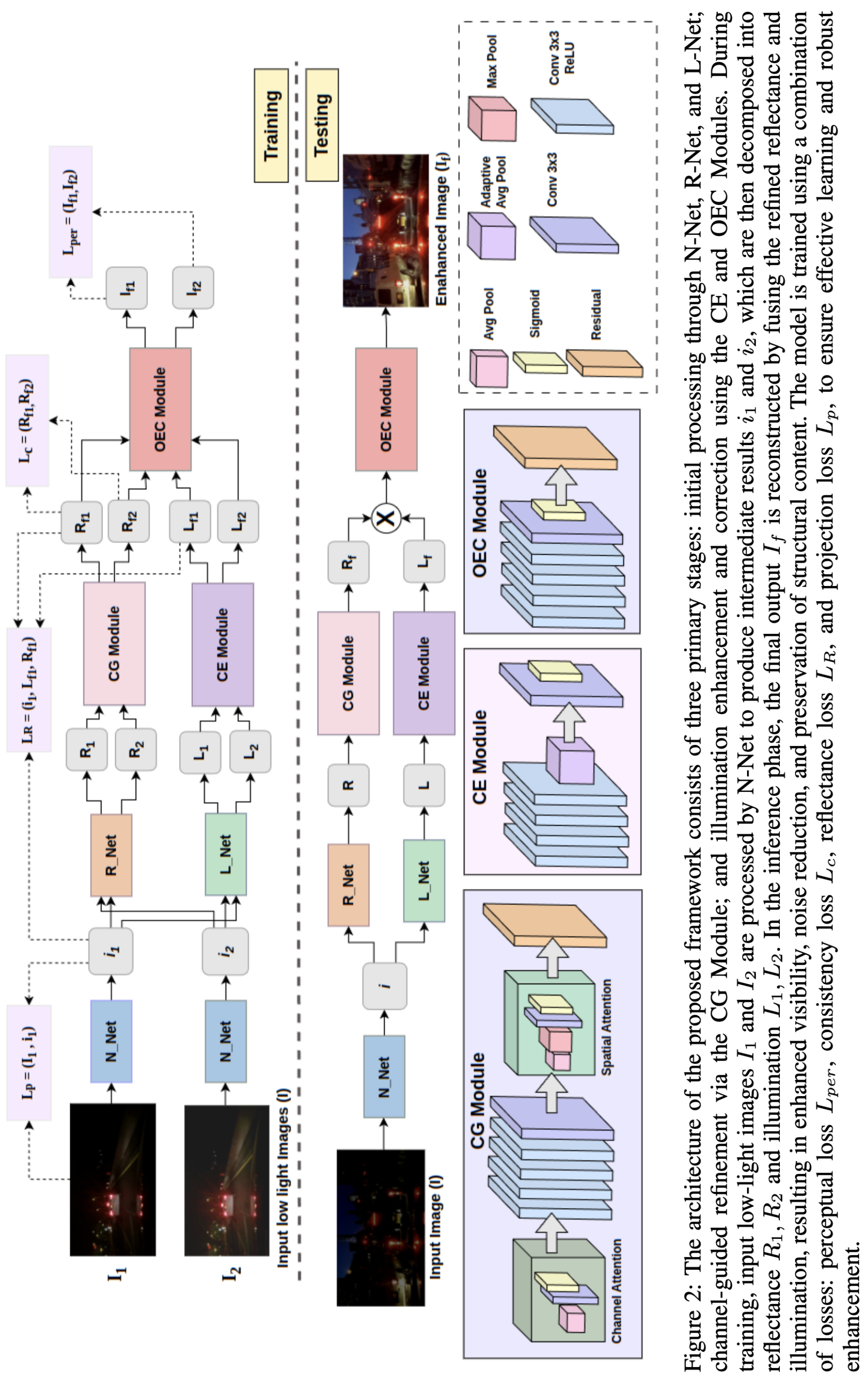
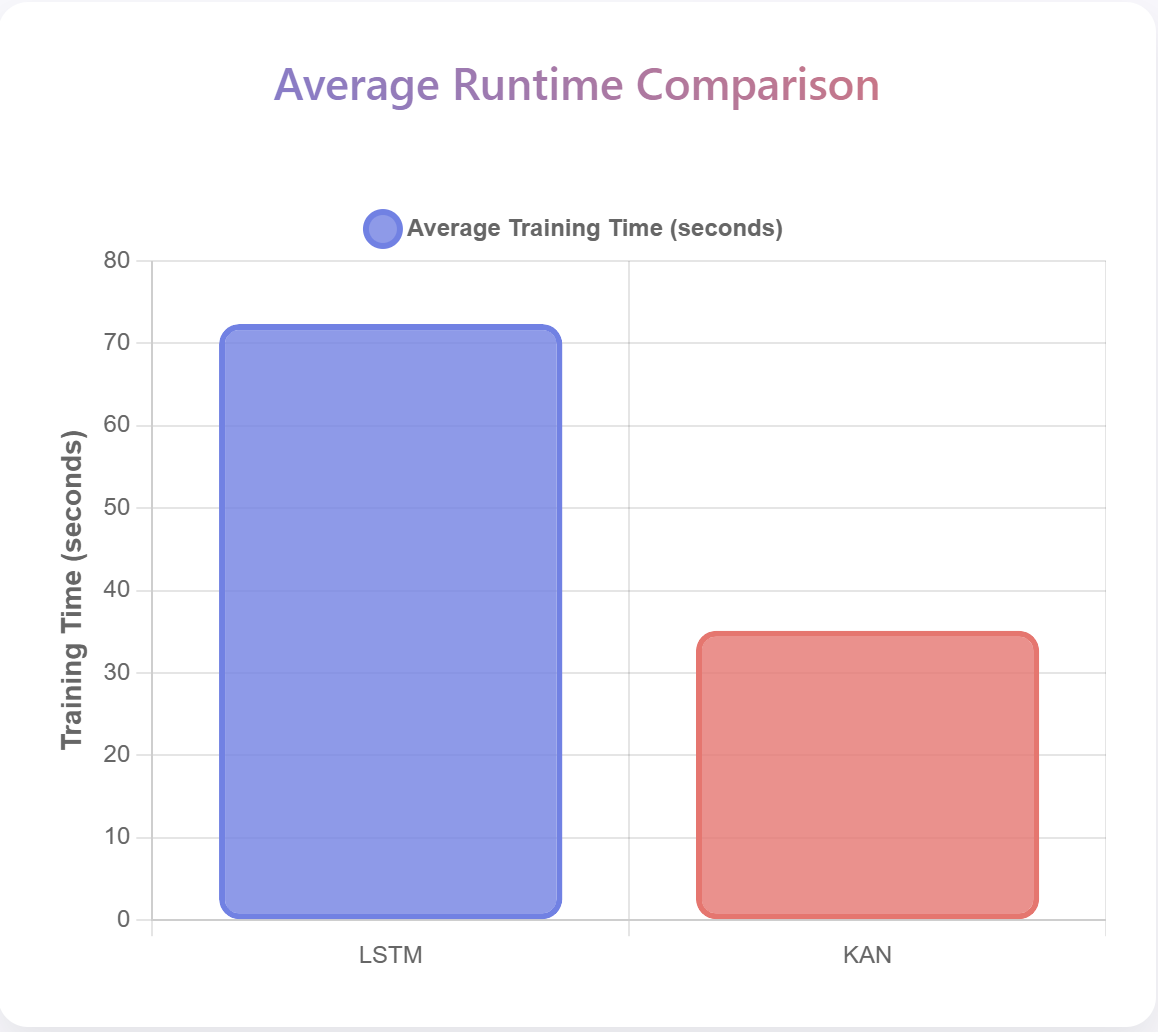
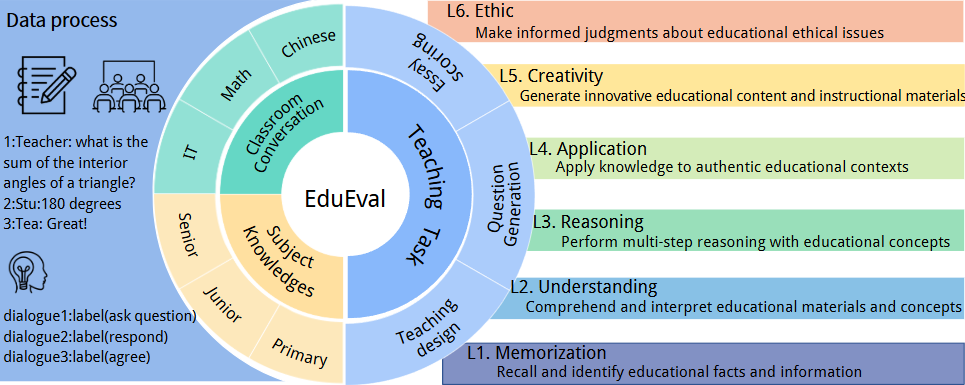
SR‑MCR: 자체참조 신호를 활용한 단계별 추론 정렬 프레임워크
Multimodal LLMs often produce fluent yet unreliable reasoning, exhibiting weak step-to-step coherence and insufficient visual grounding, largely because existing alignment approaches supervise only the final answer while ignoring the reliability of the intermediate reasoning process. We introduce SR