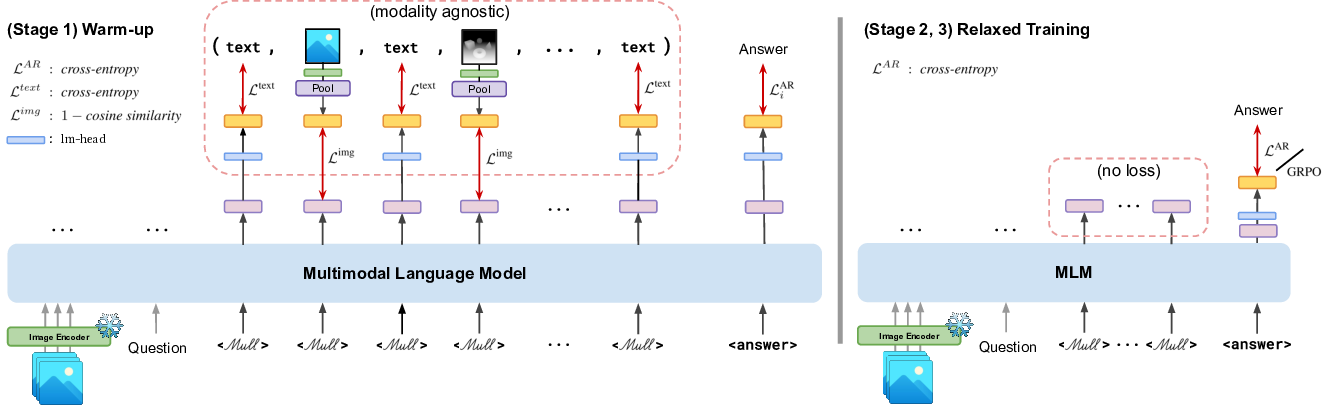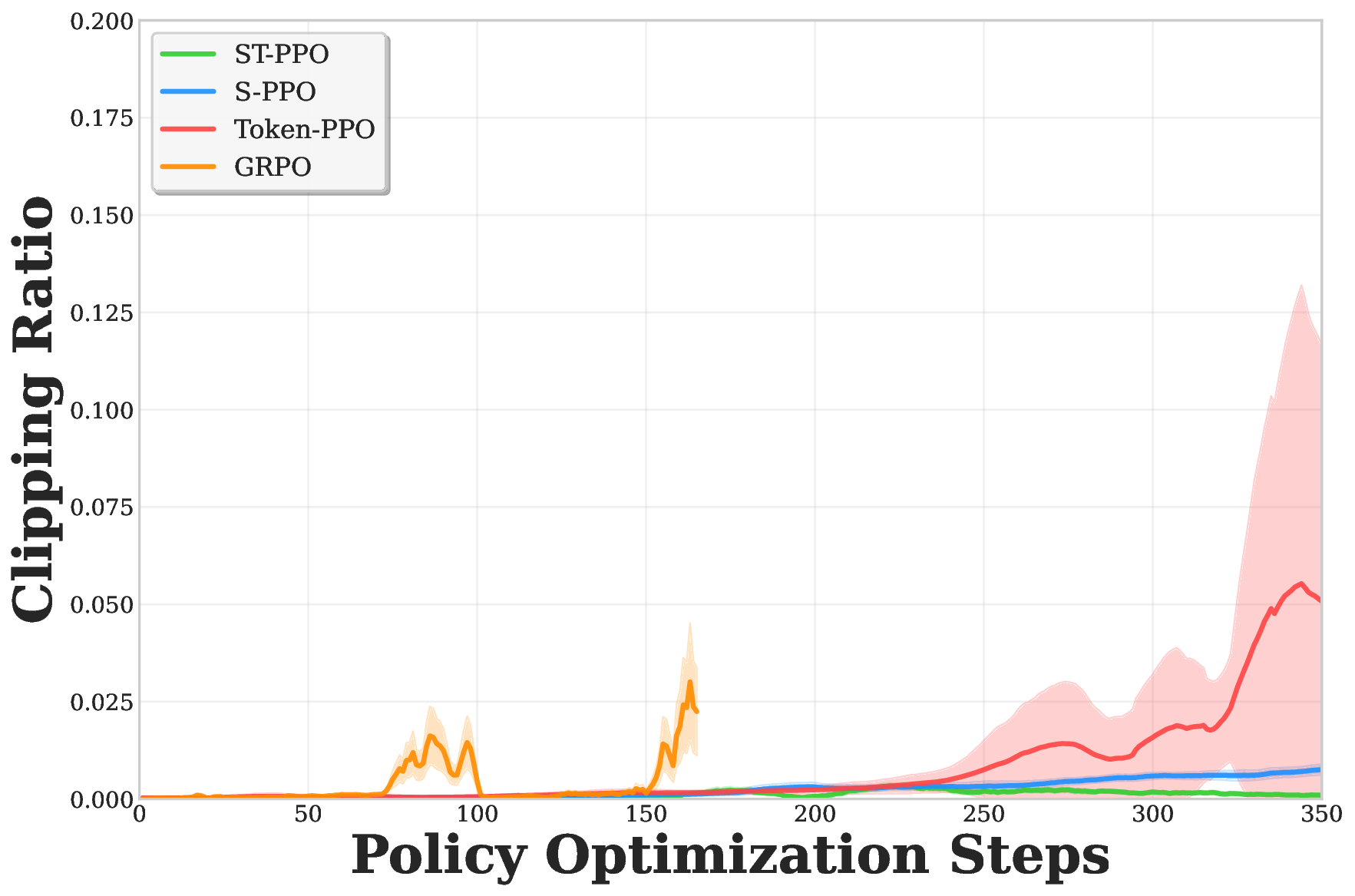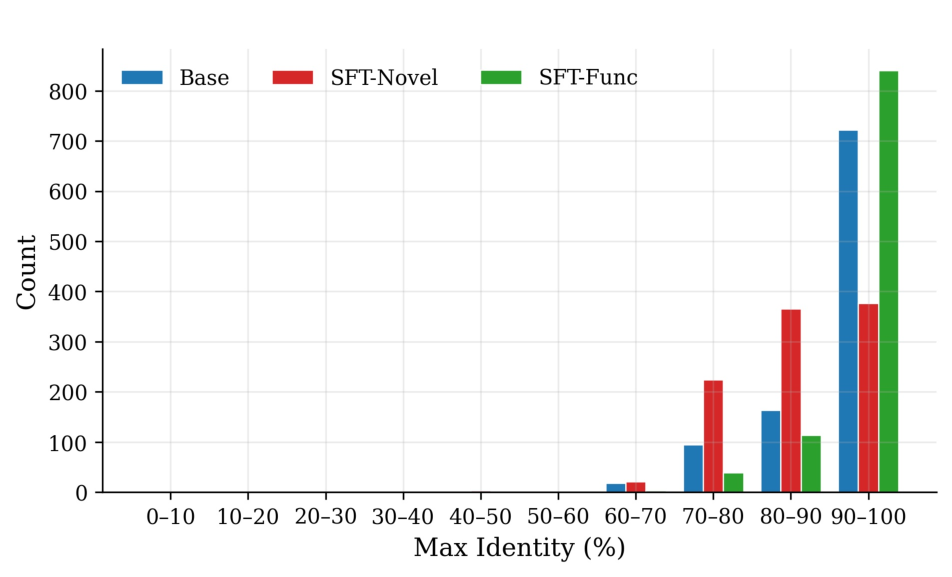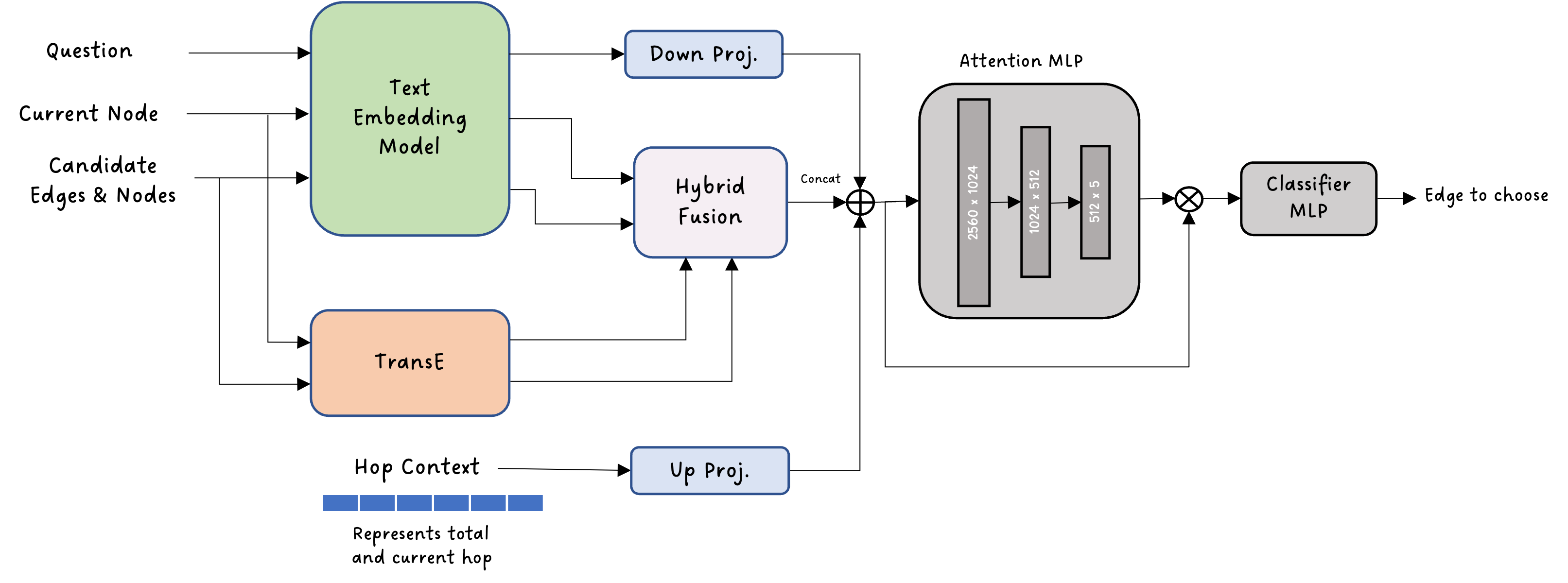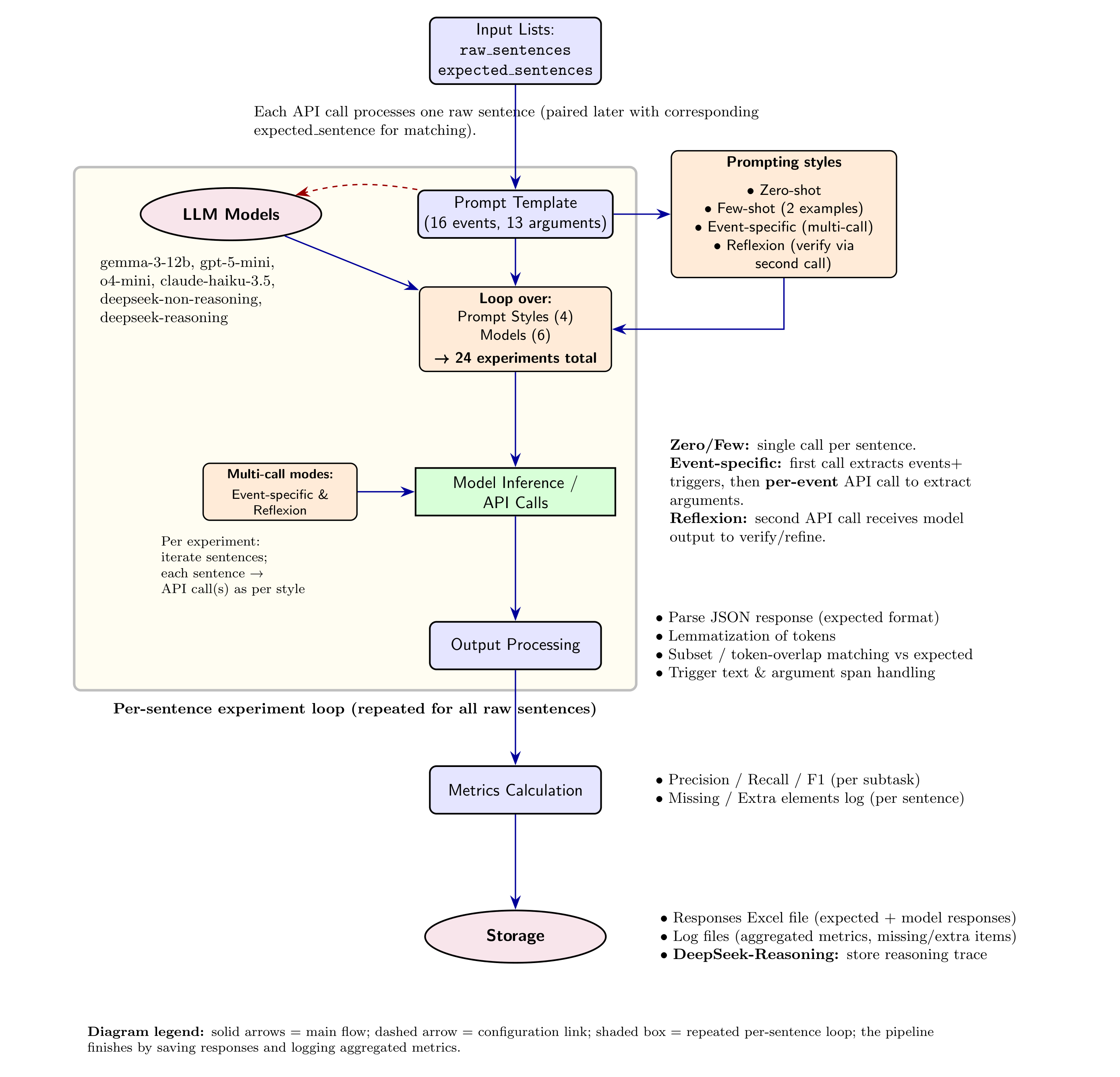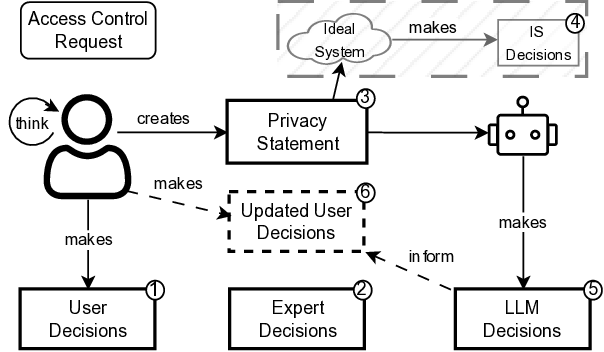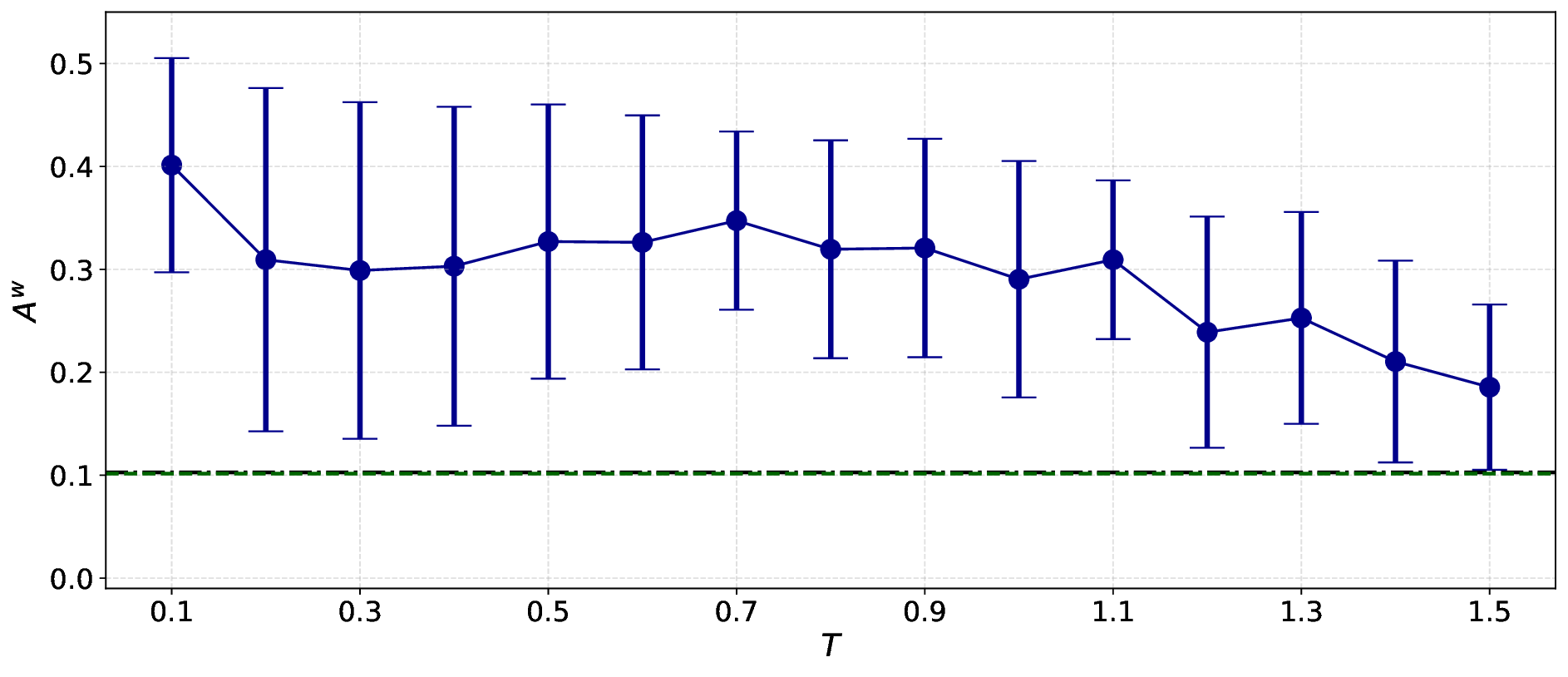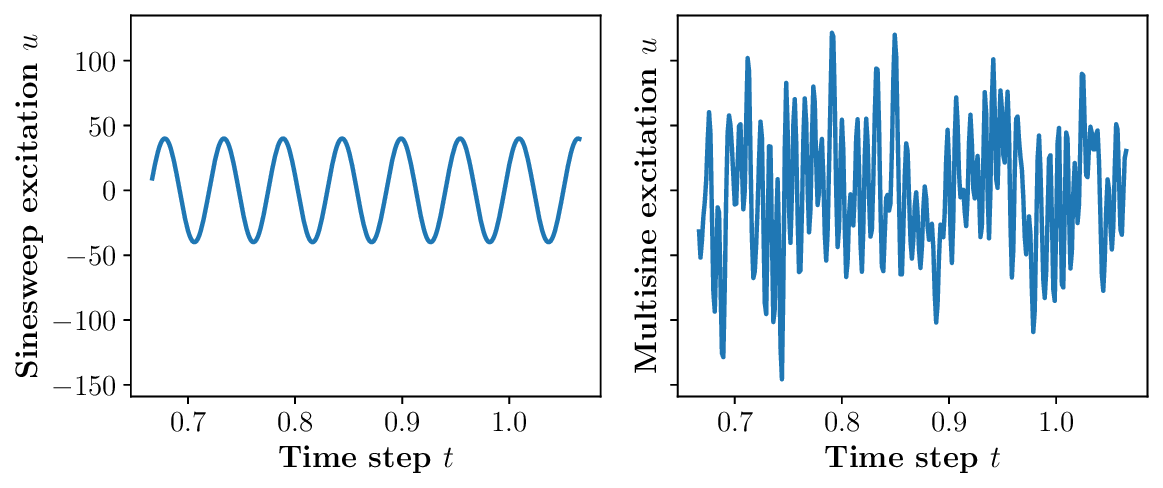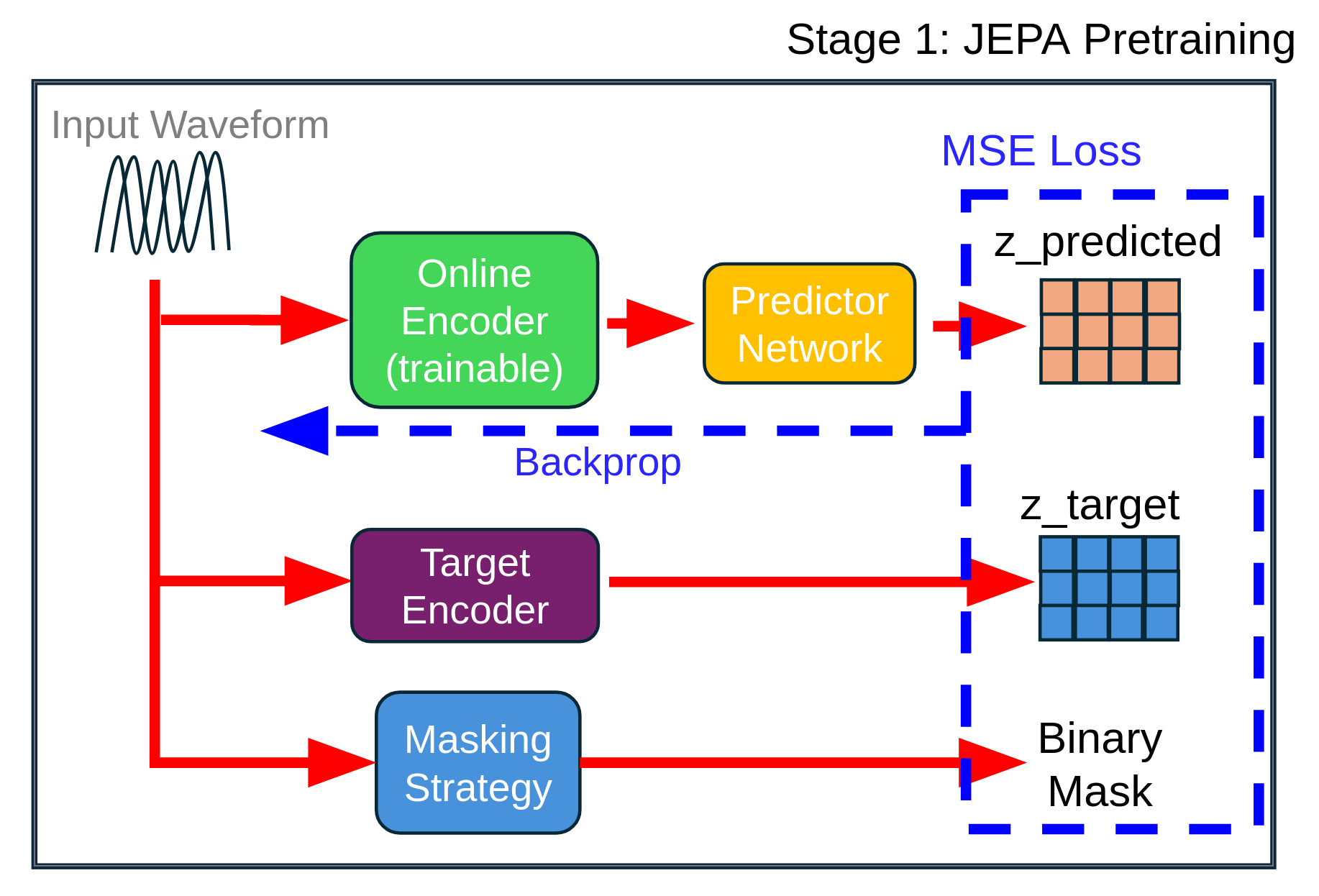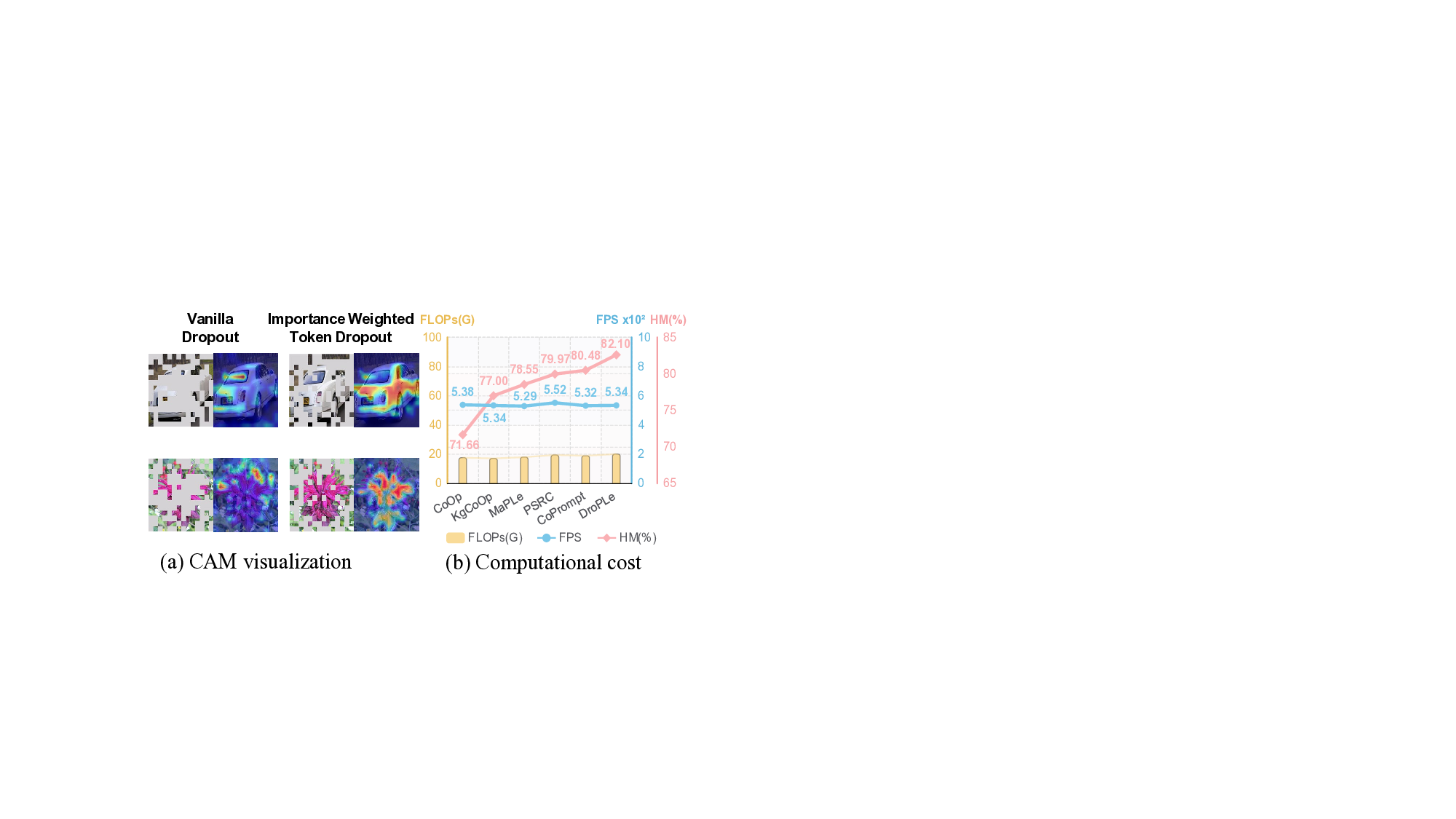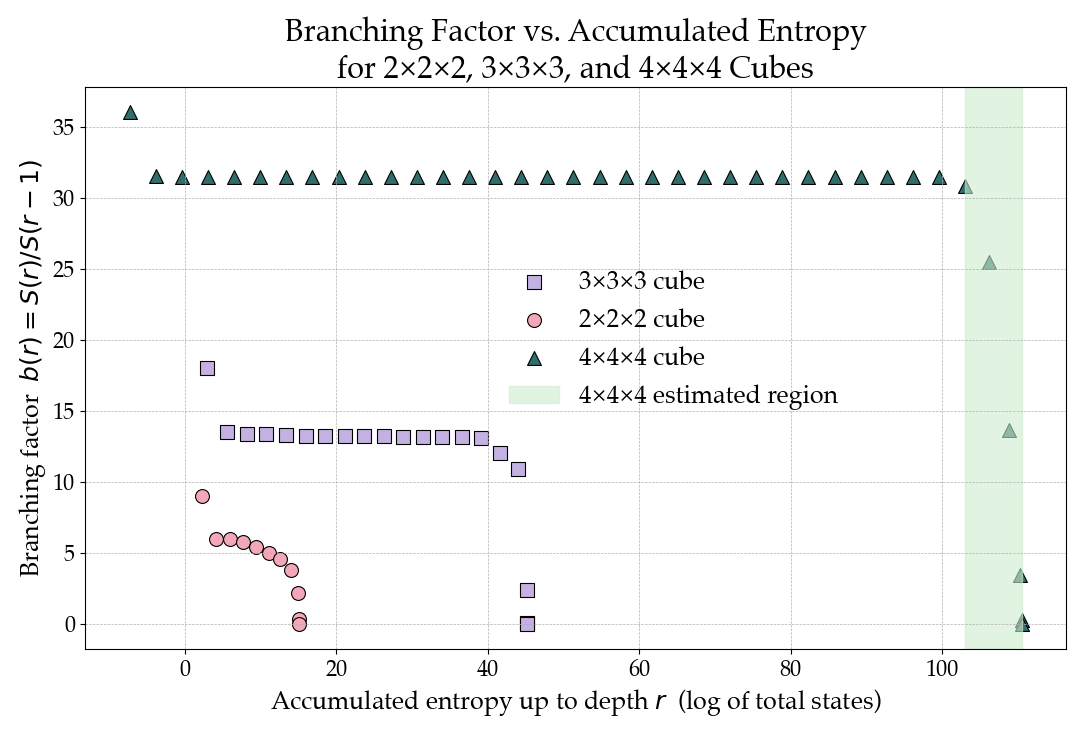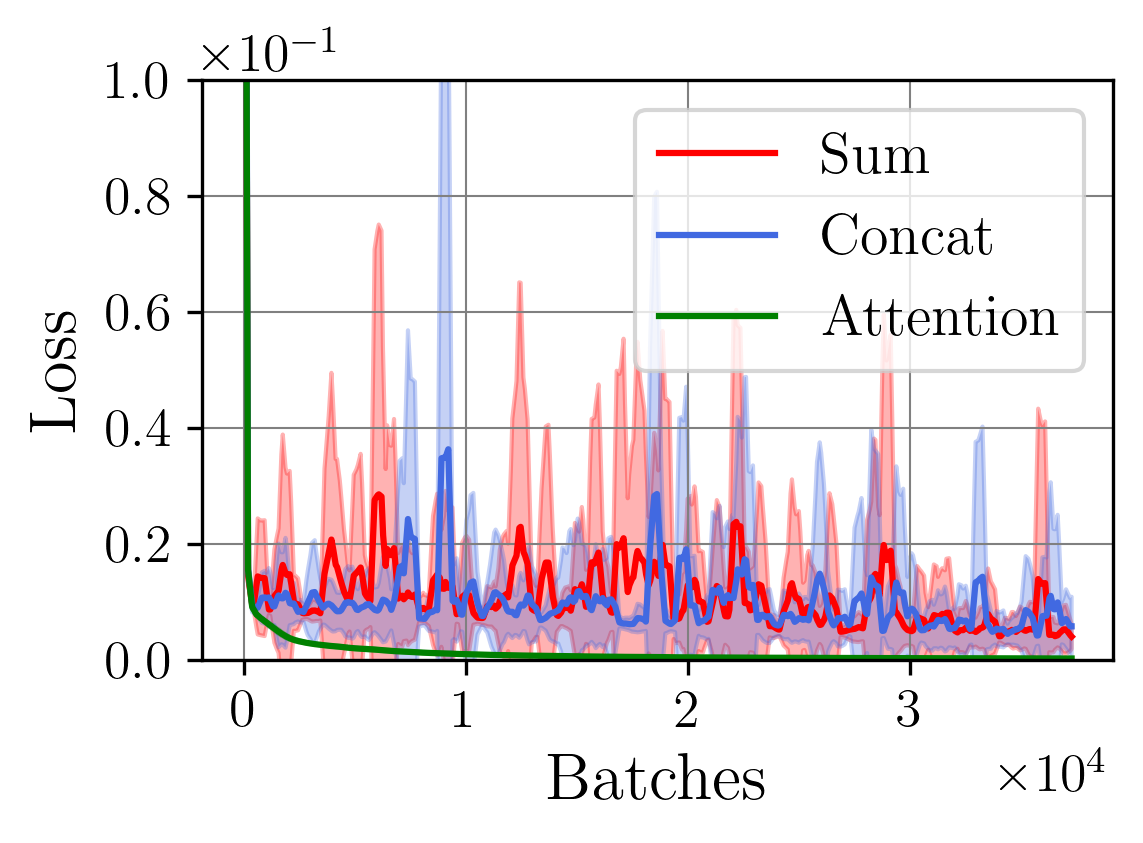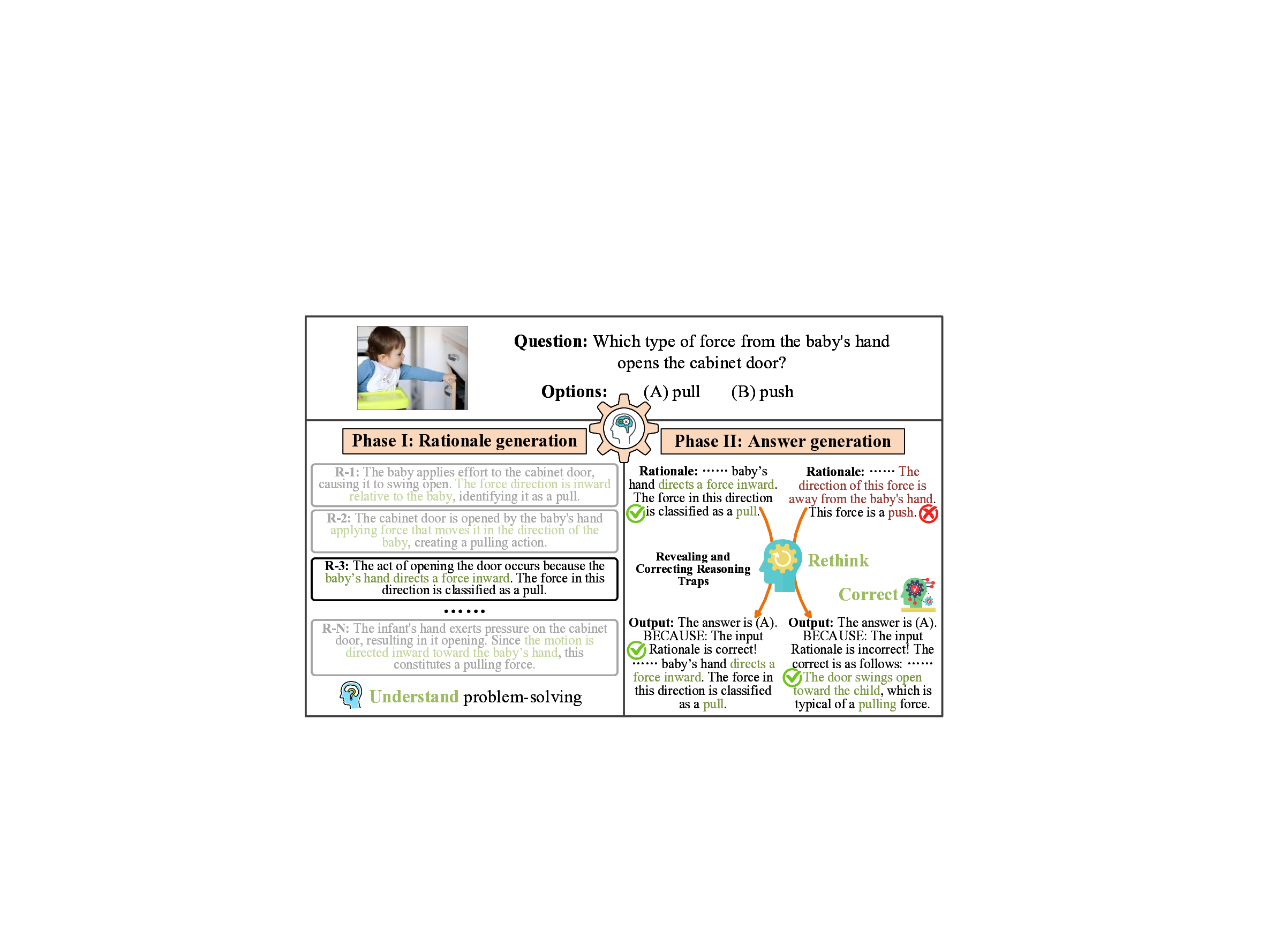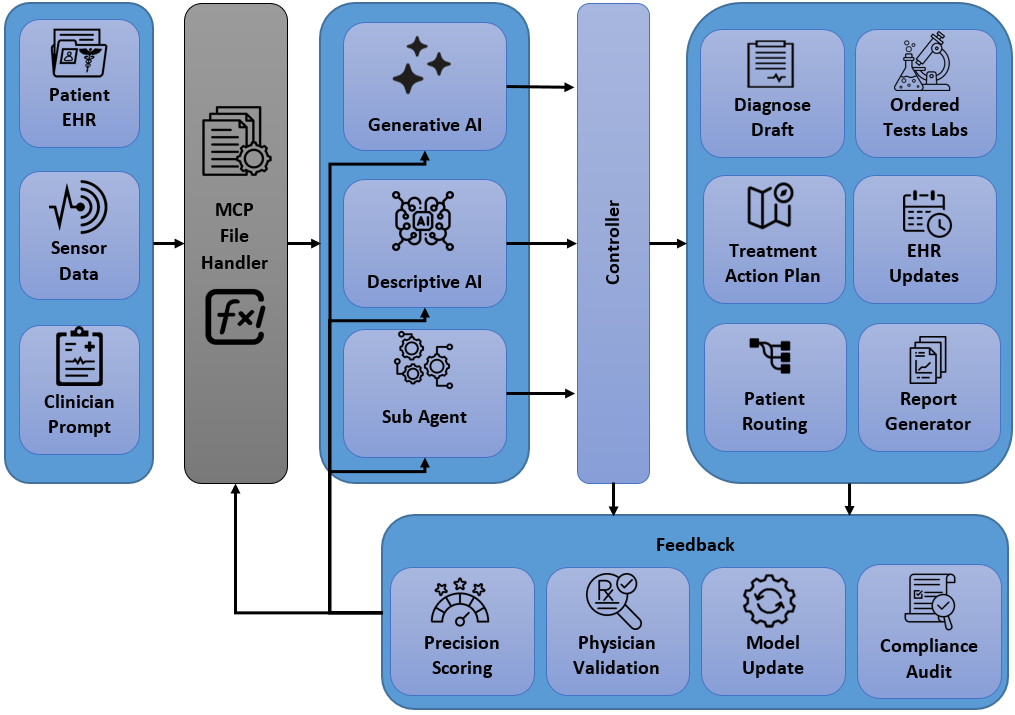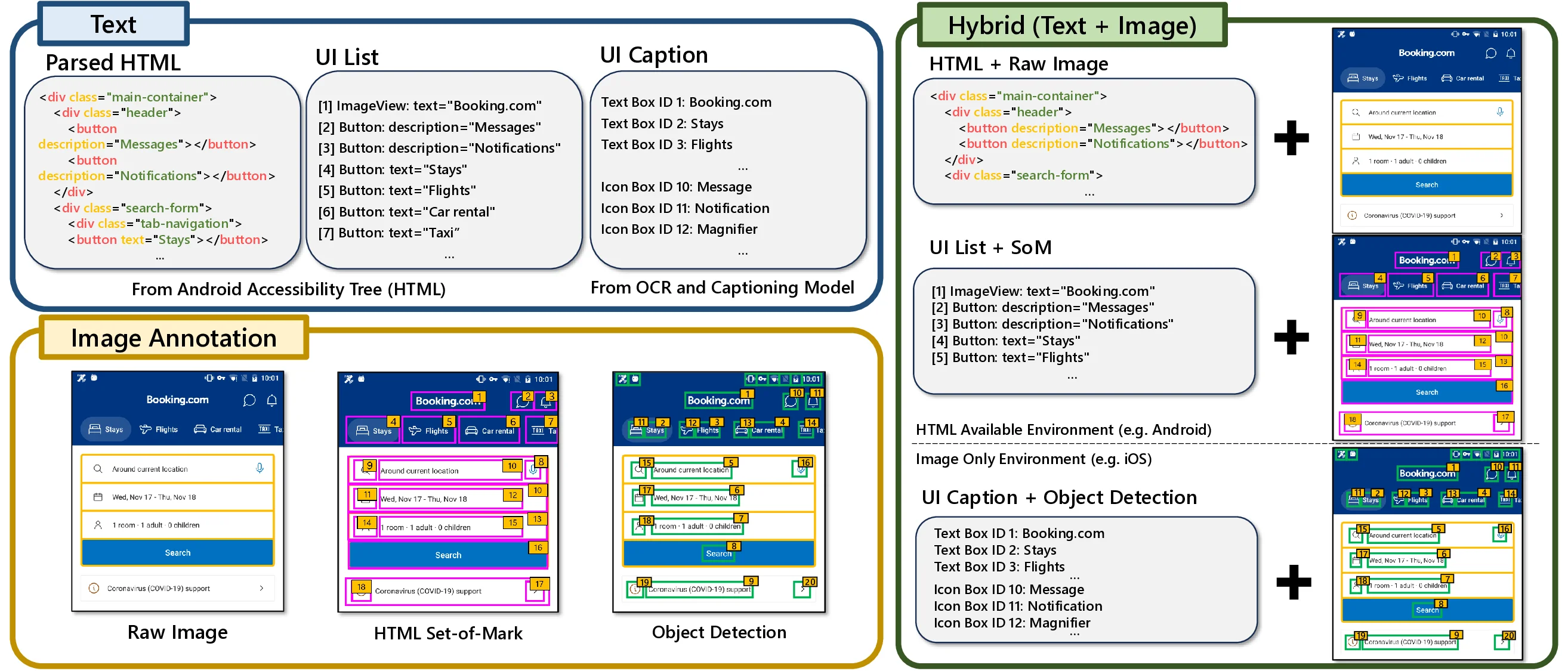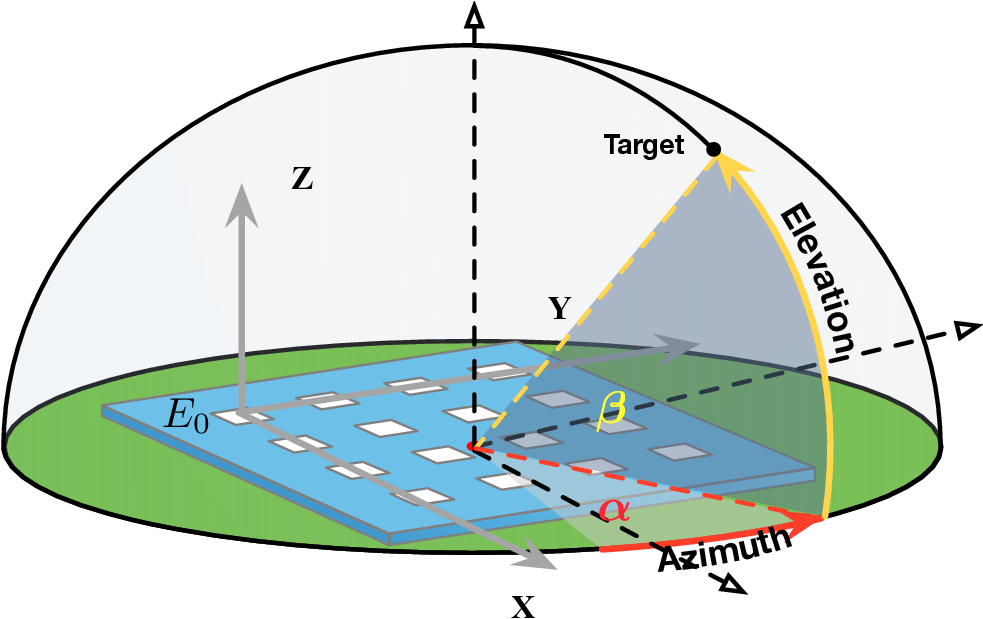
다중과제 상호작용 적대학습 기반 간 종양 영상 통합 분석 네트워크
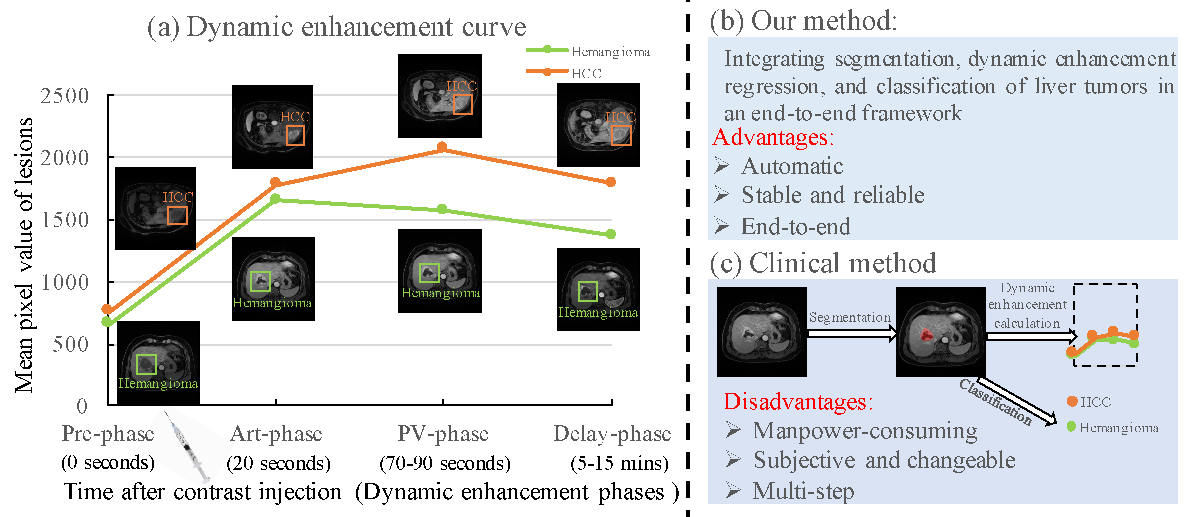
Liver tumor segmentation, dynamic enhancement regression, and classification are critical for clinical assessment and diagnosis. However, no prior work has attempted to achieve these tasks simultaneously in an end-to-end framework, primarily due to t