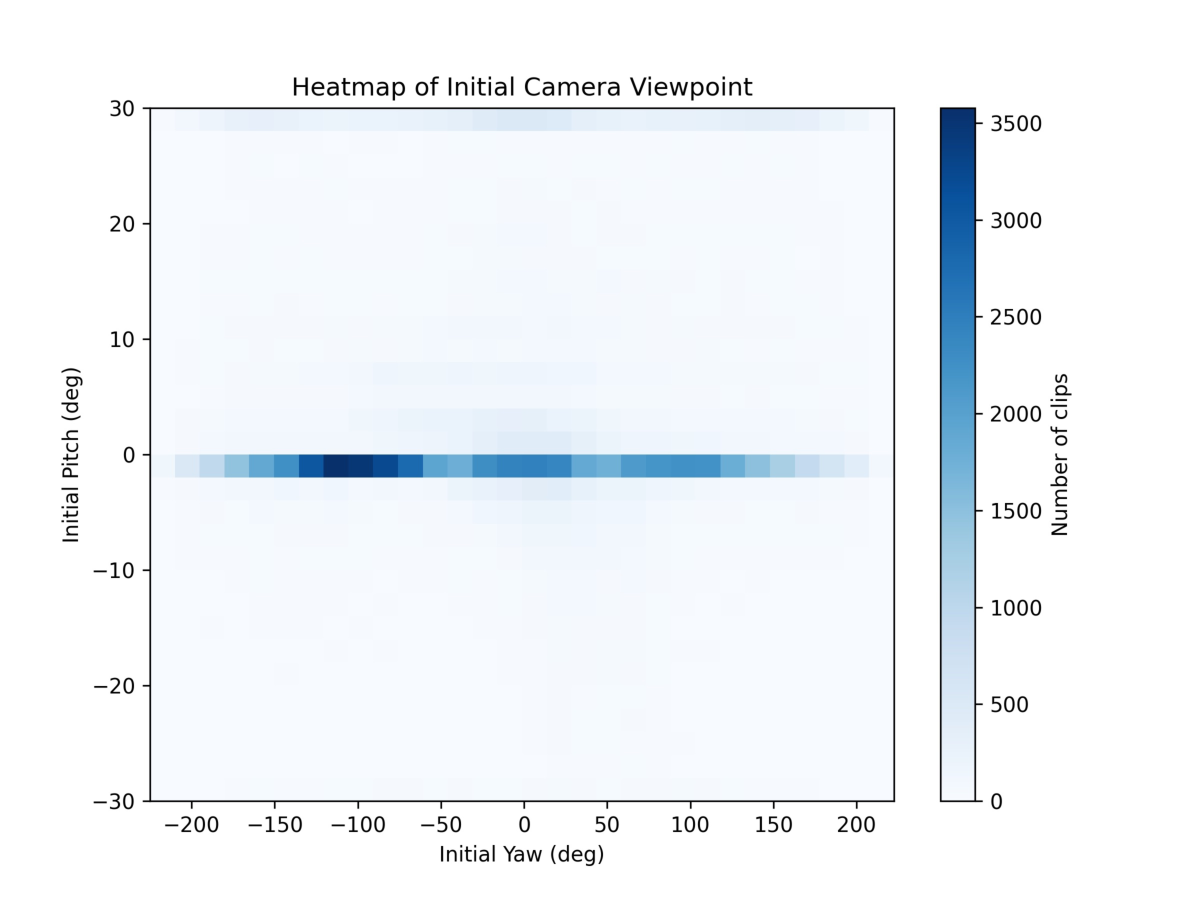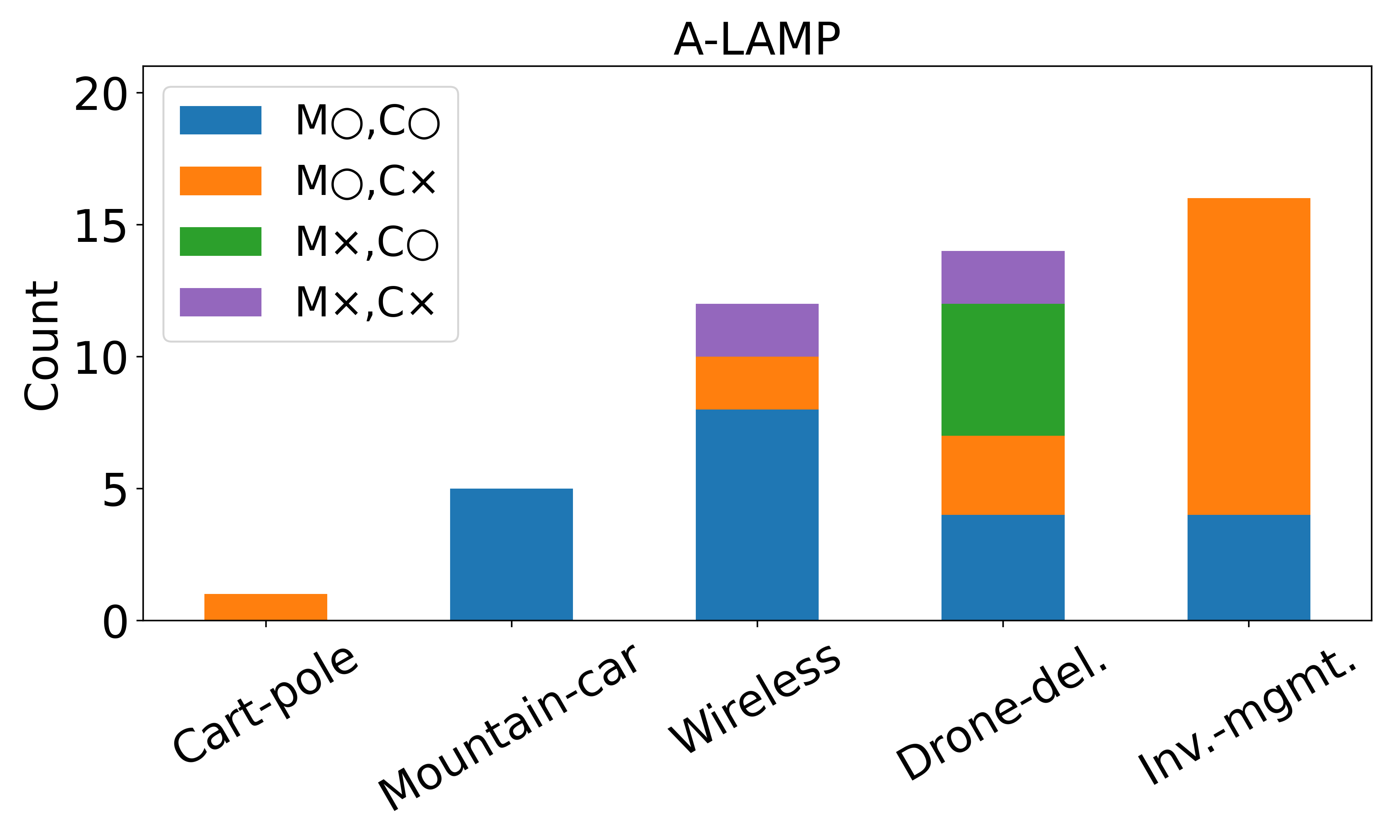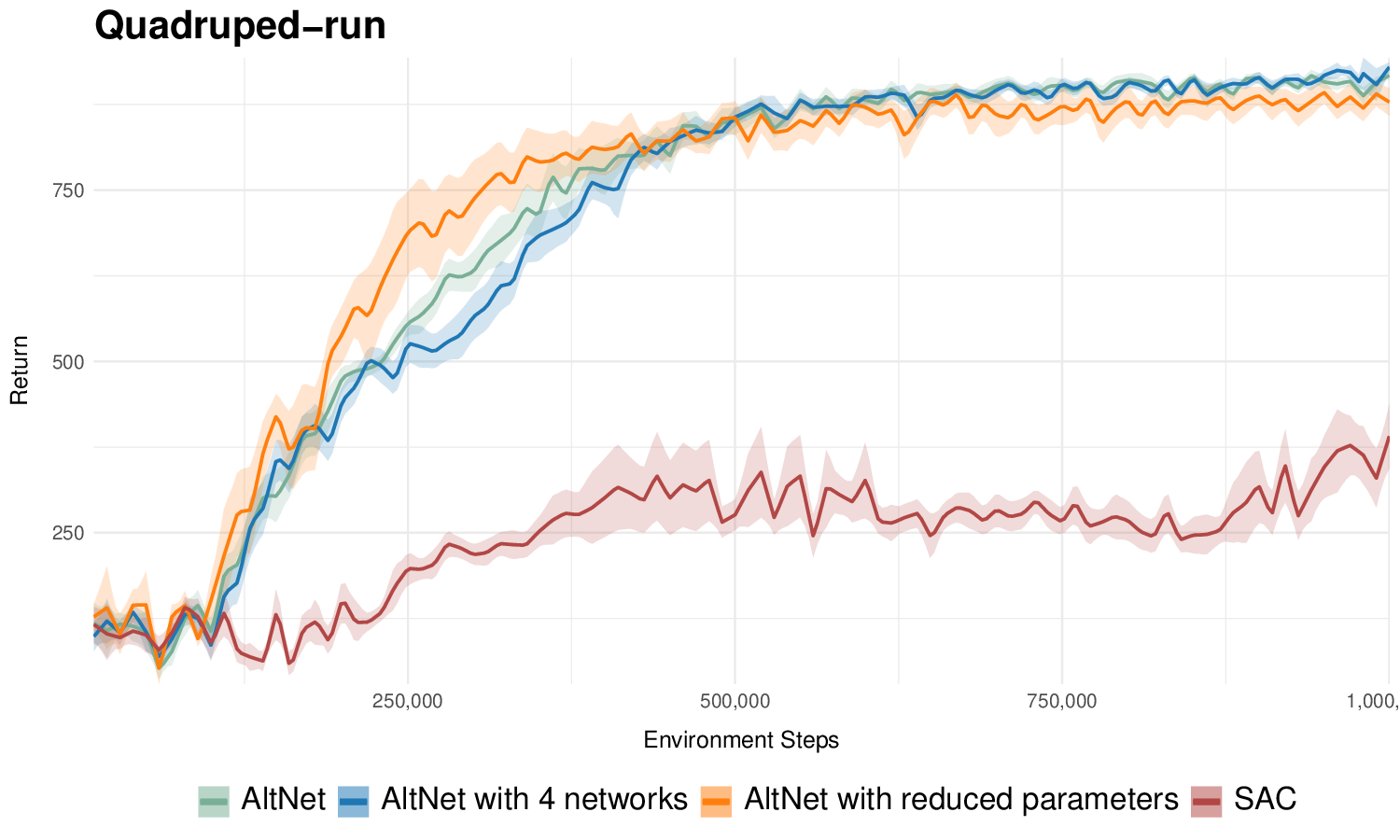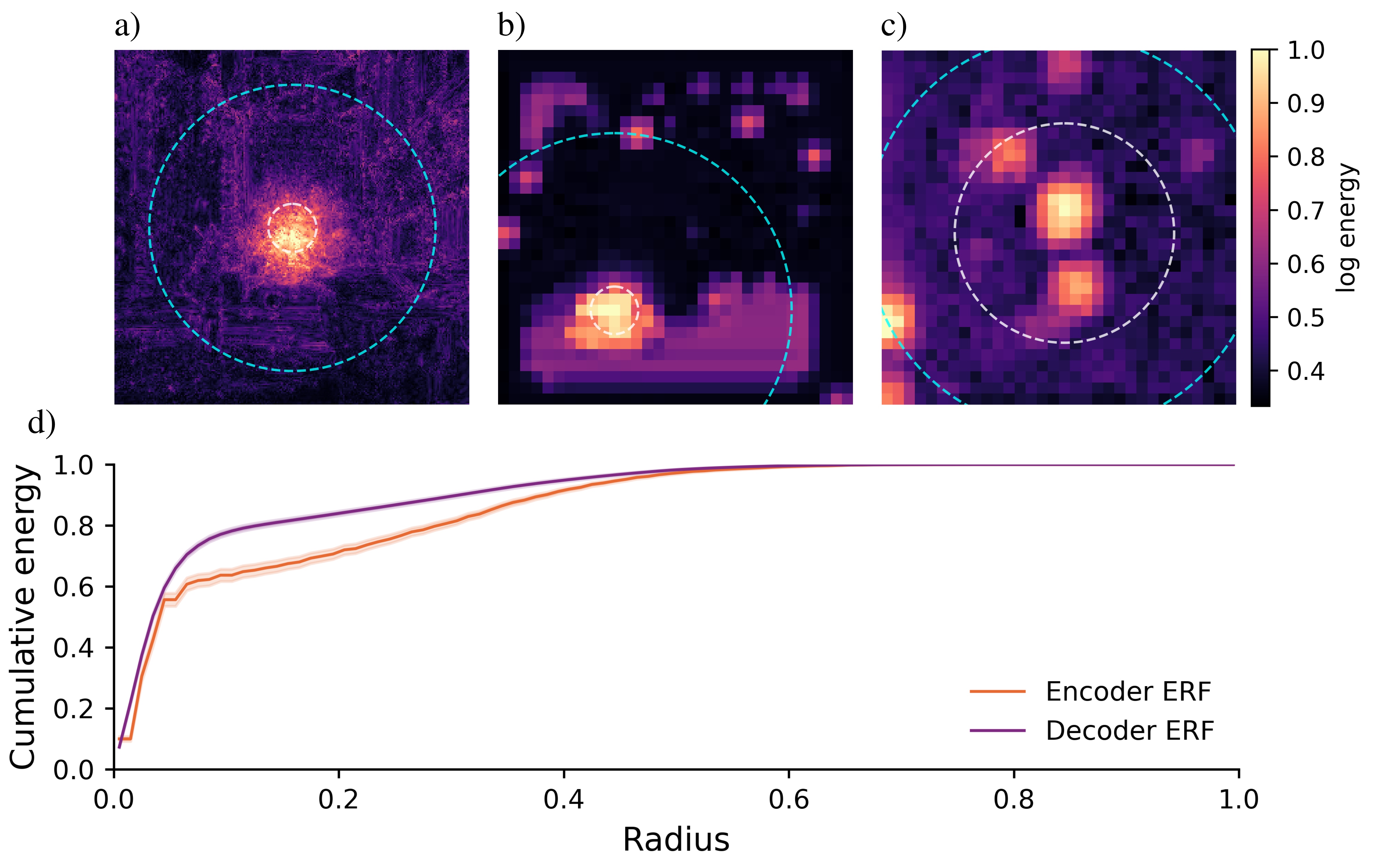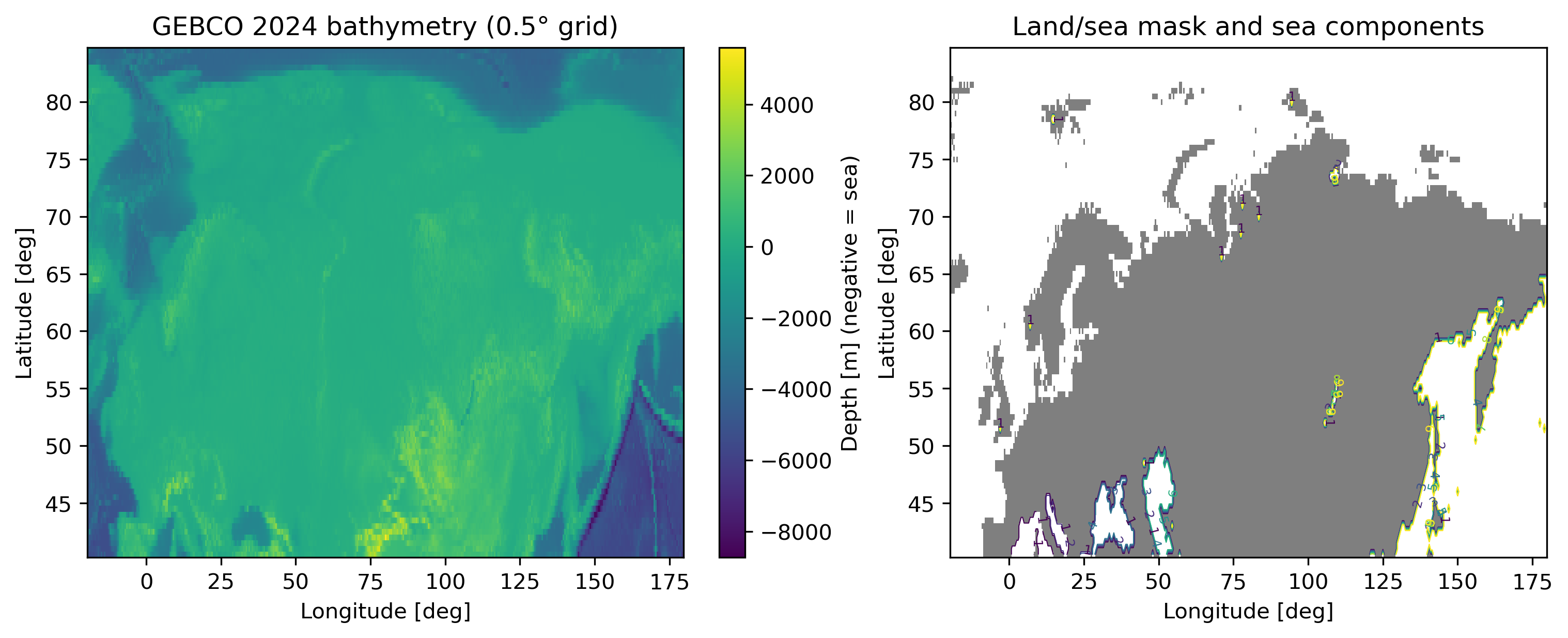
극지 해빙 감소와 트랜스아크틱 항로 가능성 평가 그래프 기반 오프라인 경로 탐색
Climate-driven reductions in Arctic sea-ice extent have renewed interest in trans-Arctic shipping, yet adoption remains limited by questions of route feasibility, safety, and excess distance. Existing work often compares idealised great-circle shortcuts or uses detailed weather-routing systems that