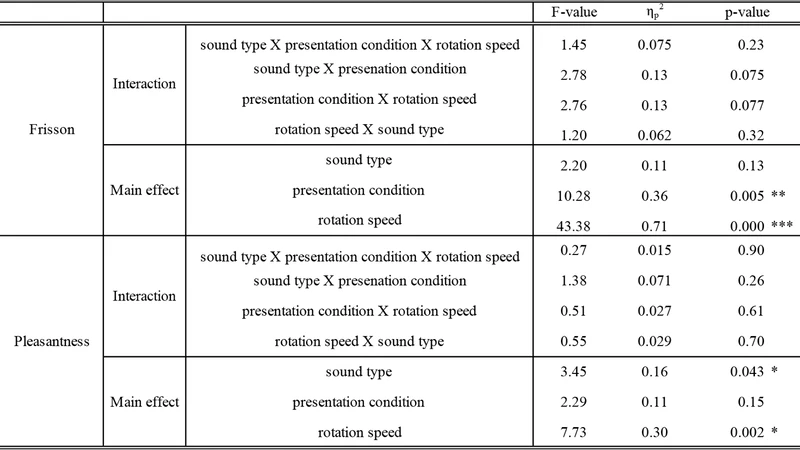
Eess-As

Emotion Recognition based on Third-Order Circular Suprasegmental Hidden Markov Model

Simulating Raga Notes with a Markov Chain of Order 1-2

A New Approach to Real Time Impulsive Sound Detection for Surveillance Applications

Classical Music Generation in Distinct Dastgahs with AlimNet ACGAN
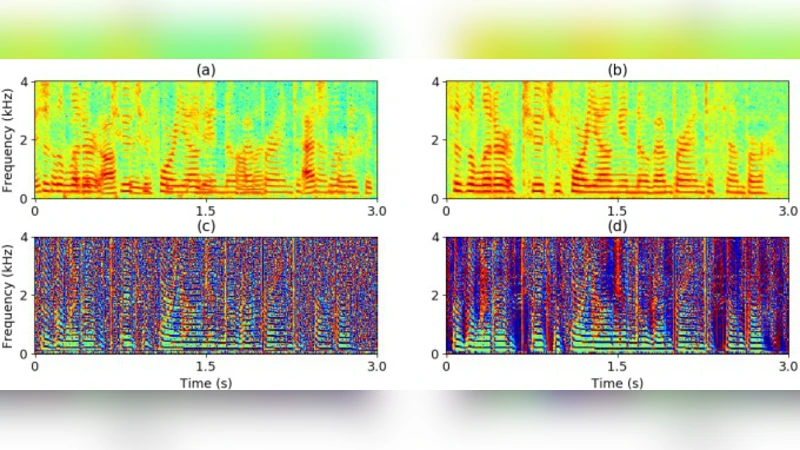
Deep Learning Based Phase Reconstruction for Speaker Separation: A Trigonometric Perspective

Practical Speech Recognition with HTK
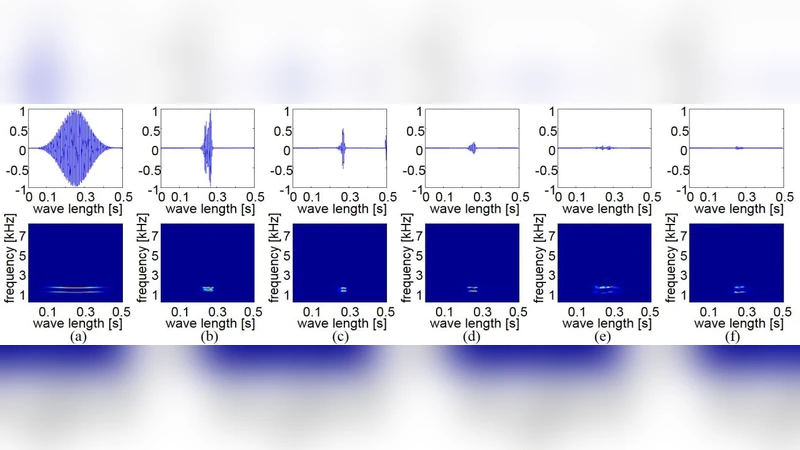
Sinusoidal wave generating network based on adversarial learning and its application: synthesizing frog sounds for data augmentation
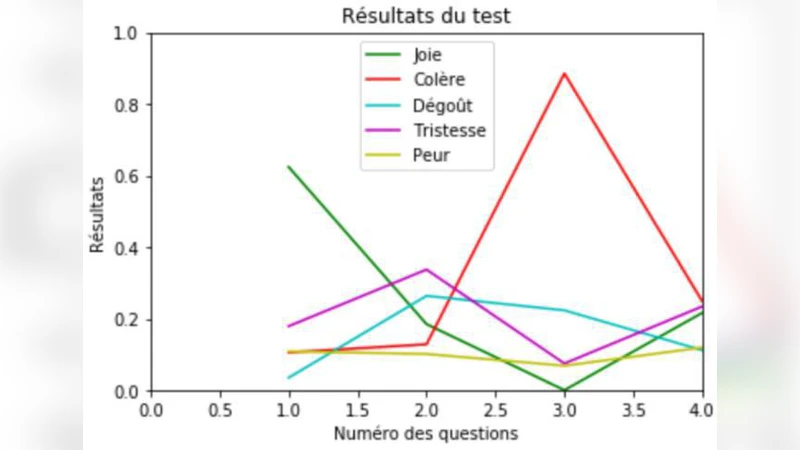
An Edge Computing Robot Experience for Automatic Elderly Mental Health Care Based on Voice

Improving Deep Speech Denoising by Noisy2Noisy Signal Mapping

LSTM Based Music Generation System

Machine learning for the recognition of emotion in the speech of couples in psychotherapy using the Stanford Suppes Brain Lab Psychotherapy Dataset
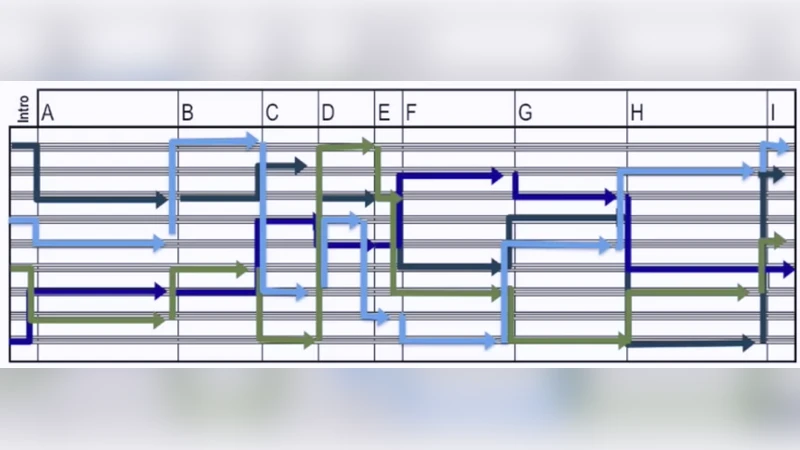
Current Trends and Future Research Directions for Interactive Music

Data Efficient Voice Cloning for Neural Singing Synthesis
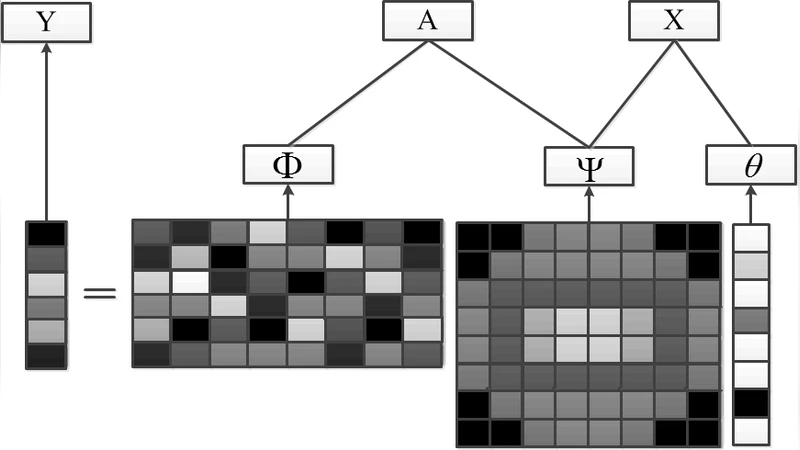
Music Genre Classification Using Spectral Analysis and Sparse Representation of the Signals
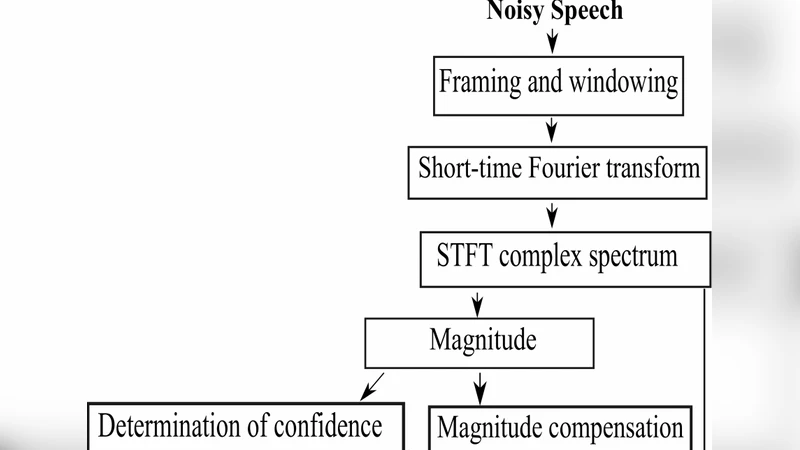
Enhancement of Noisy Speech with Low Speech Distortion Based on Probabilistic Geometric Spectral Subtraction
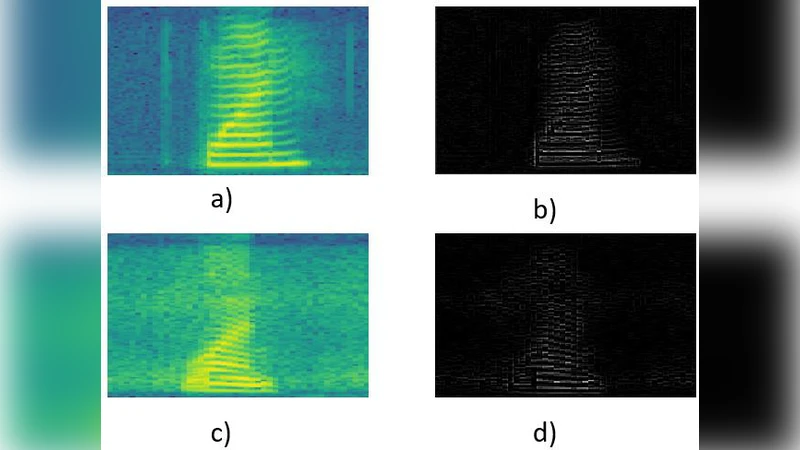
A Convolutional Neural Network model based on Neutrosophy for Noisy Speech Recognition
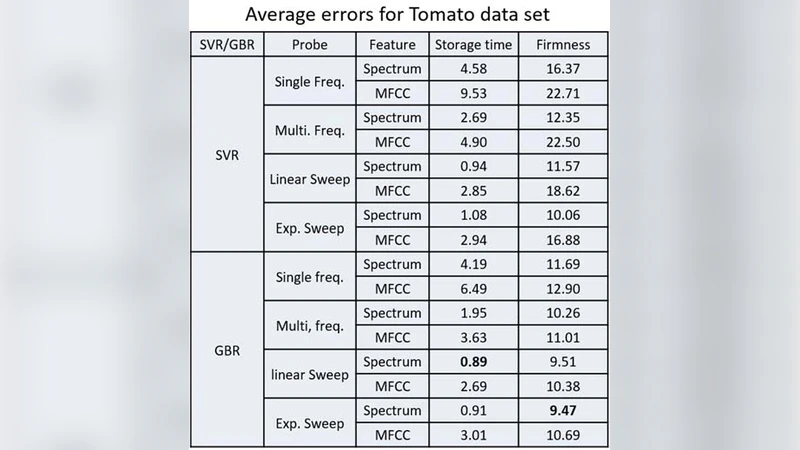
Acoustic Probing for Estimating the Storage Time and Firmness of Tomatoes and Mandarin Oranges

Quasi-Periodic WaveNet Vocoder: A Pitch Dependent Dilated Convolution Model for Parametric Speech Generation

New insights on the optimality of parameterized wiener filters for speech enhancement applications
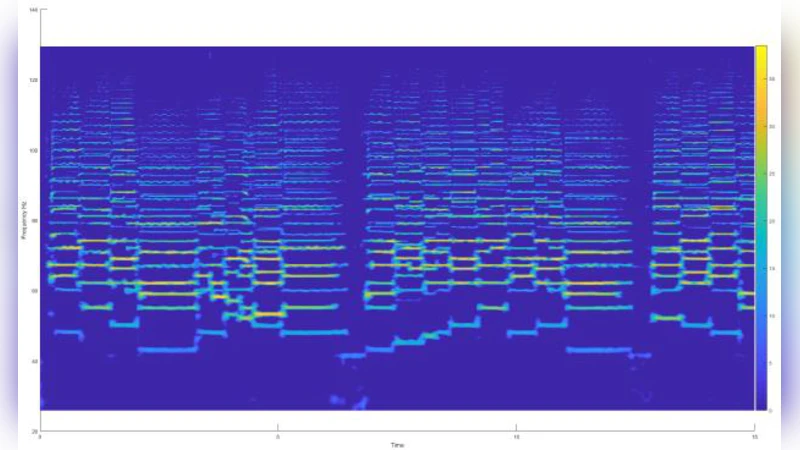
Polyphonic Pitch Tracking with Deep Layered Learning

Synchronizing Audio-Visual Film Stimuli in Unity (version 5.5.1f1): Game Engines as a Tool for Research

Beamforming and other methods for denoising microphone array data
