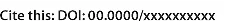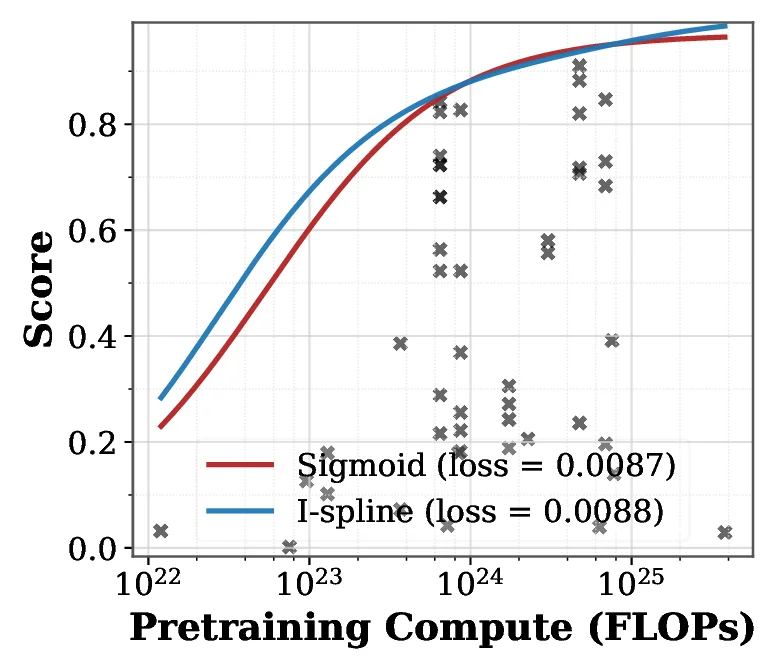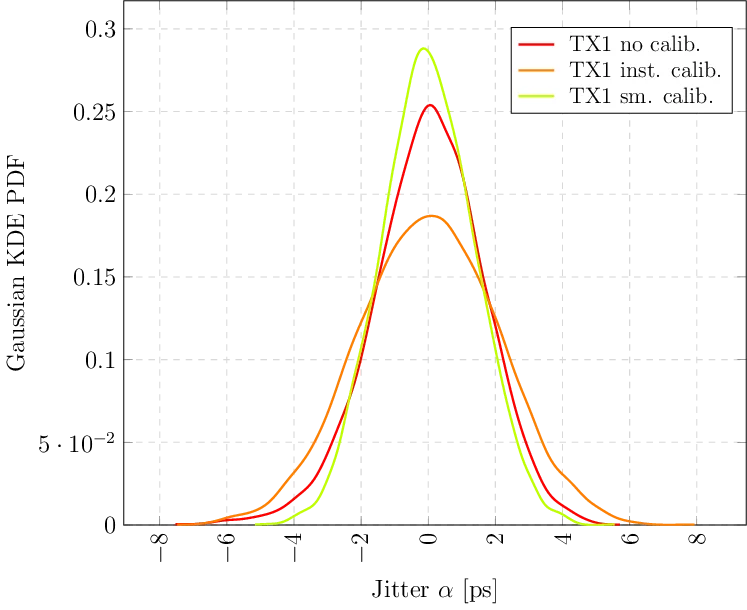
On the Learning Dynamics of RLVR at the Edge of Competence
Reinforcement learning with verifiable rewards (RLVR) has been a main driver of recent breakthroughs in large reasoning models. Yet it remains a mystery how rewards based solely on final outcomes can help overcome the long-horizon barrier to extended