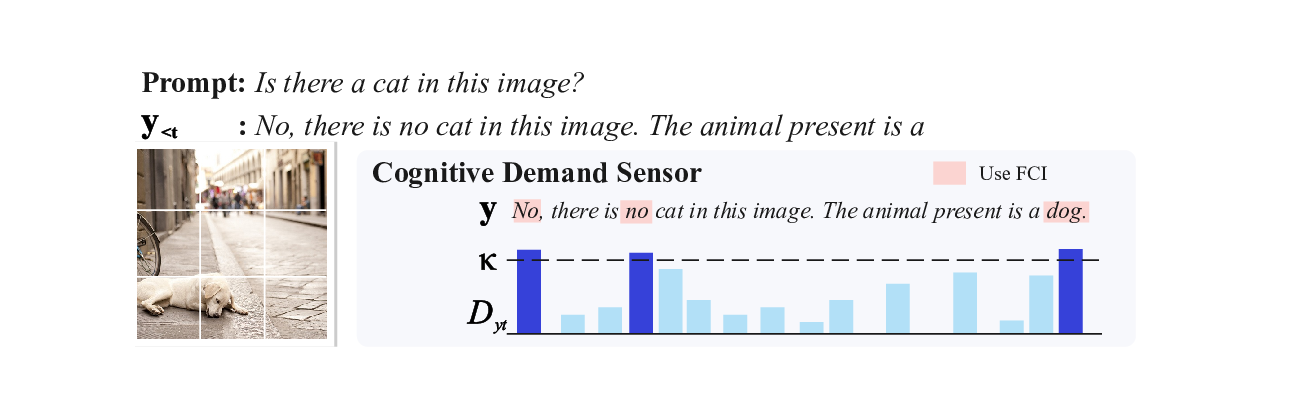
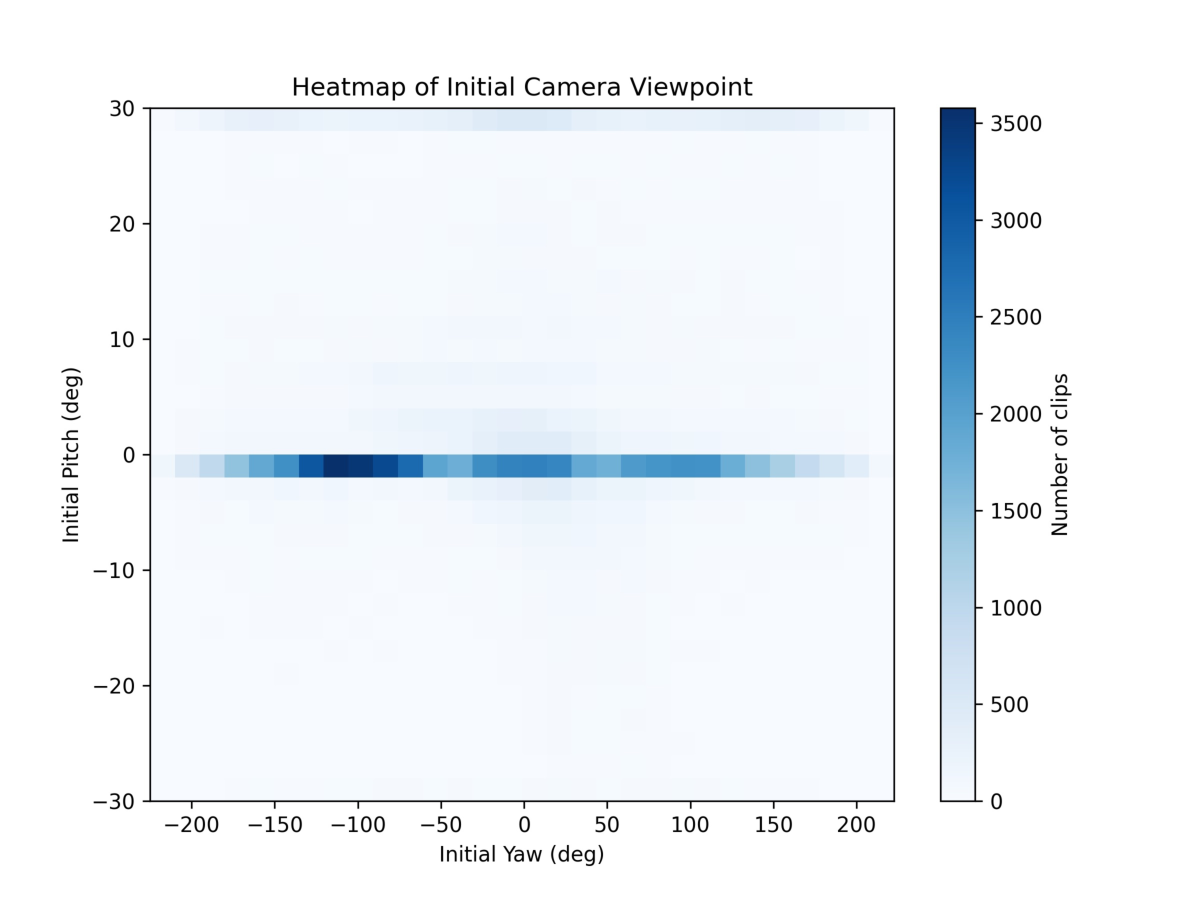
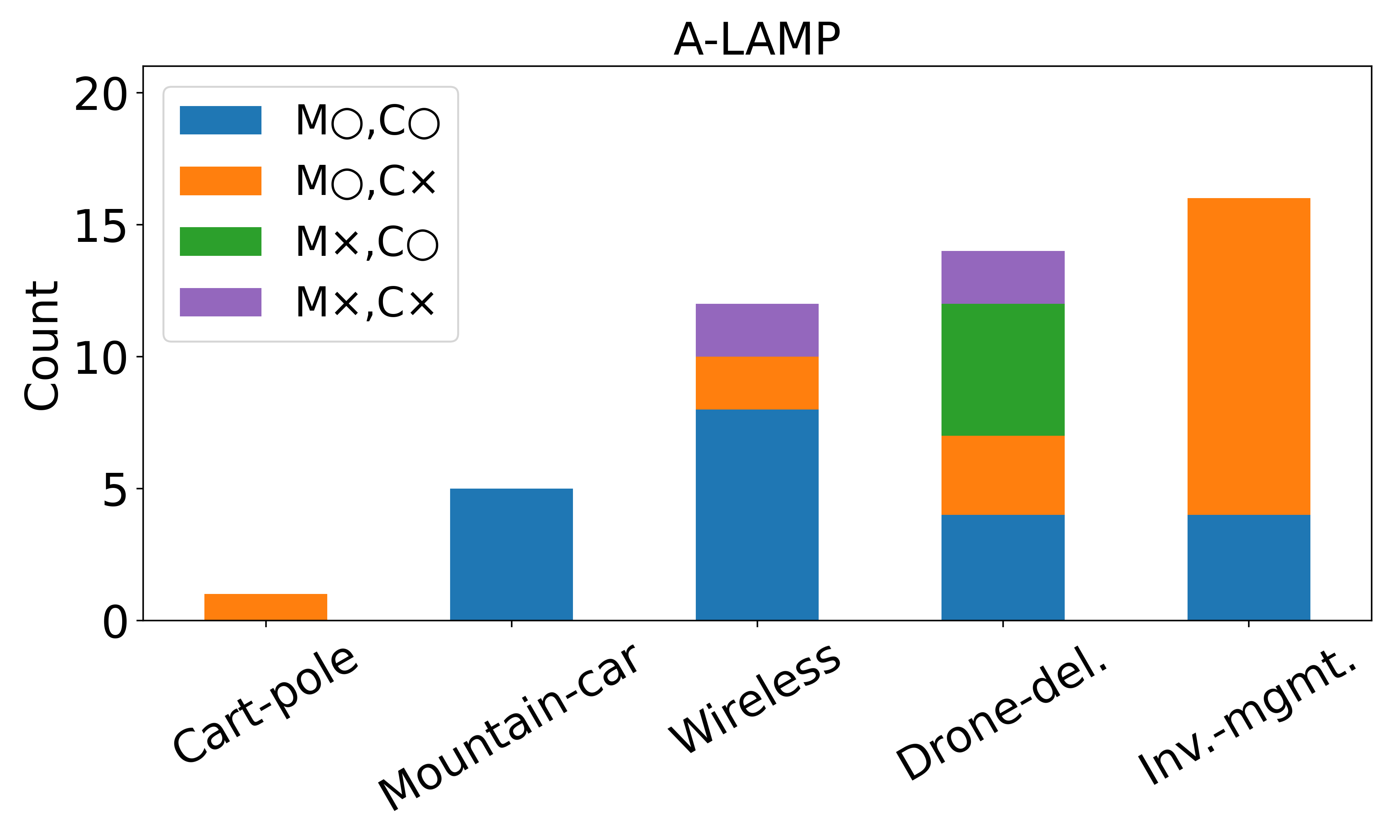
불확실성 시대 인간 AI 공생 지능과 조직 회복력
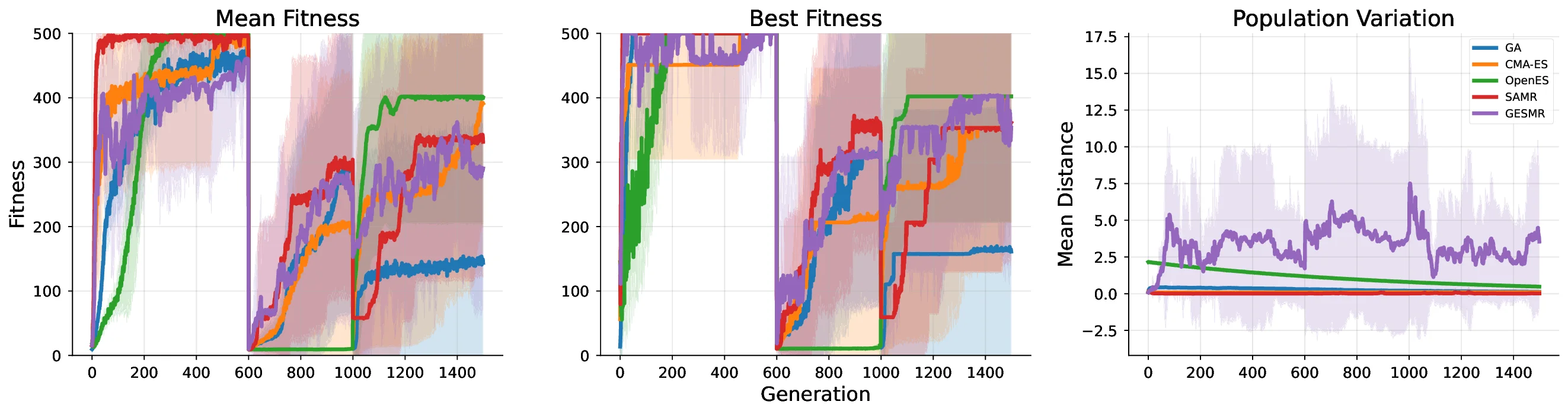
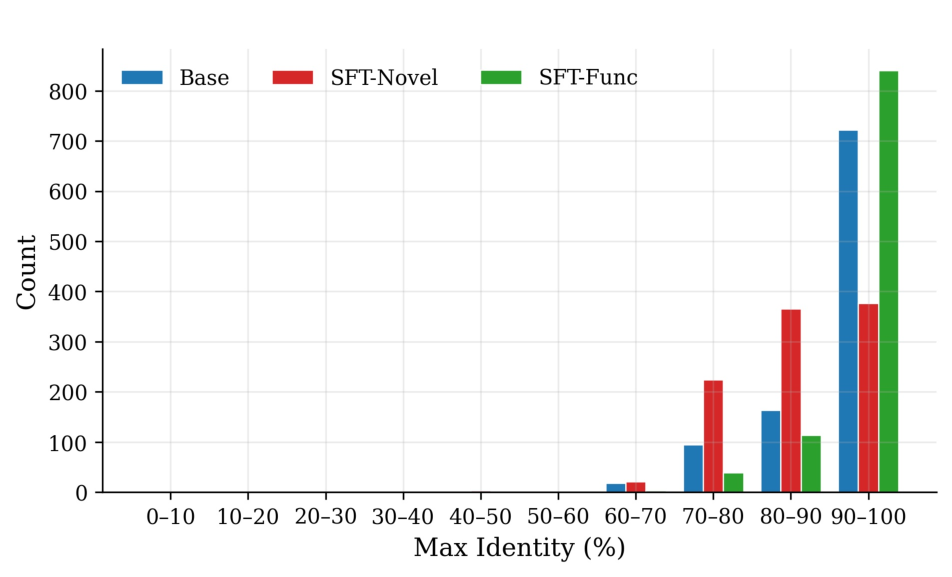
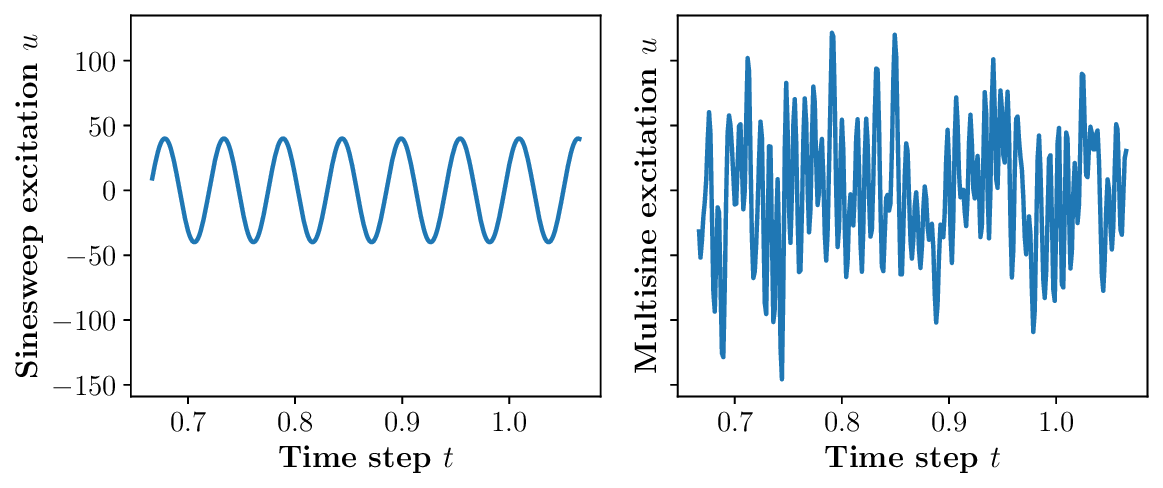
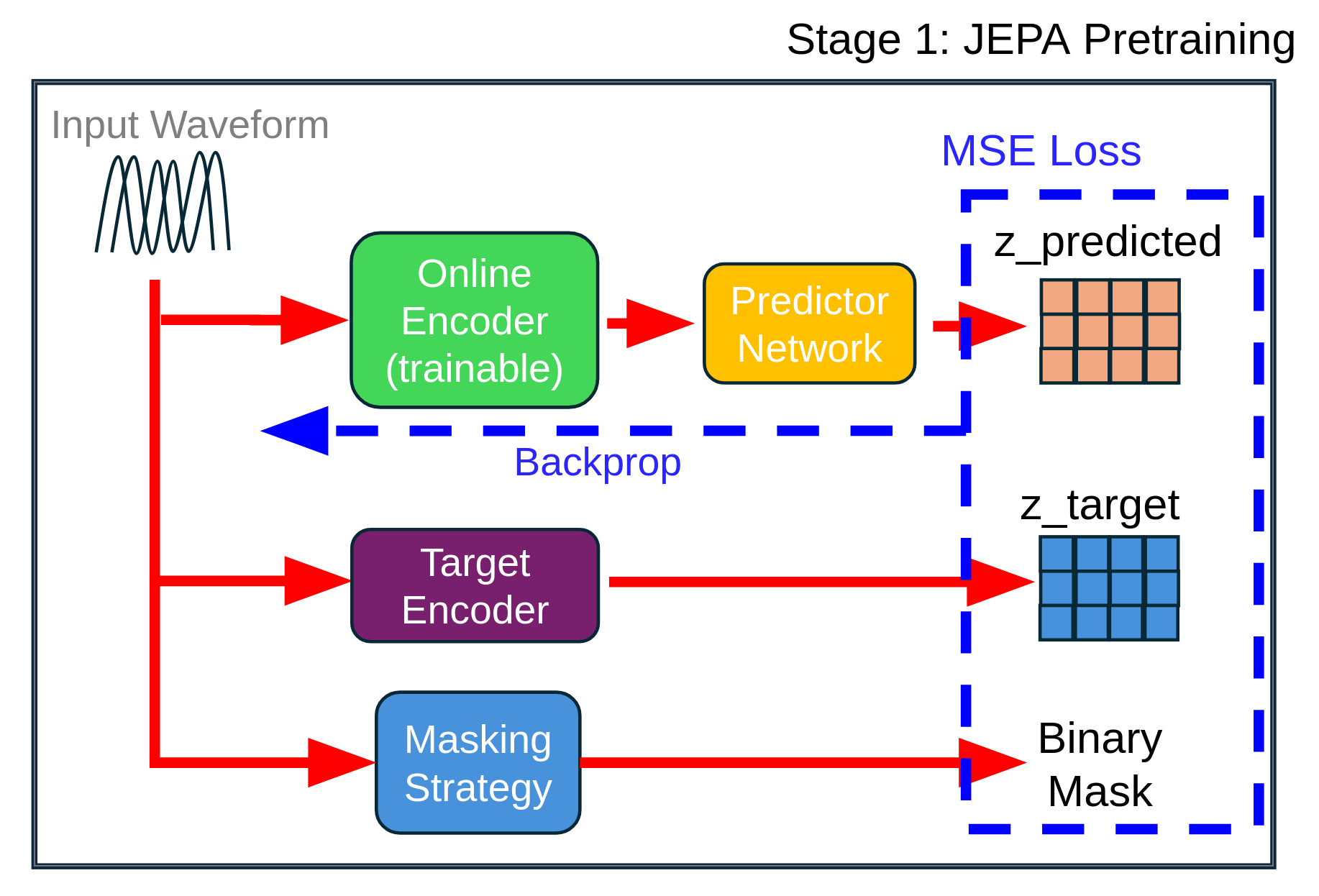
Organizations increasingly operate in environments characterized by volatility, uncertainty, complexity, and ambiguity (VUCA), where early indicators of change often emerge as weak, fragmented signals. Although artificial intelligence (AI) is widely used to support managerial decision-making, most A