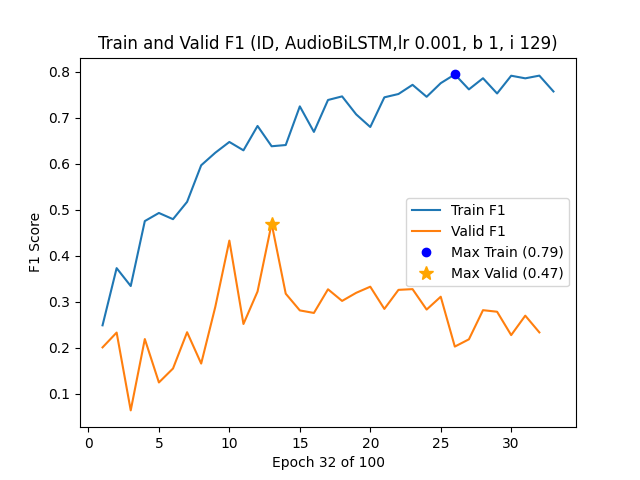
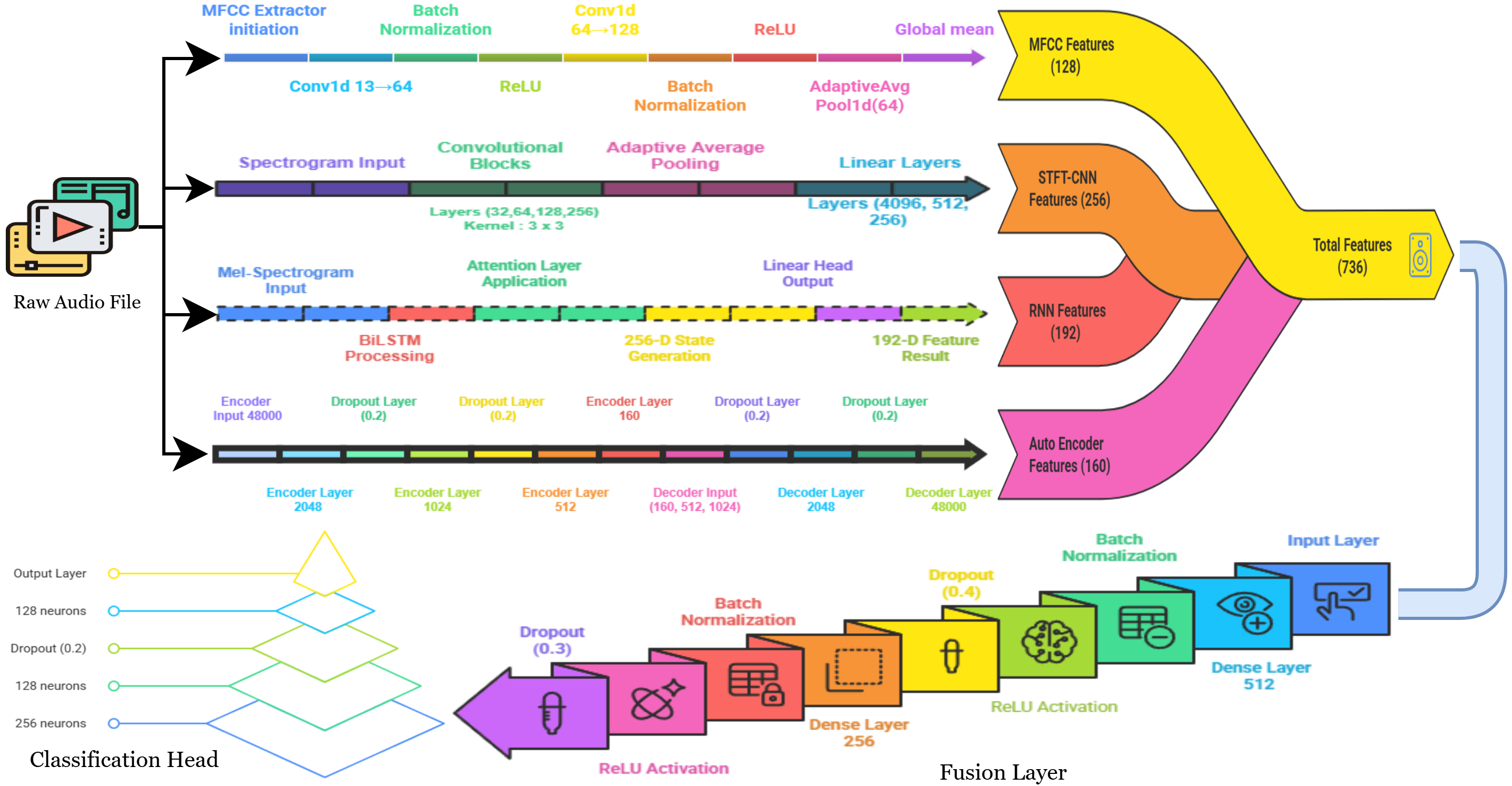
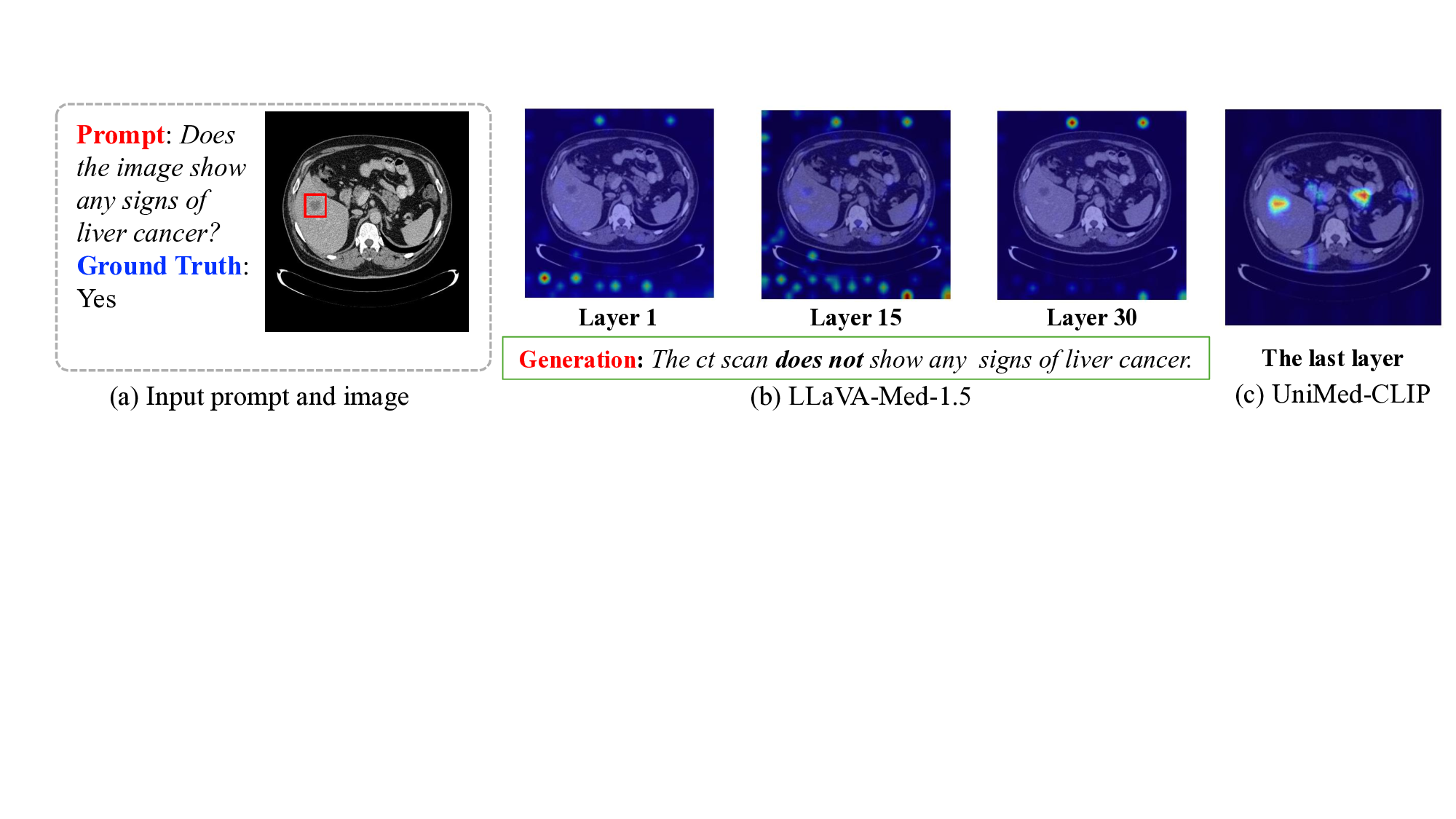
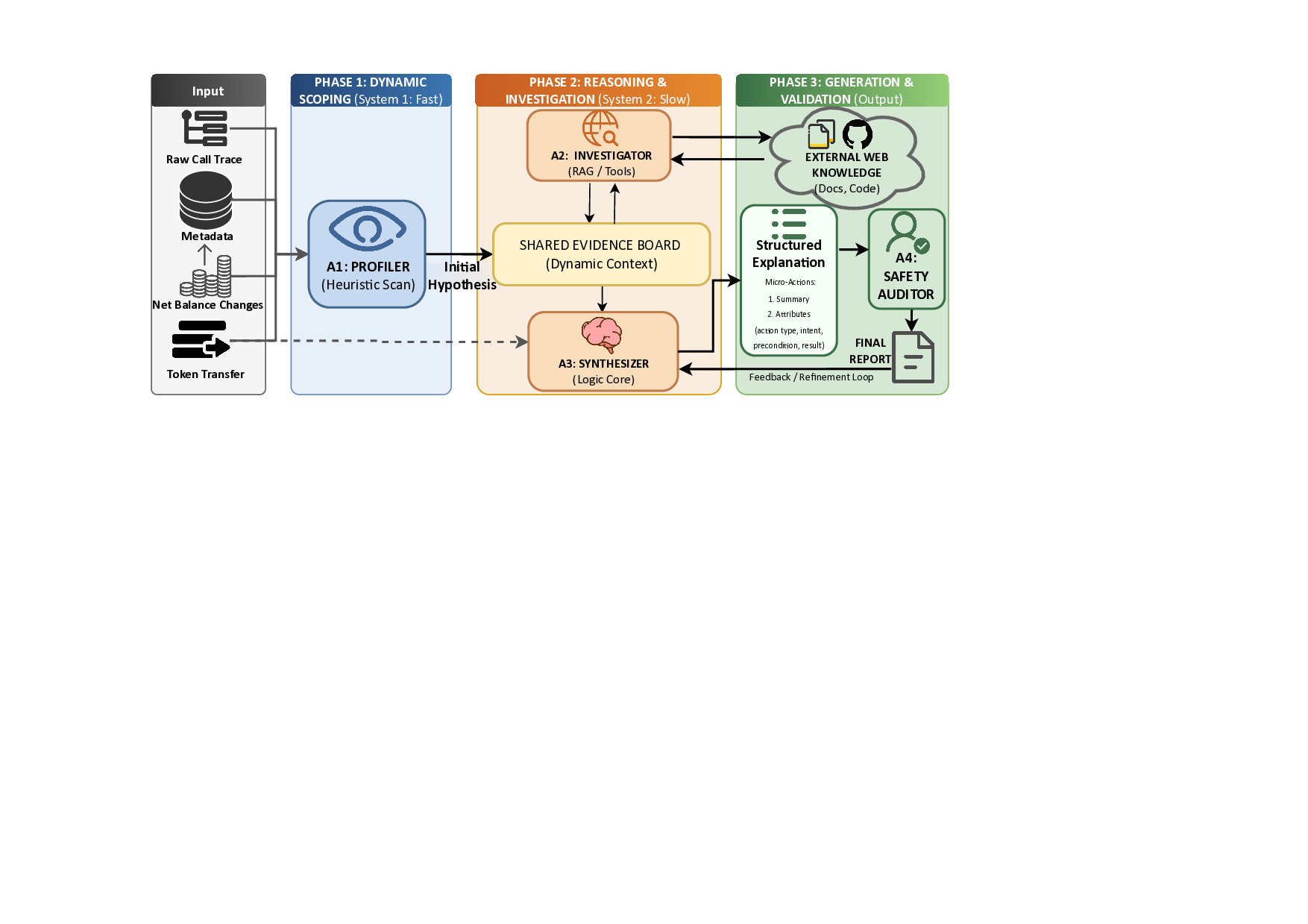
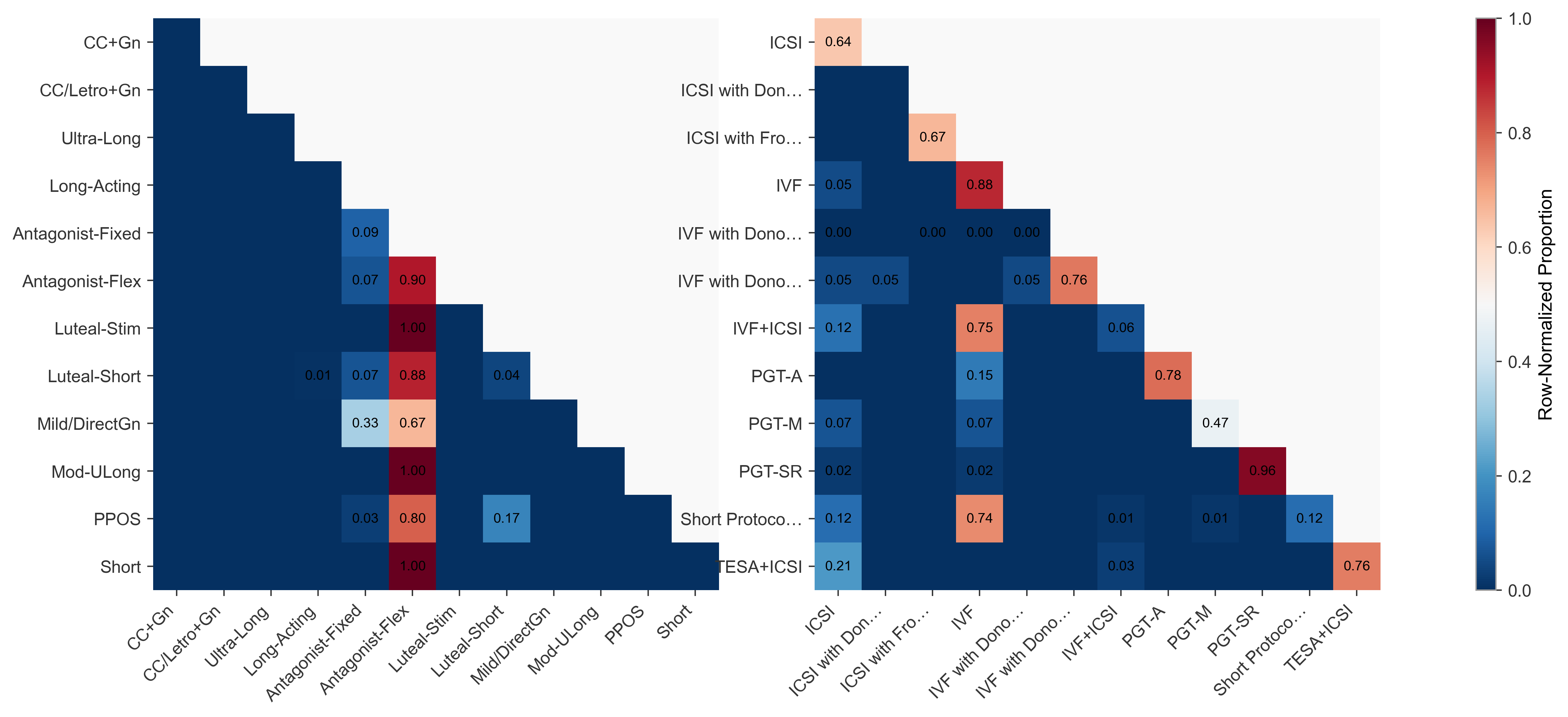
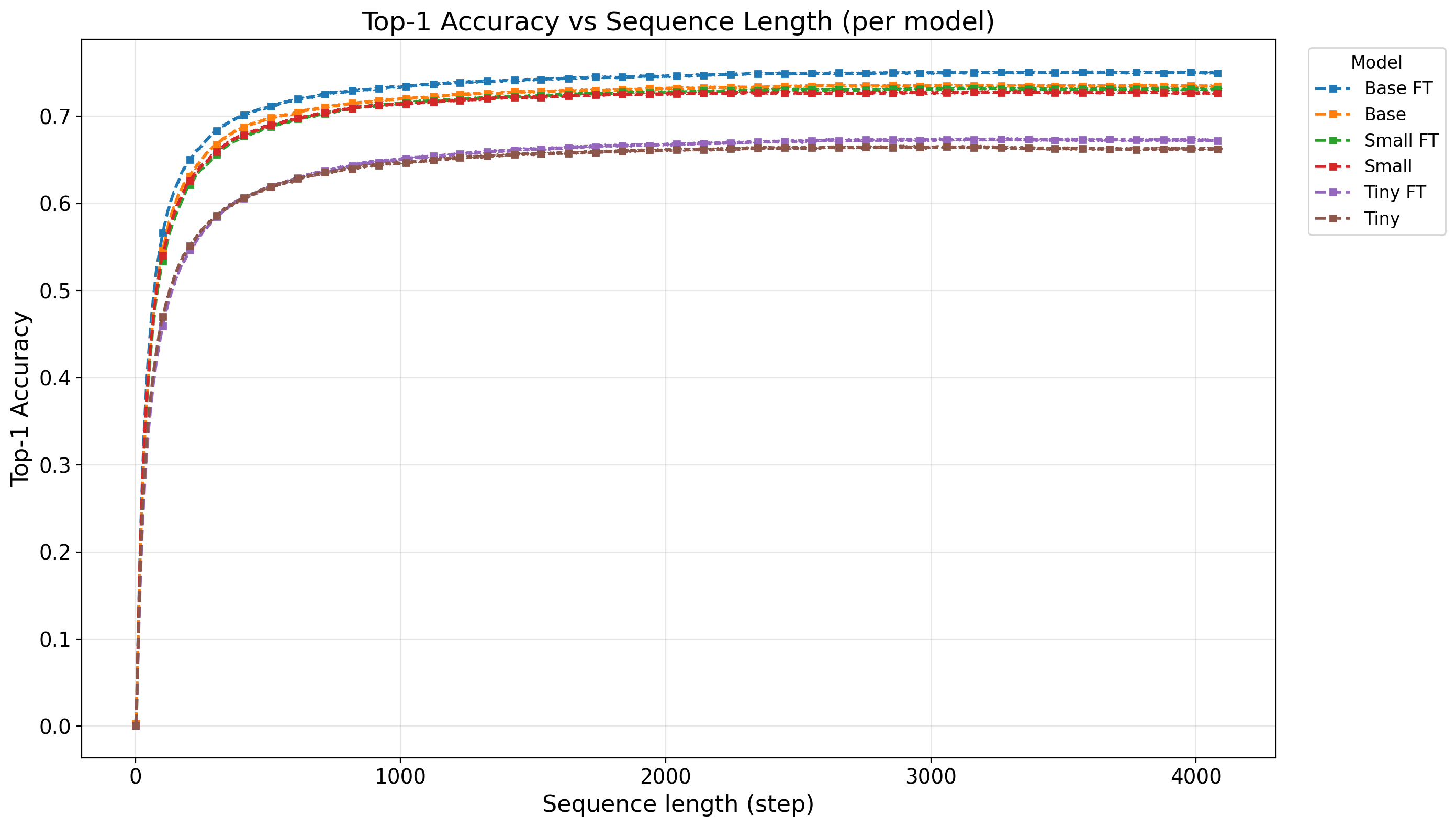
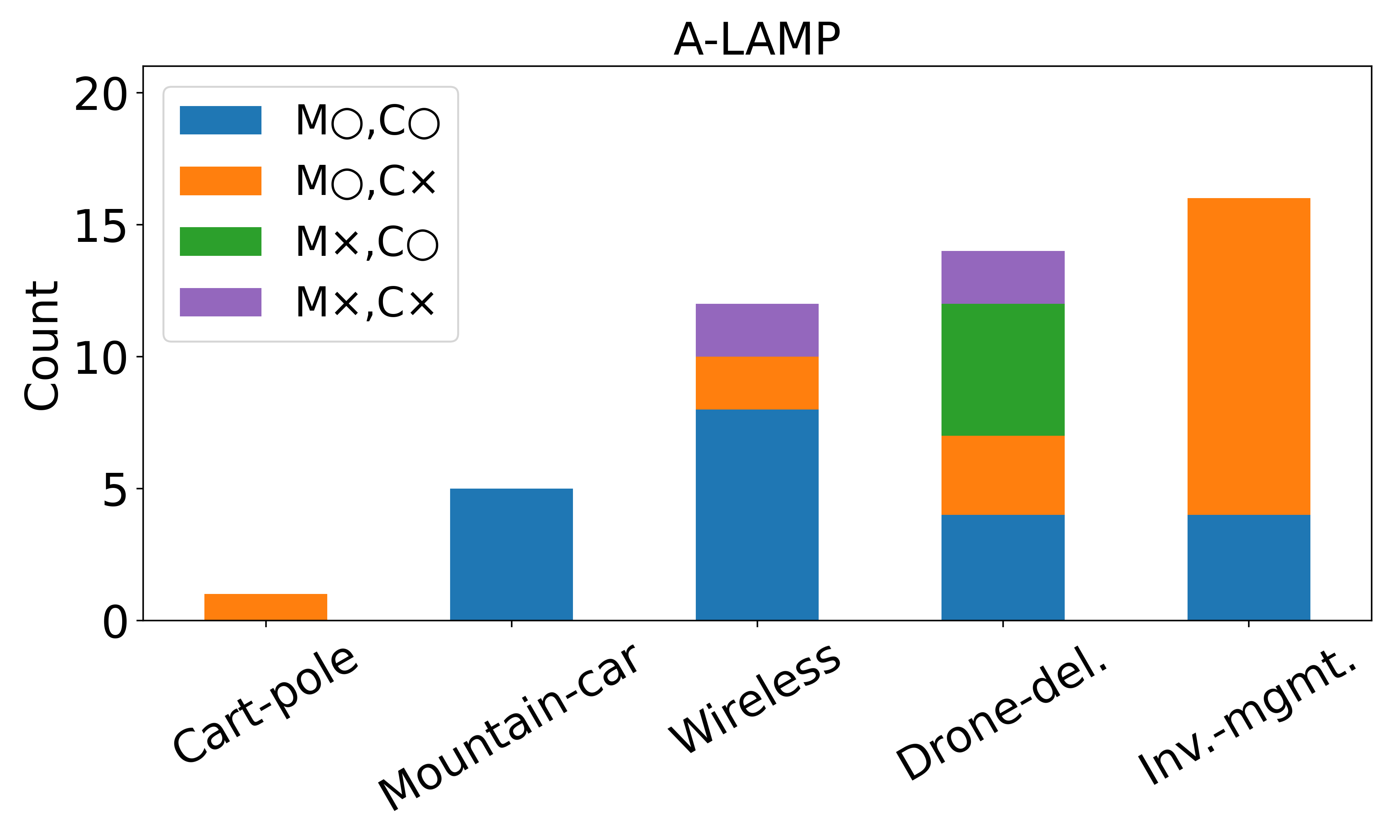
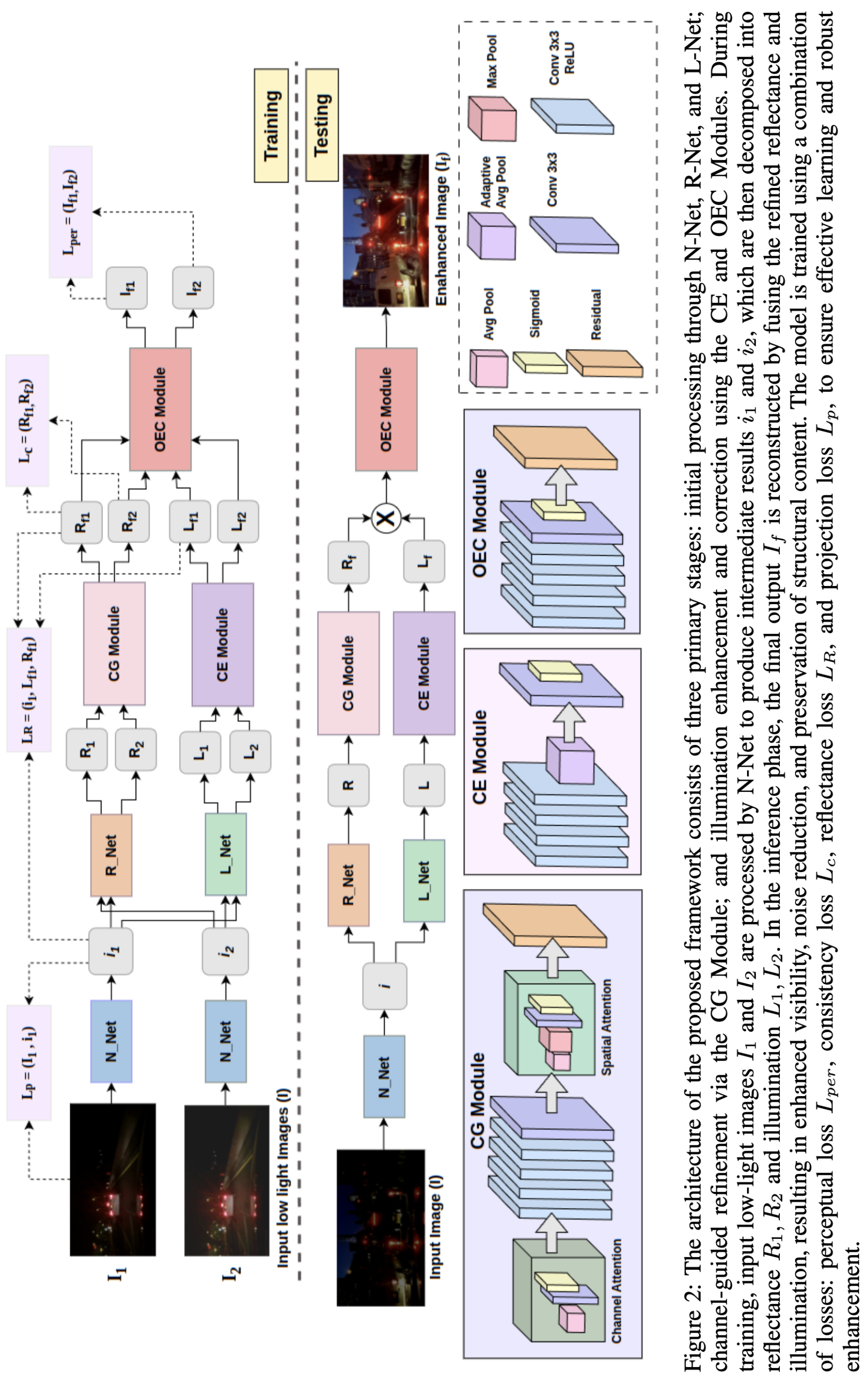
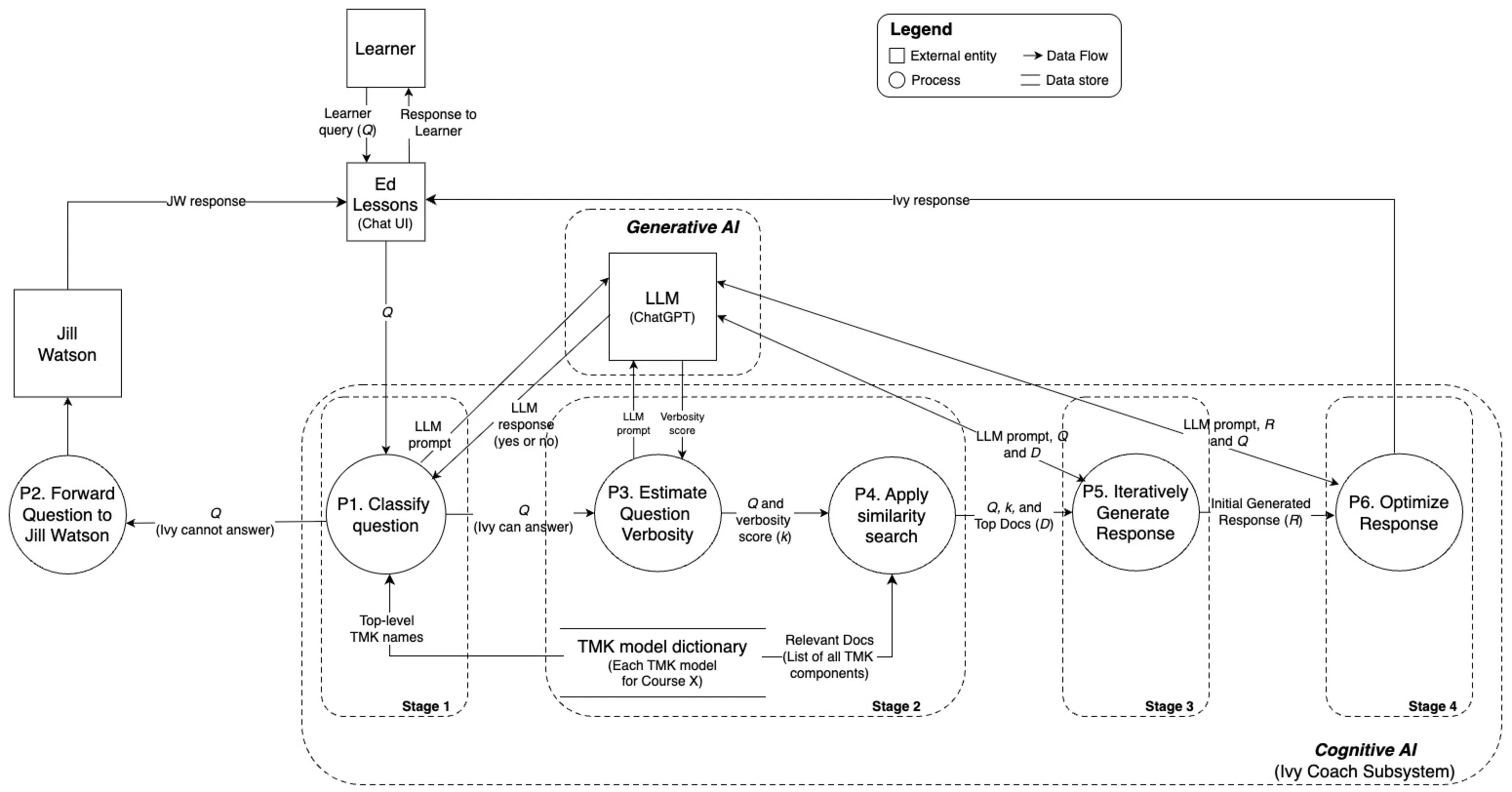
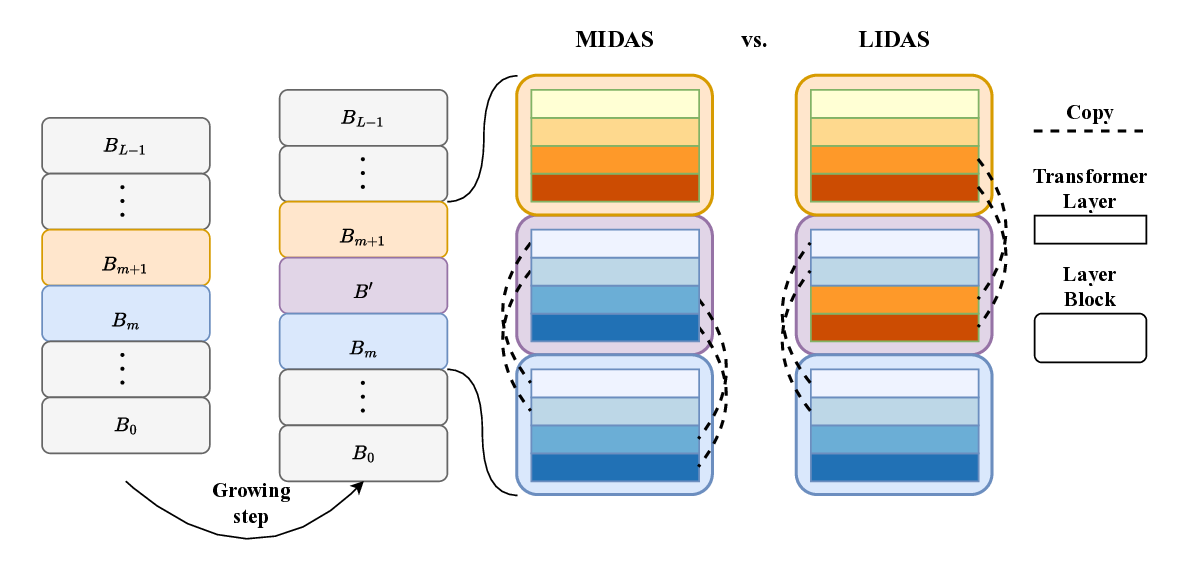
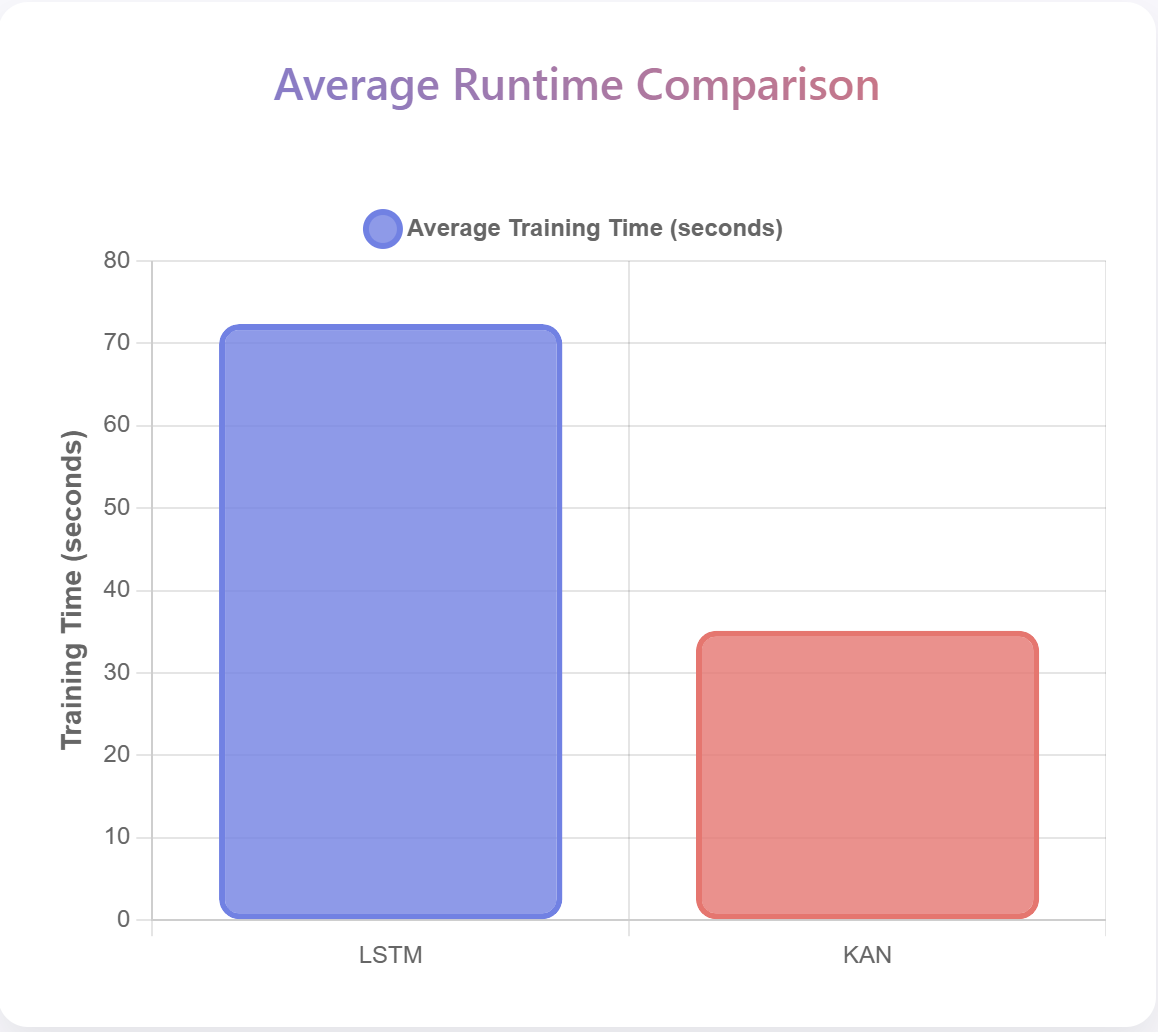
액션플로우: 엣지 로봇을 위한 초고속 비전‑언어‑액션 추론 프레임워크
Vision-Language-Action (VLA) models have emerged as a unified paradigm for robotic perception and control, enabling emergent generalization and long-horizon task execution. However, their deployment in dynamic, real-world environments is severely hin