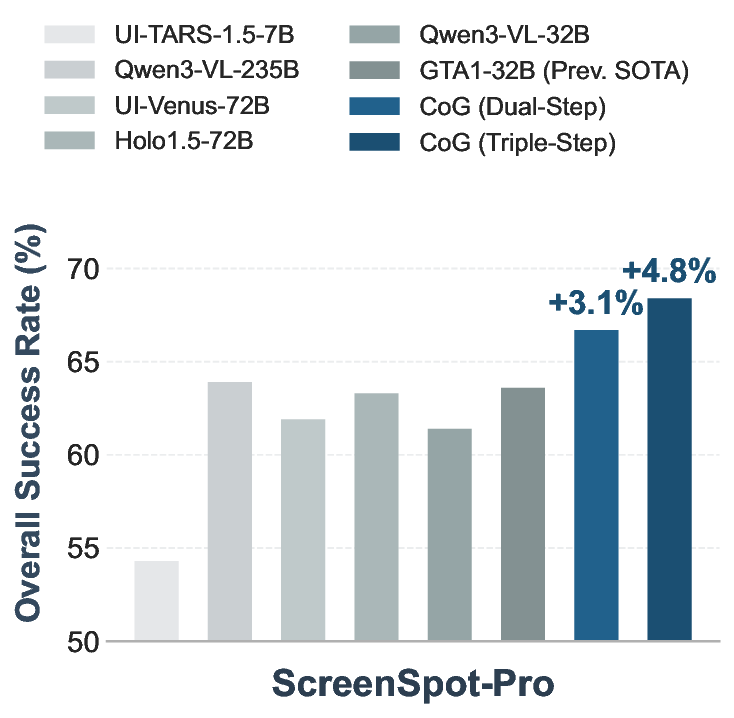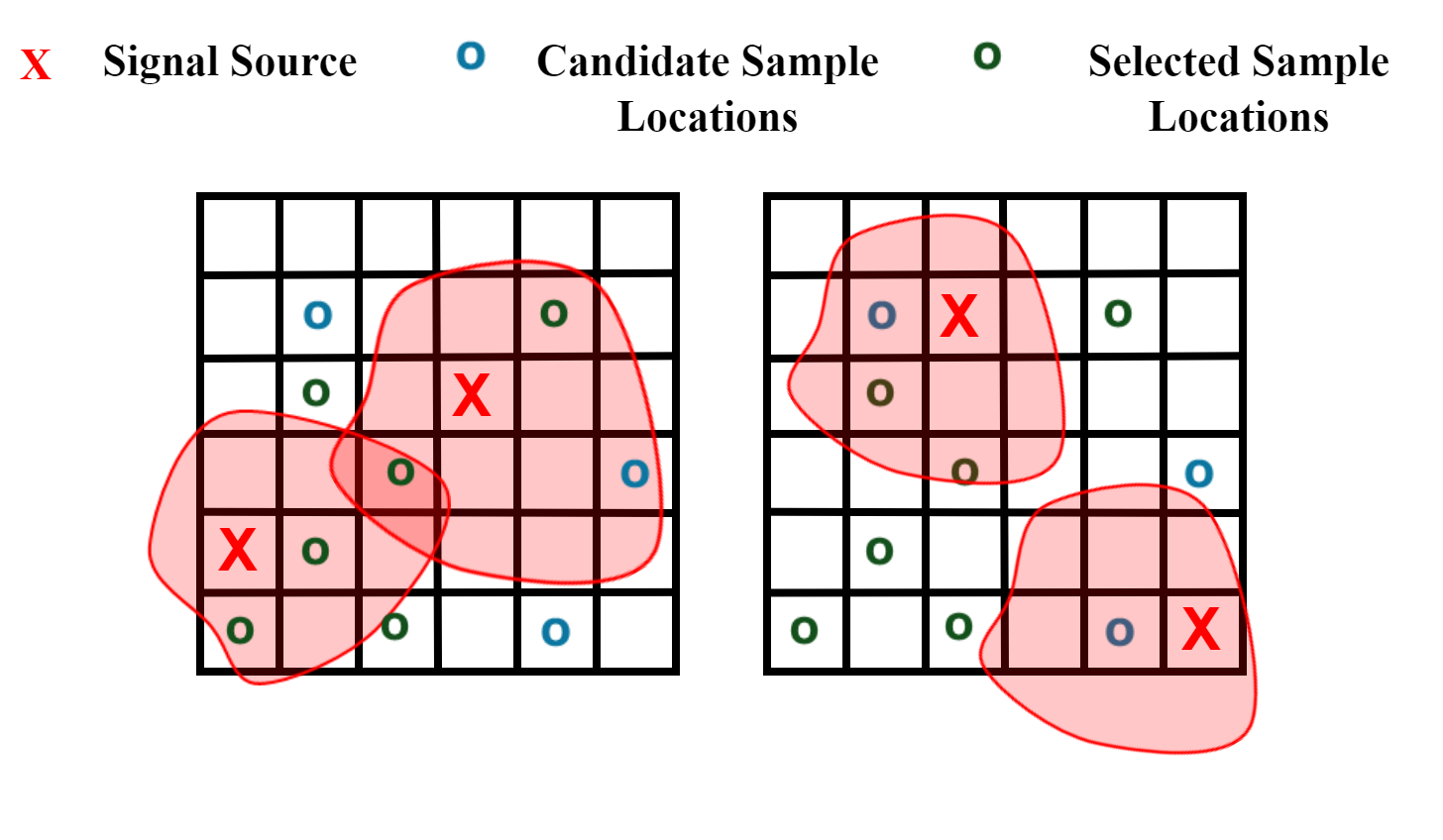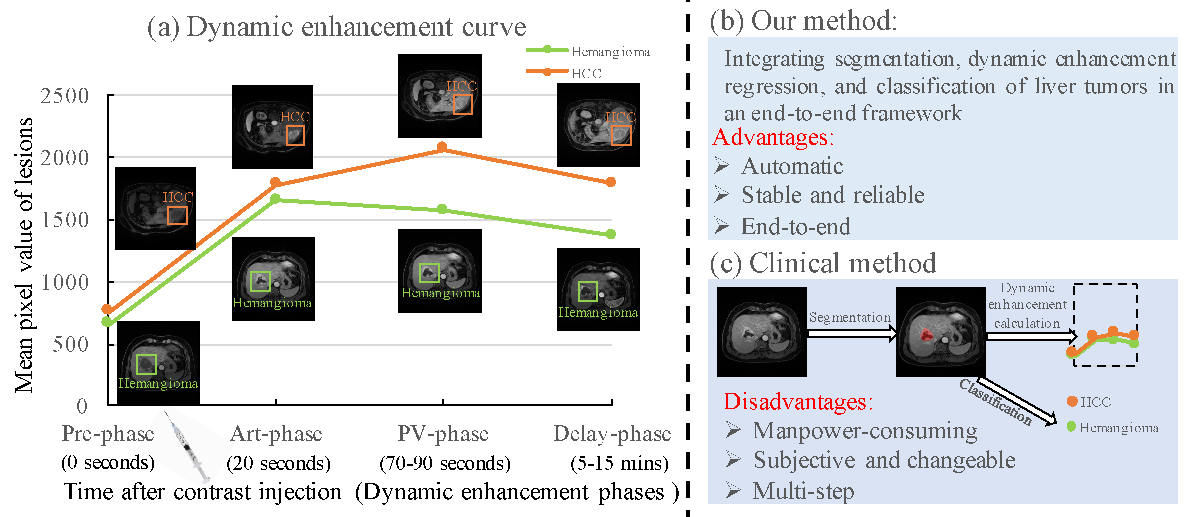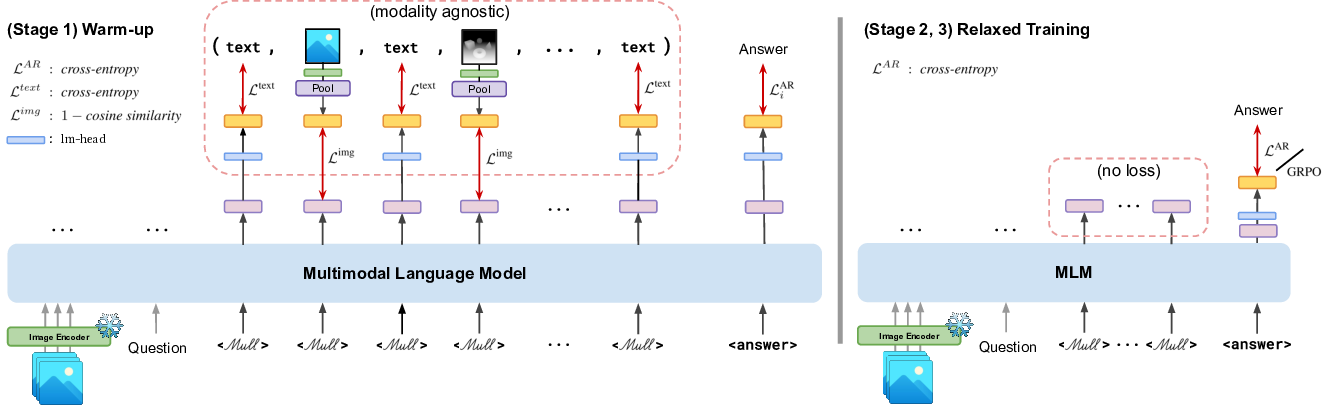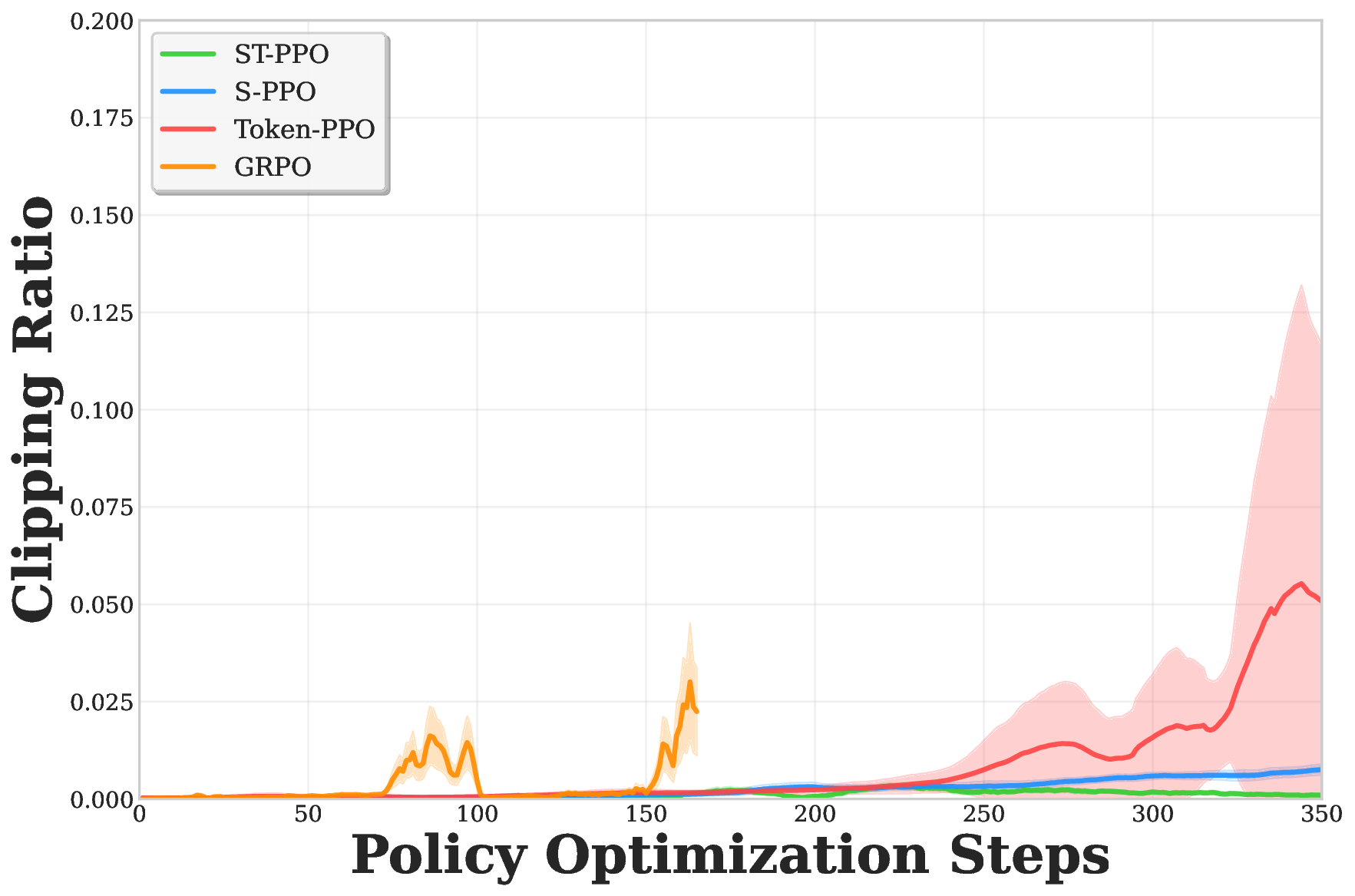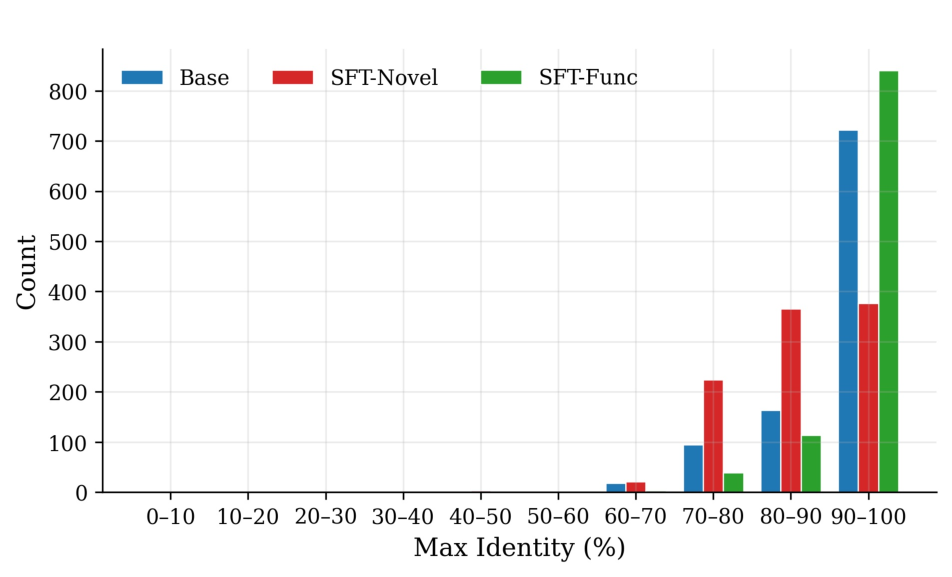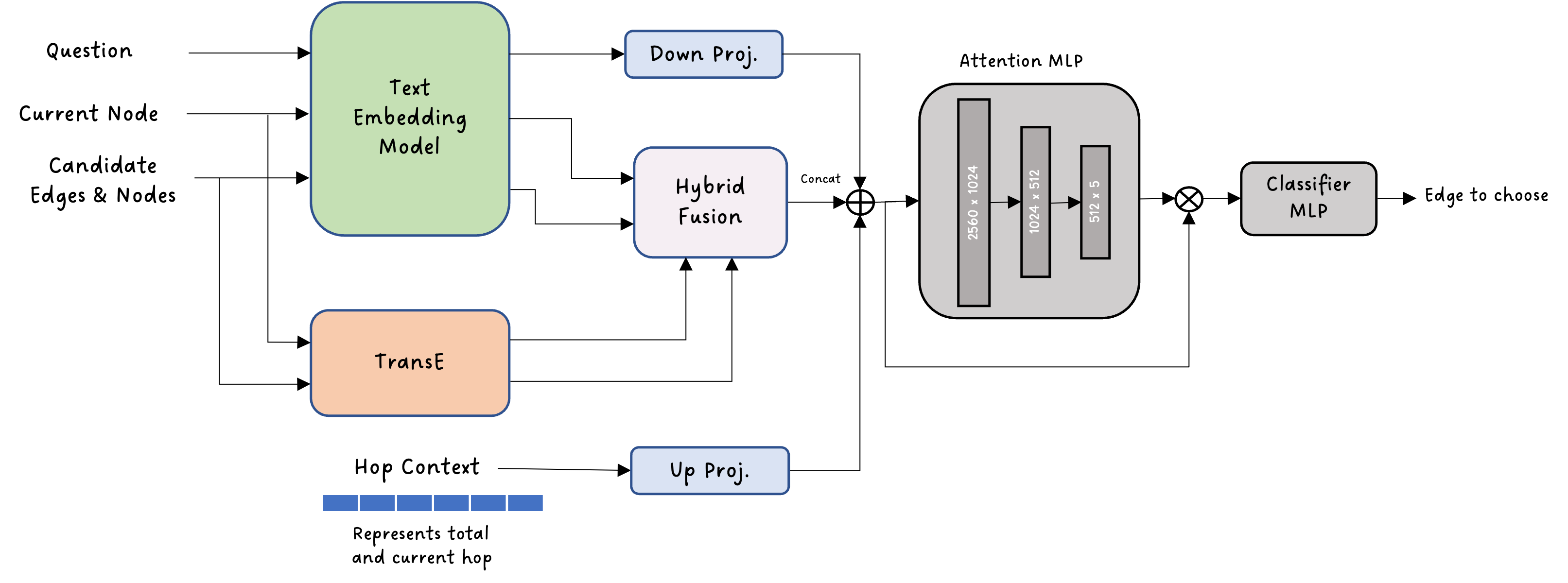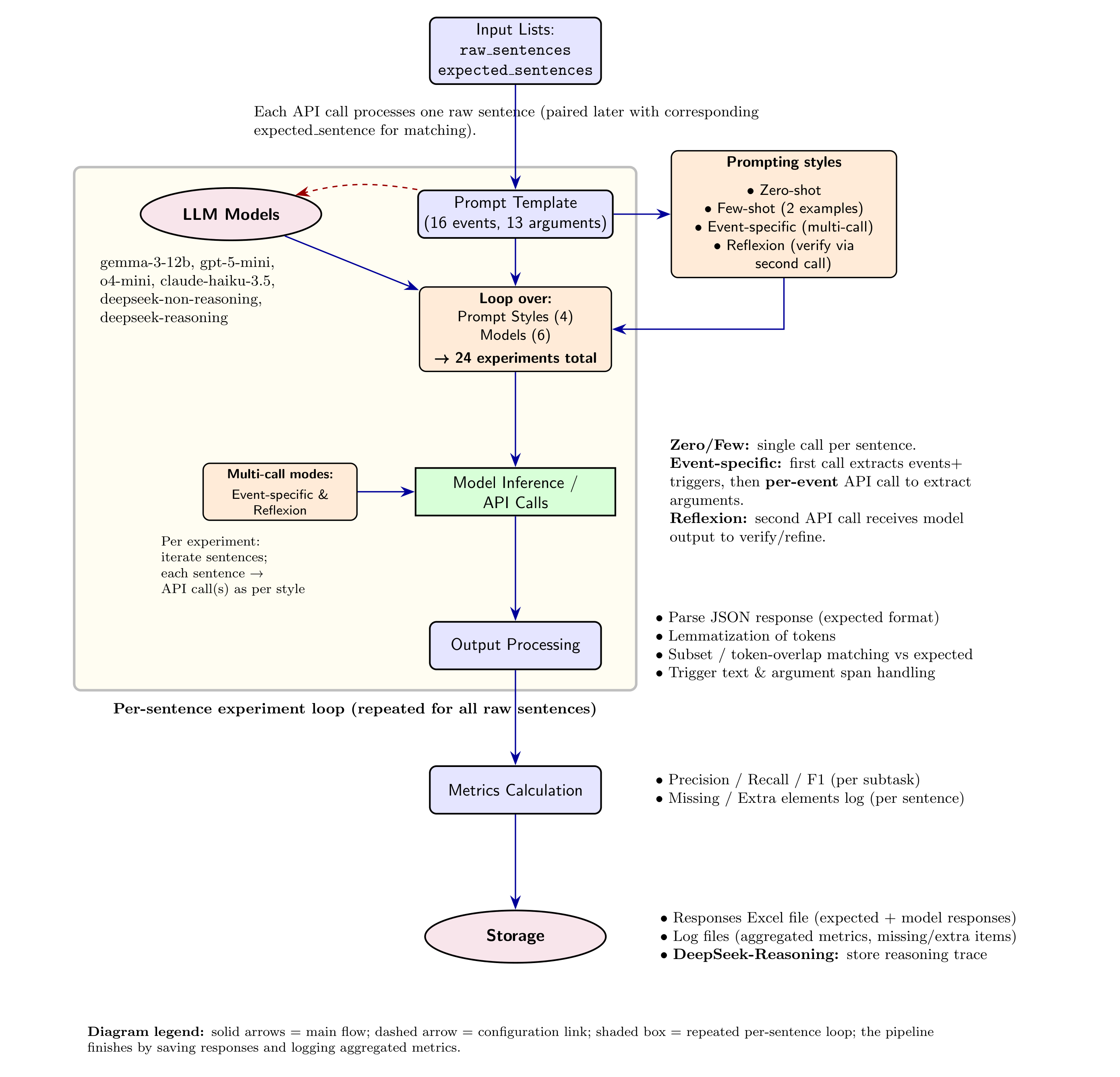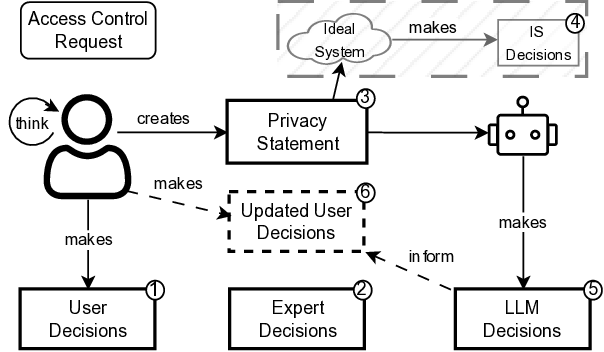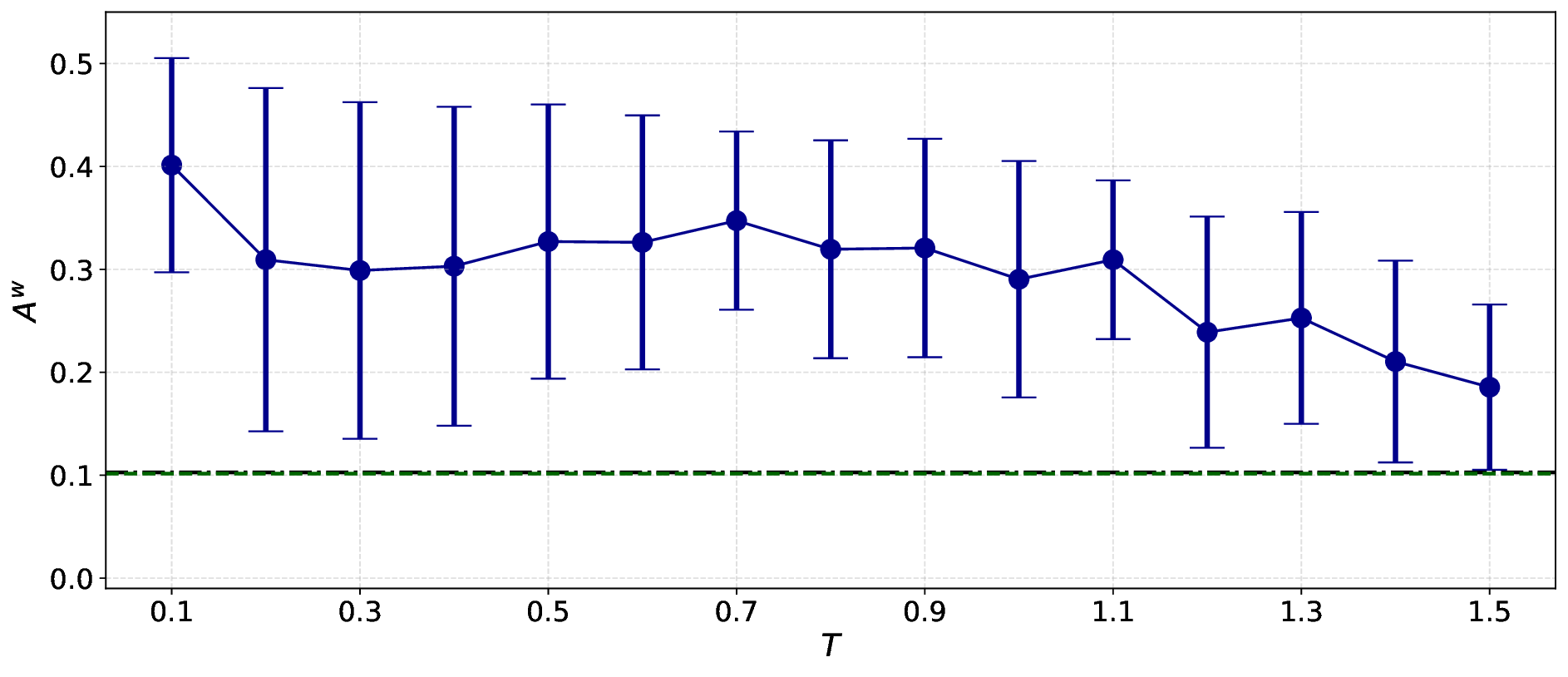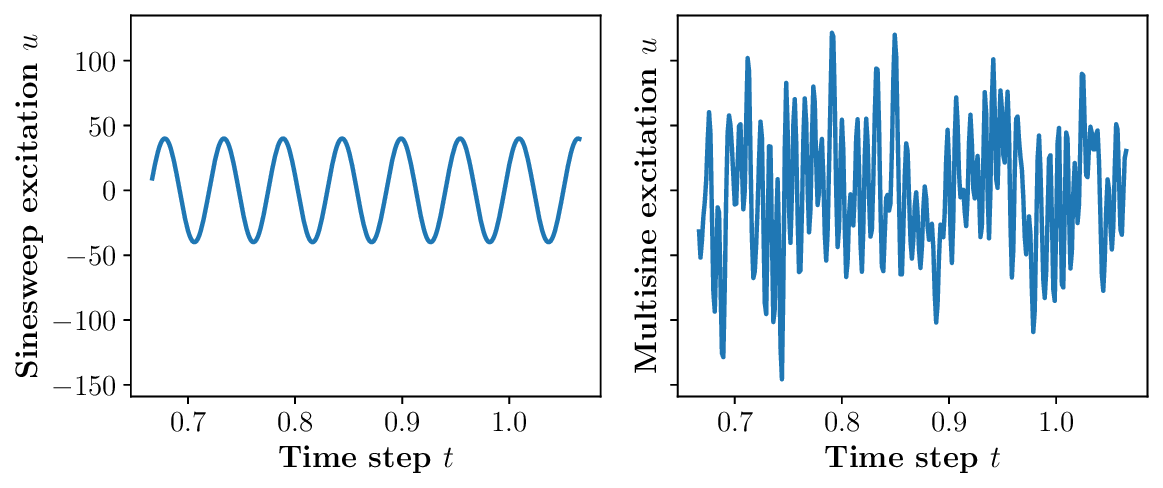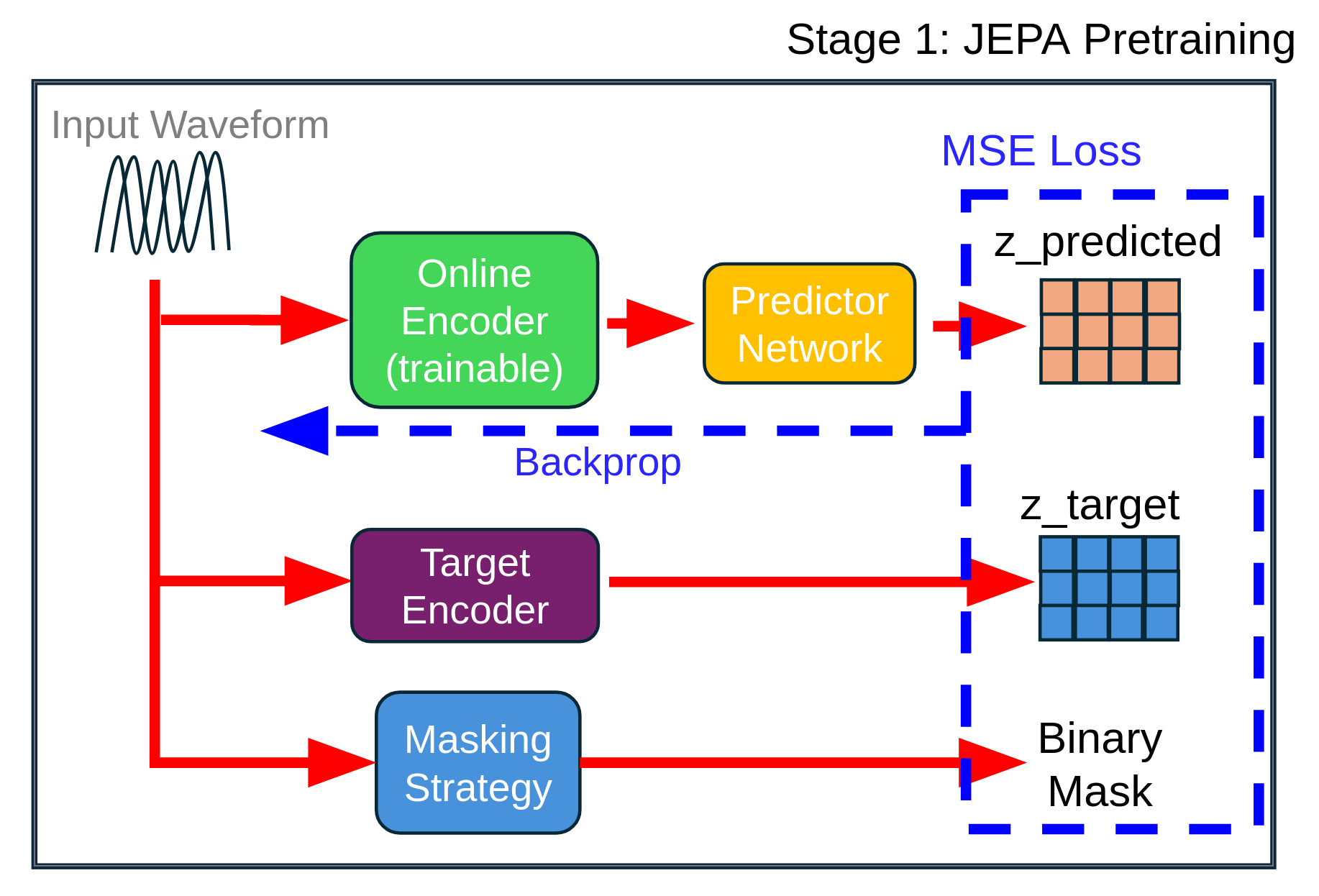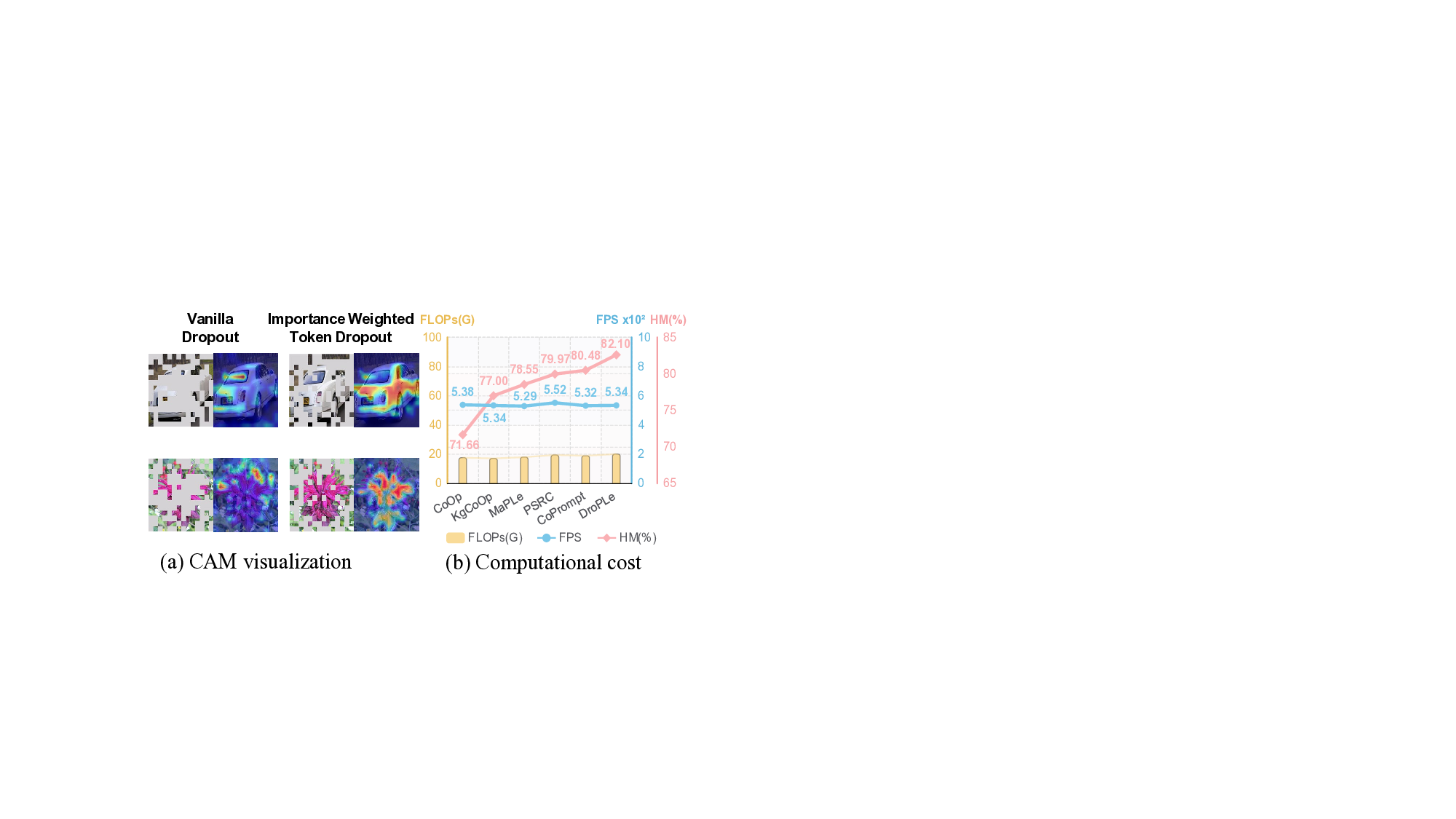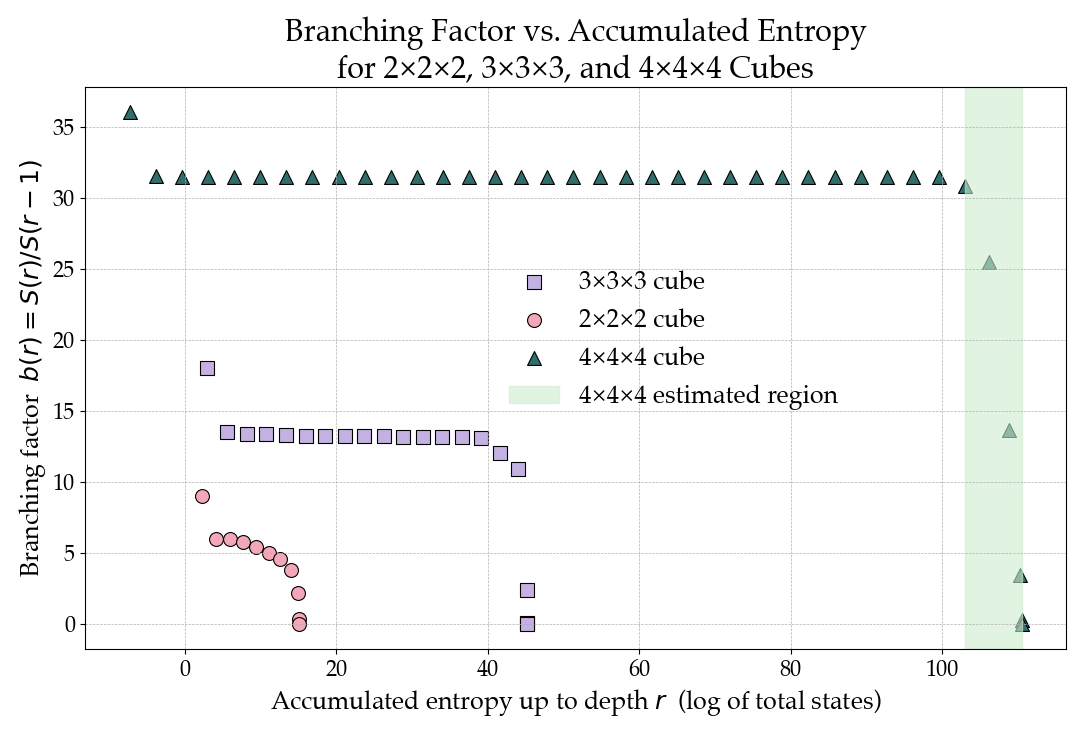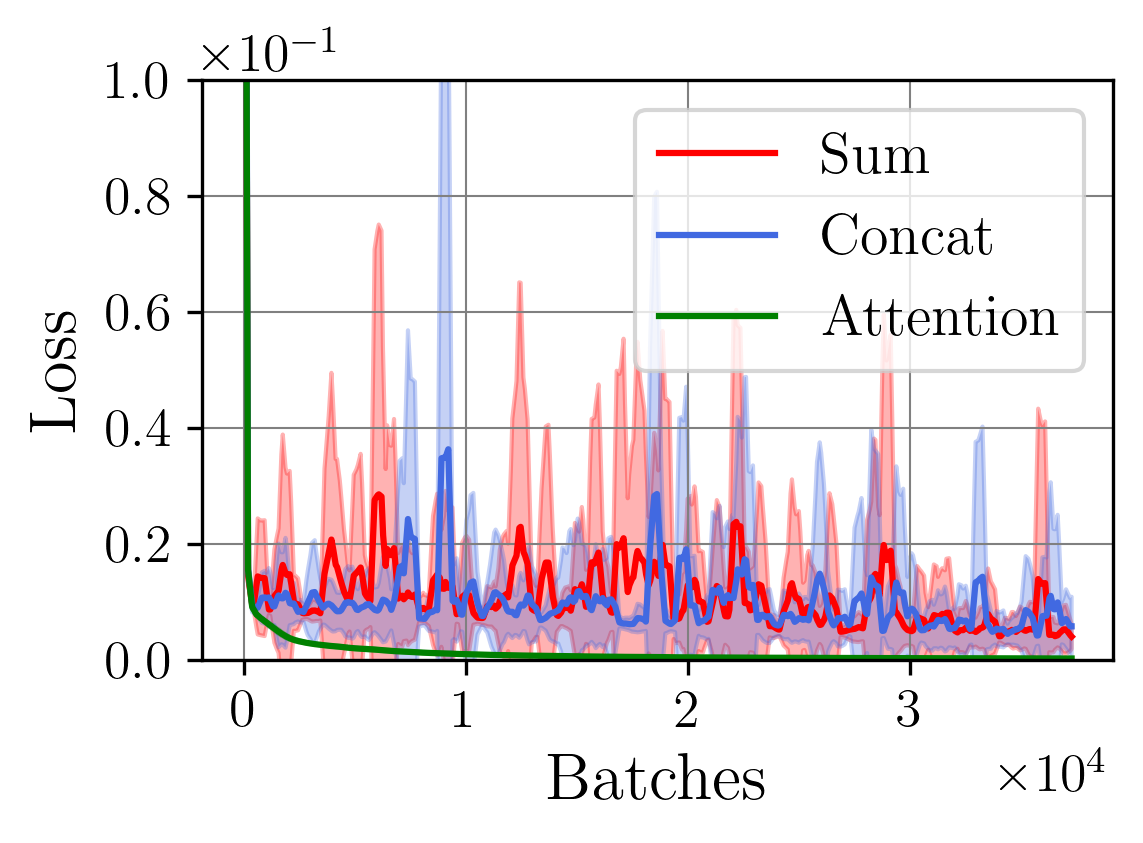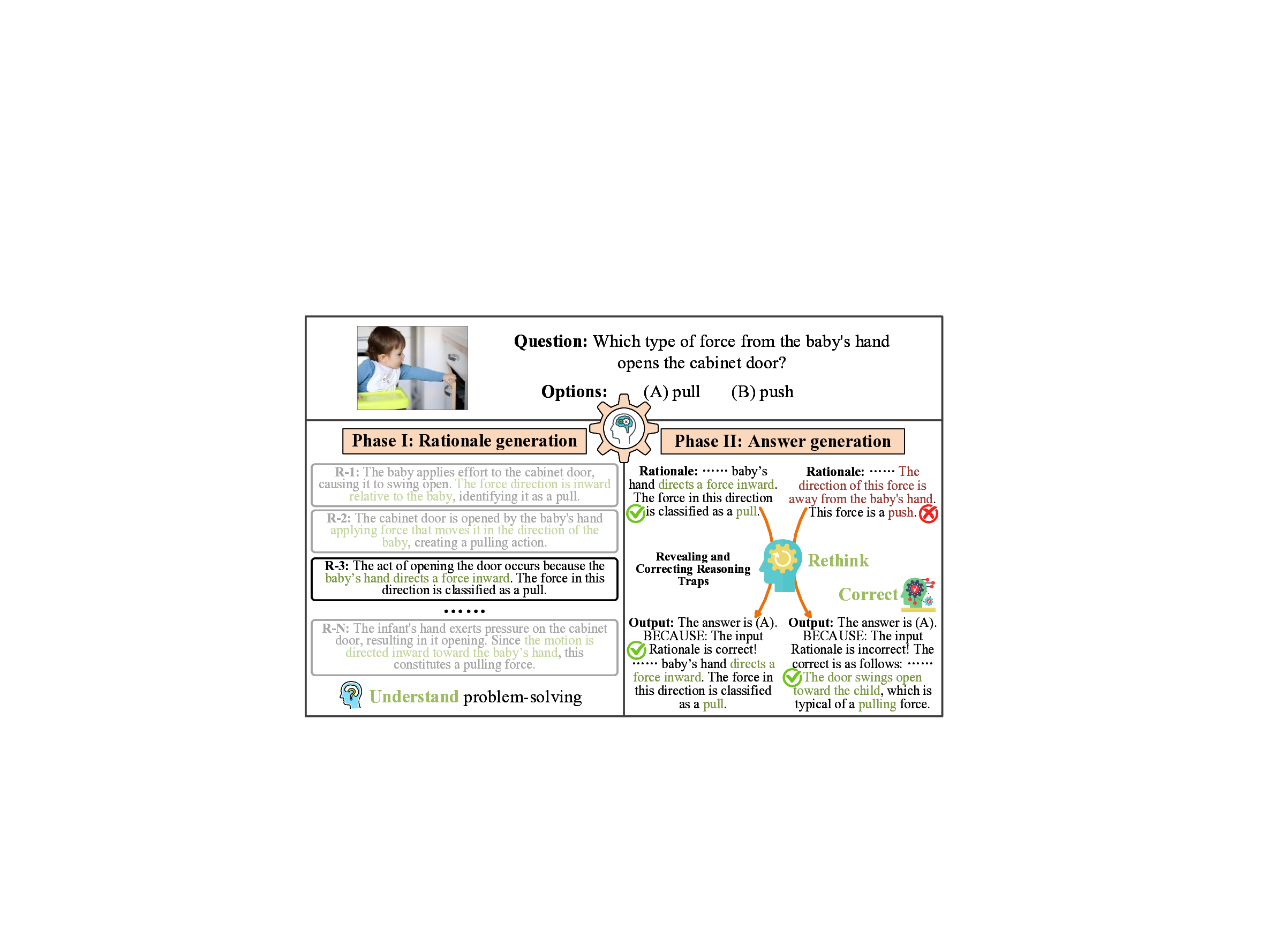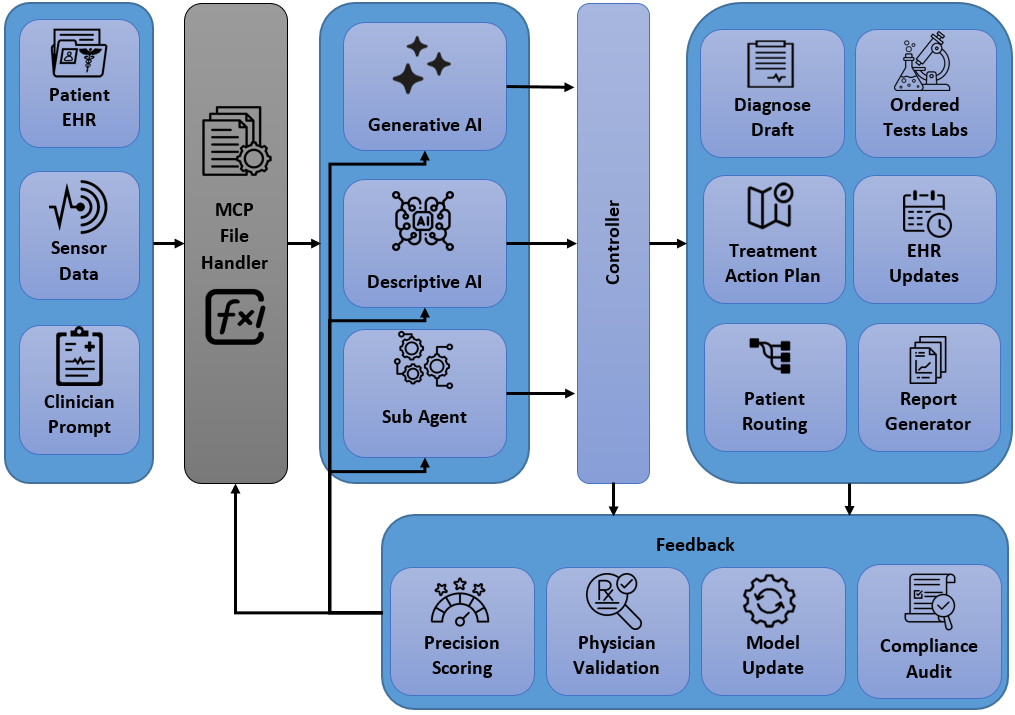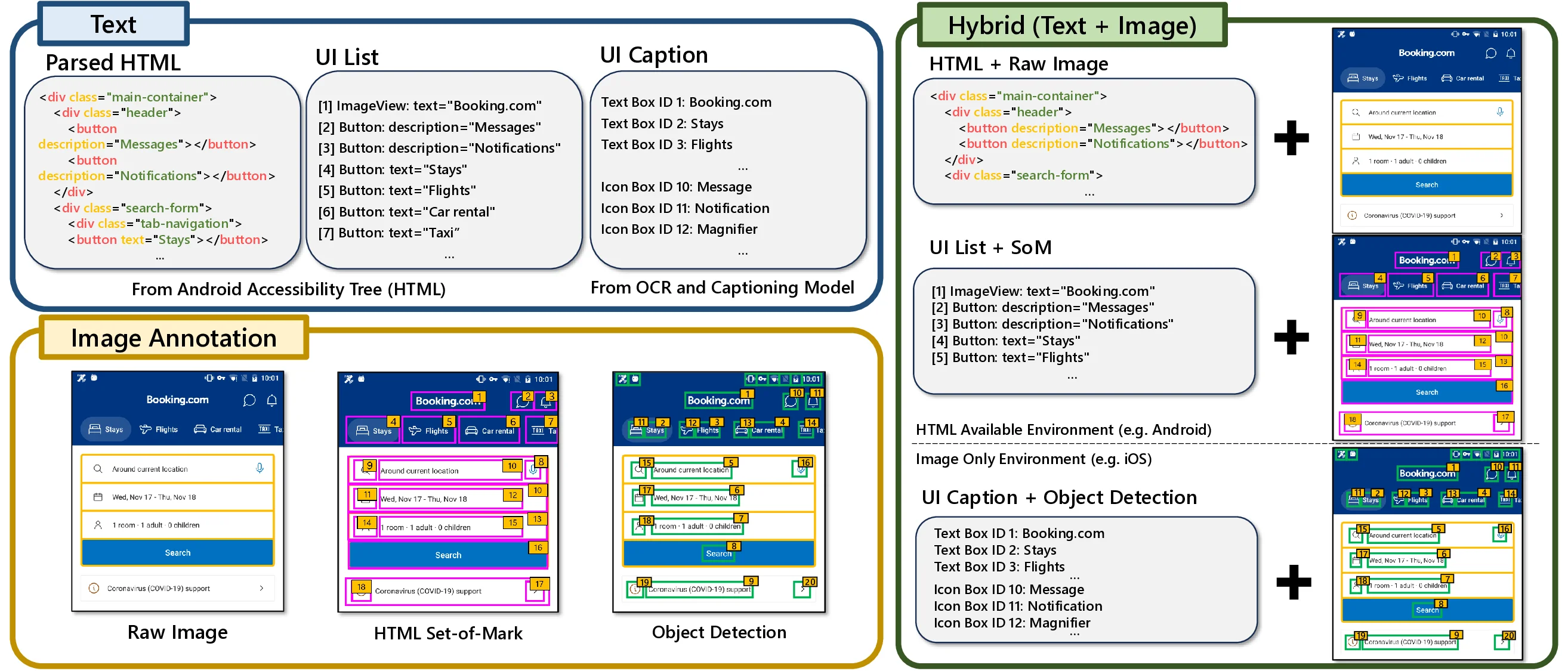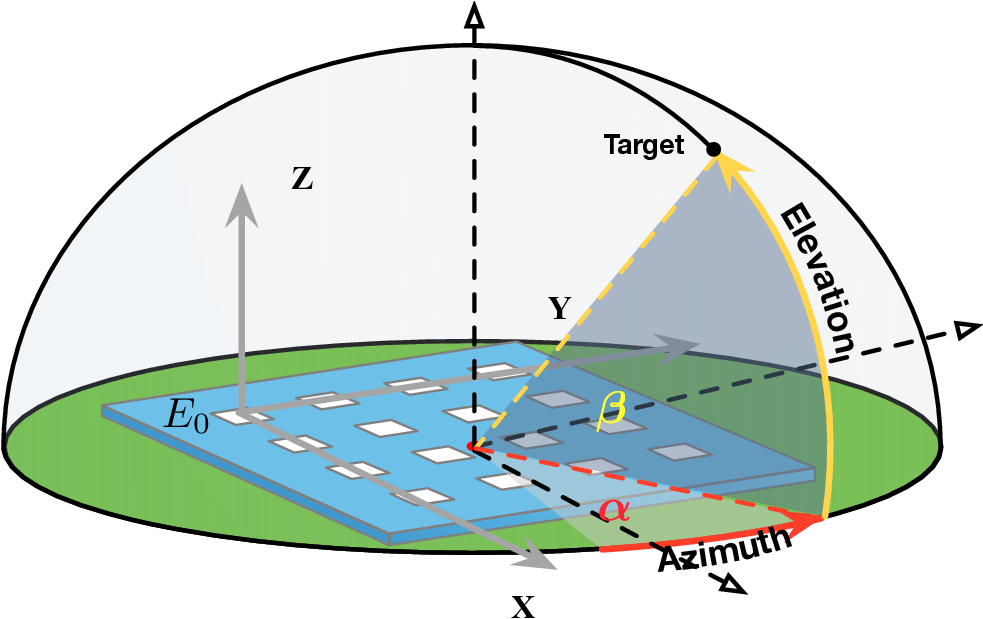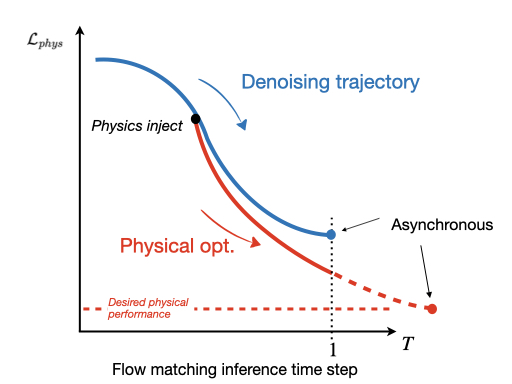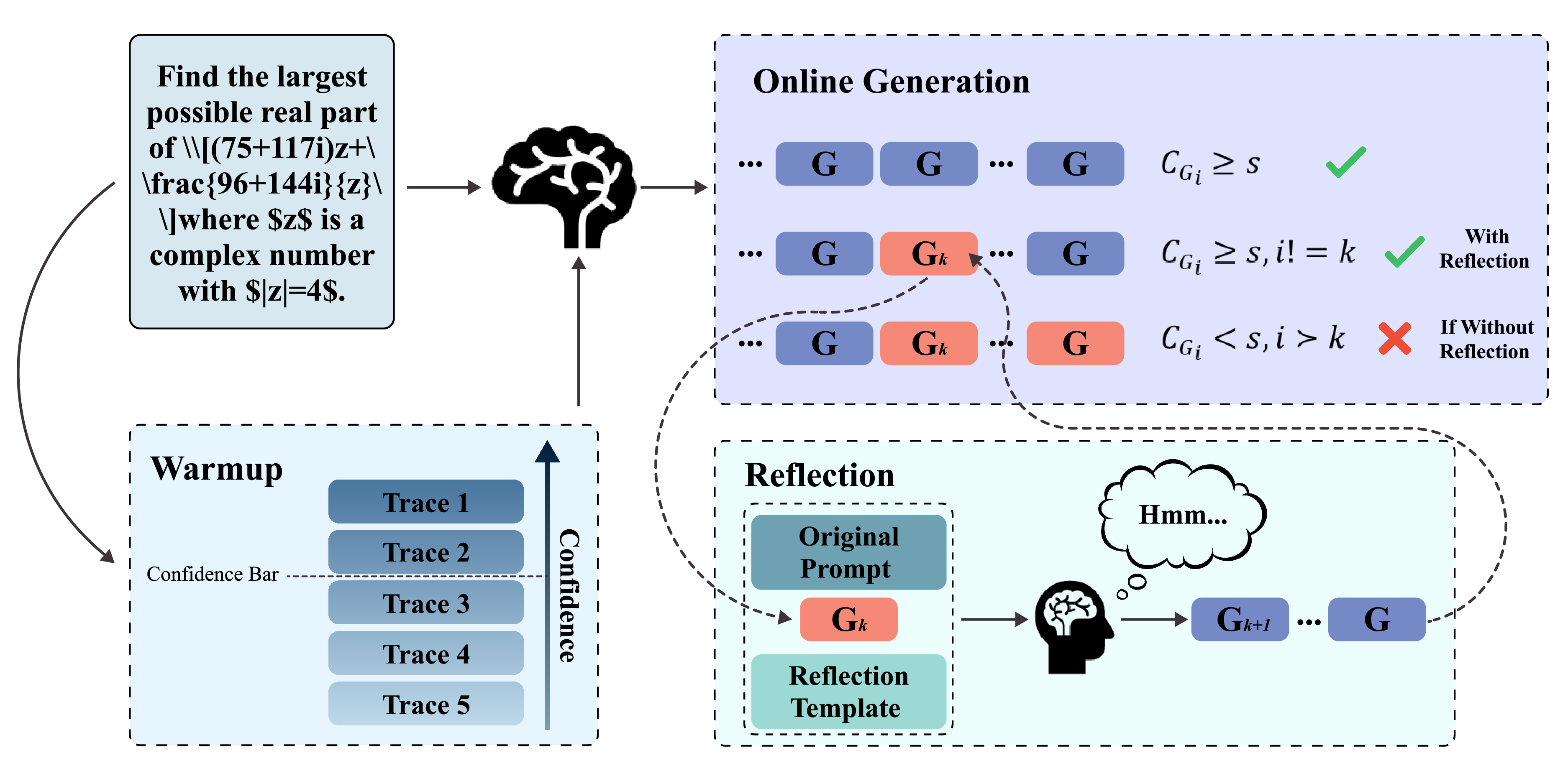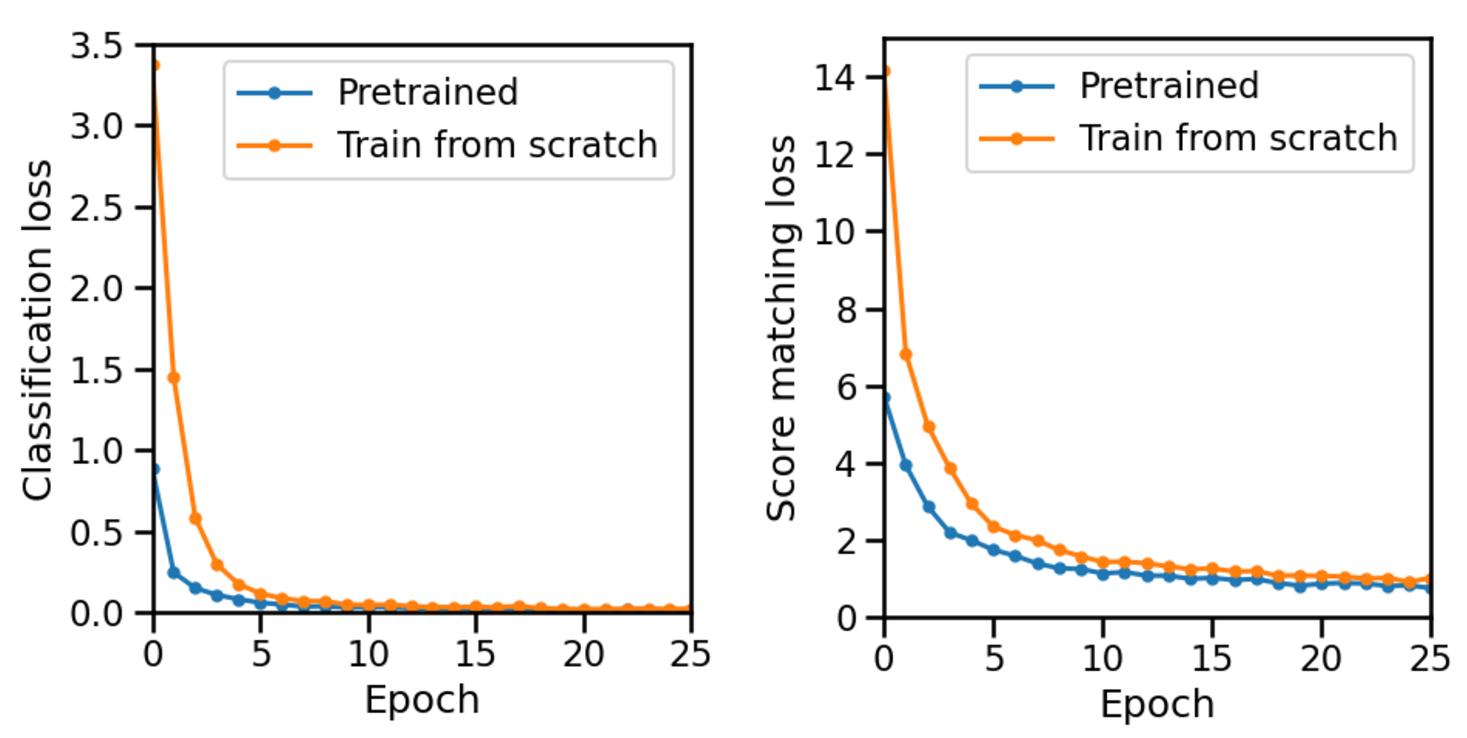
노이즈가 많은 원자 시뮬레이션을 위한 로그확률 기반 통합 위상 분류 및 결함 정량화 모델
Atomistic simulations generate large volumes of noisy structural data, but extracting phase labels, order parameters (OPs), and defect information in a way that is universal, robust, and interpretable remains challenging. Existing tools such as PTM a