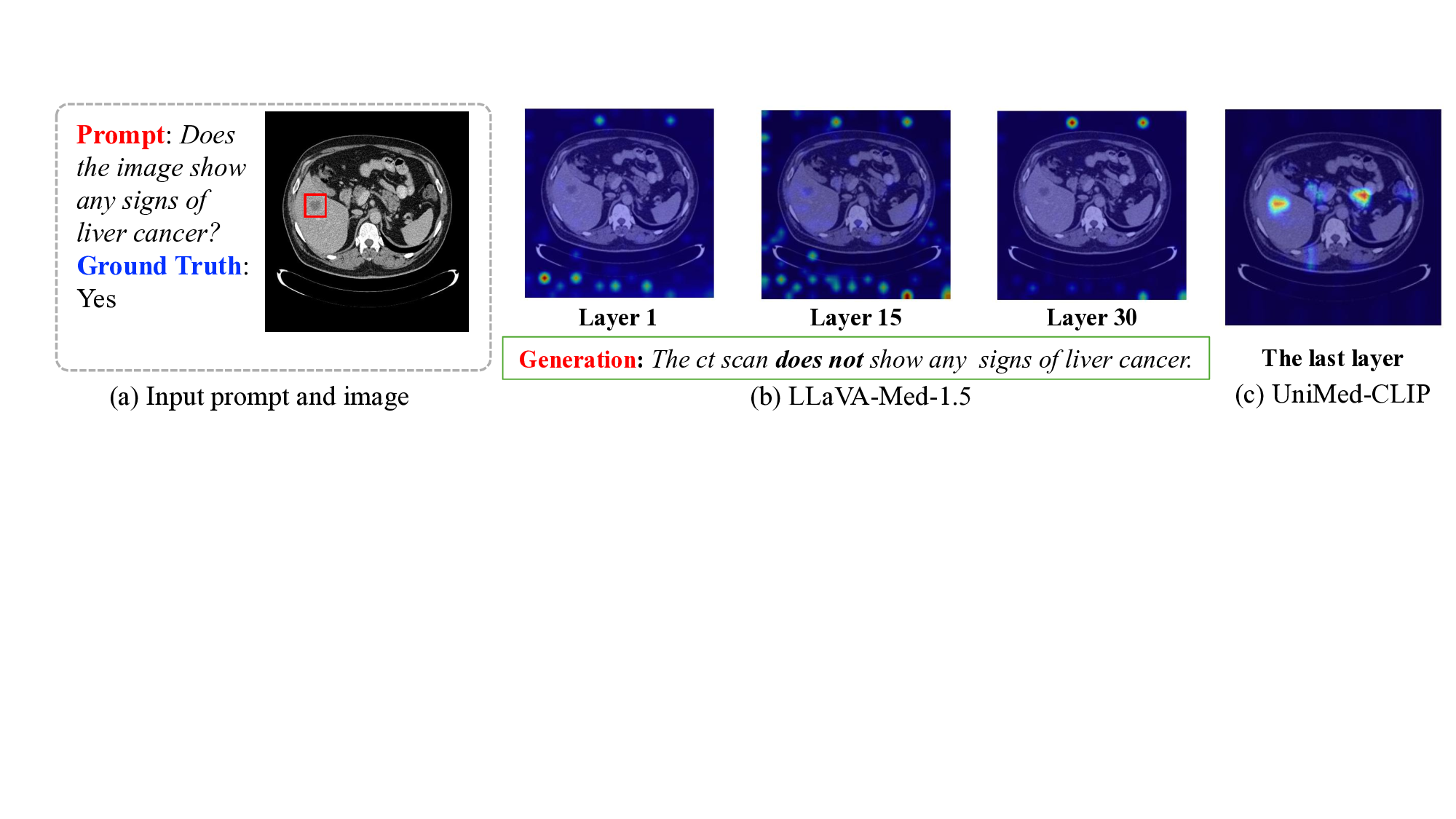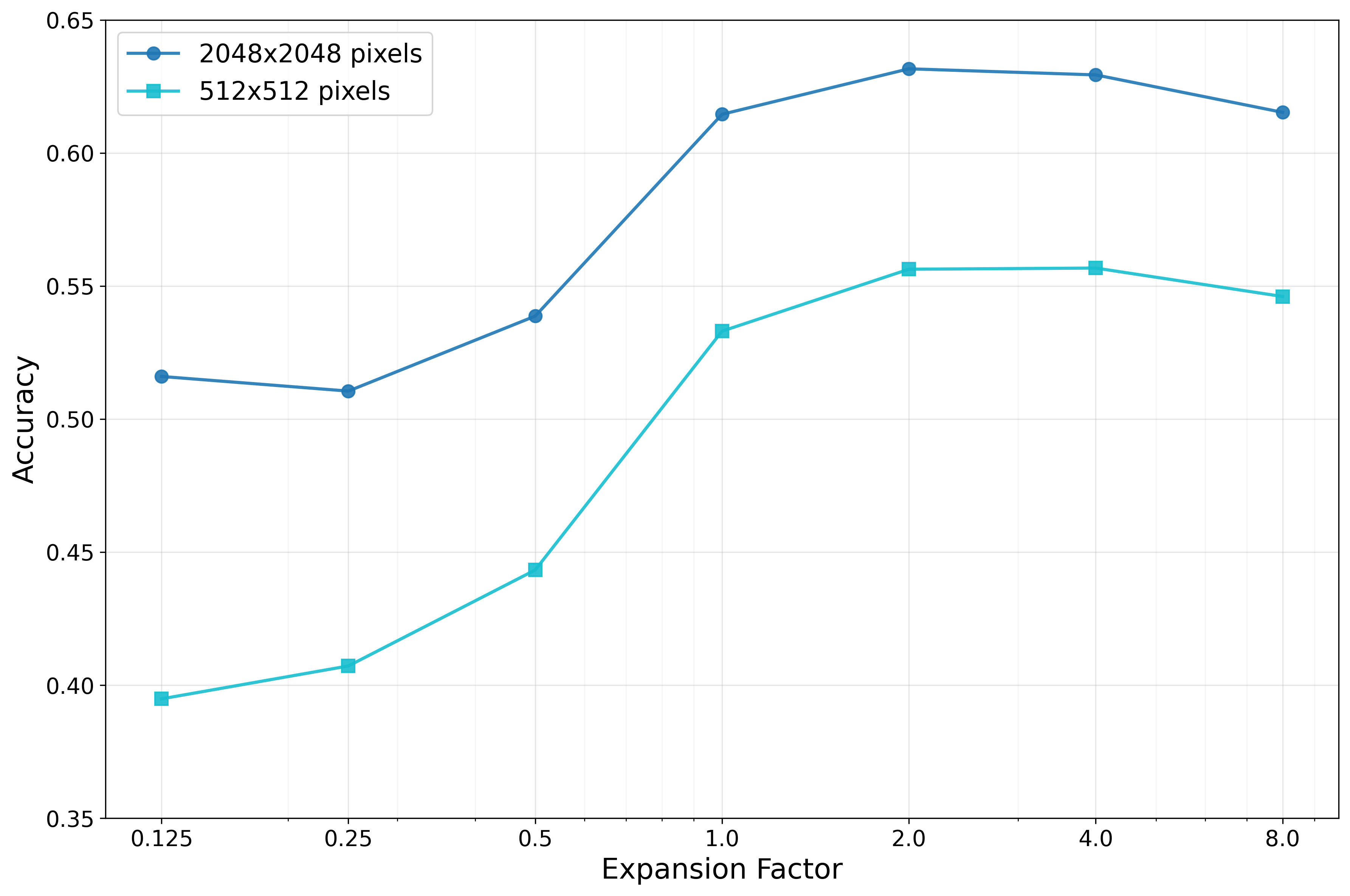
세밀한 이미지 이해를 위한 동적 확대 기법
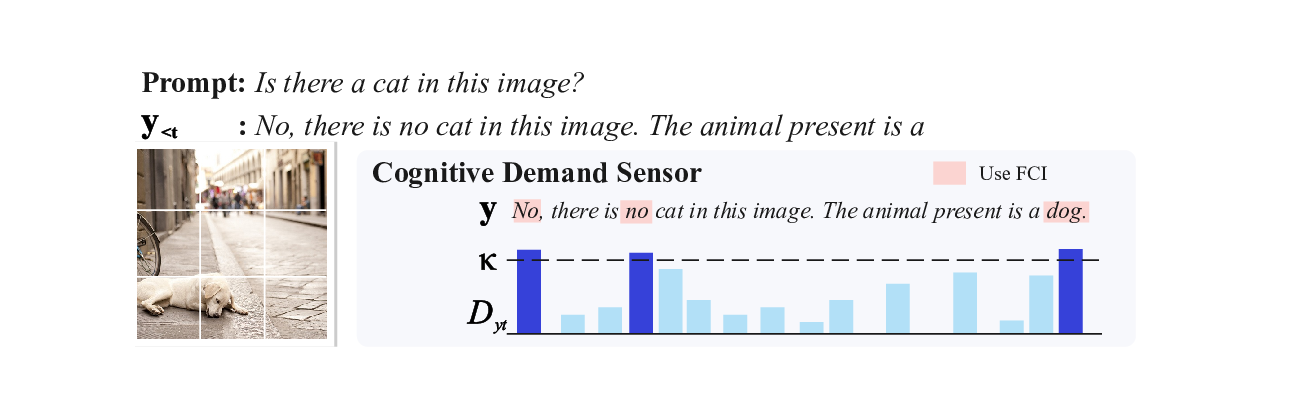
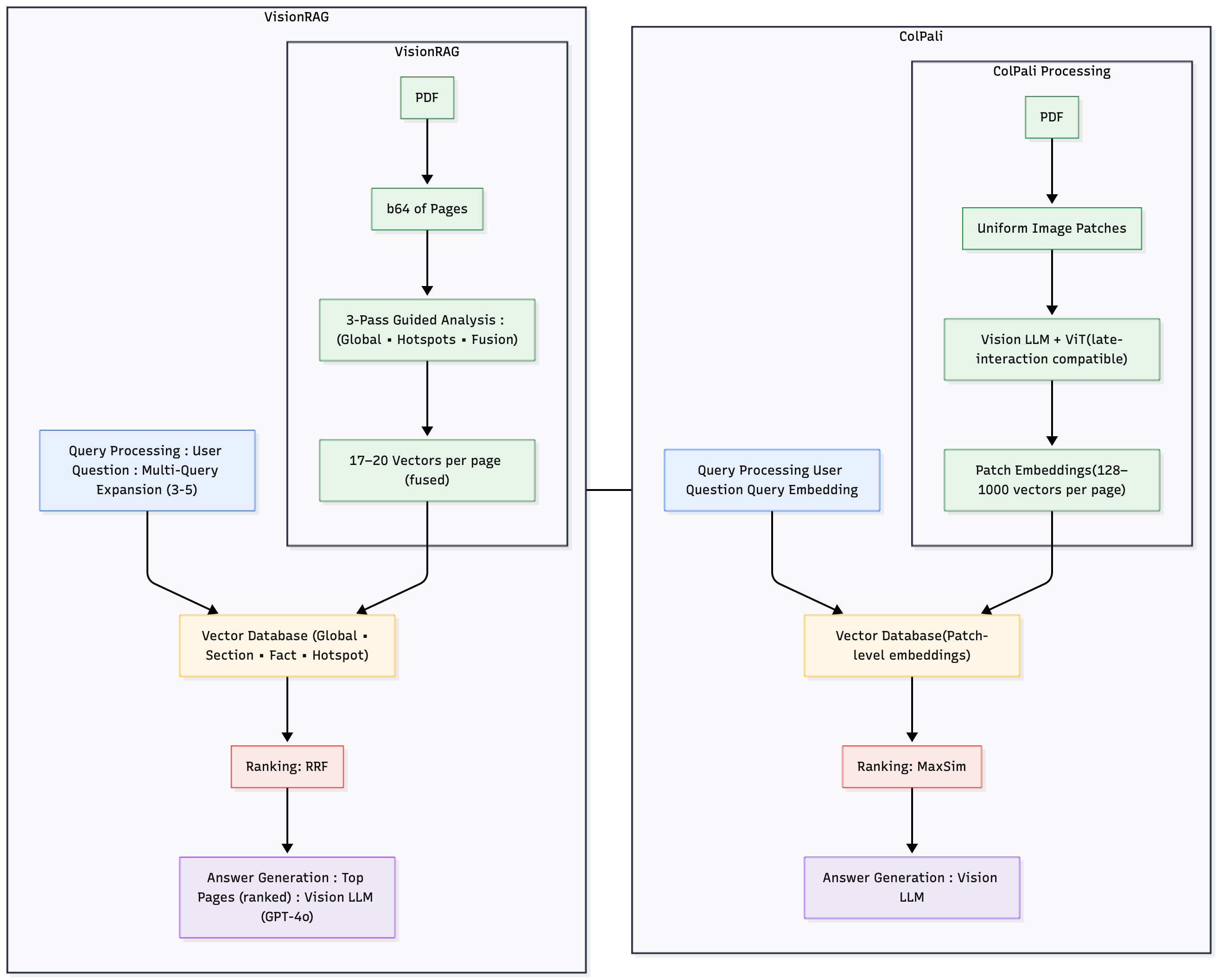
Vision-Language Models (VLMs) often struggle with tasks that require fine-grained image understanding, such as scene-text recognition or document analysis, due to perception limitations and visual fragmentation. To address these challenges, we introd