
Cs-Cv

One Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation

CIEC: Coupling Implicit and Explicit Cues for Multimodal Weakly Supervised Manipulation Localization

Data Augmentation for High-Fidelity Generation of CAR-T/NK Immunological Synapse Images

Can 3D point cloud data improve automated body condition score prediction in dairy cattle?

How Much Information Can a Vision Token Hold? A Scaling Law for Recognition Limits in VLMs

Beyond Translation: Cross-Cultural Meme Transcreation with Vision-Language Models

Creative Image Generation with Diffusion Models

SyNeT: Synthetic Negatives for Traversability Learning

EEO-TFV: Escape-Explore Optimizer for Web-Scale Time-Series Forecasting and Vision Analysis

From Sparse Decisions to Dense Reasoning: A Multi-attribute Trajectory Paradigm for Multimodal Moderation

DuoGen: Towards General Purpose Interleaved Multimodal Generation

TFFM: Topology-Aware Feature Fusion Module via Latent Graph Reasoning for Retinal Vessel Segmentation
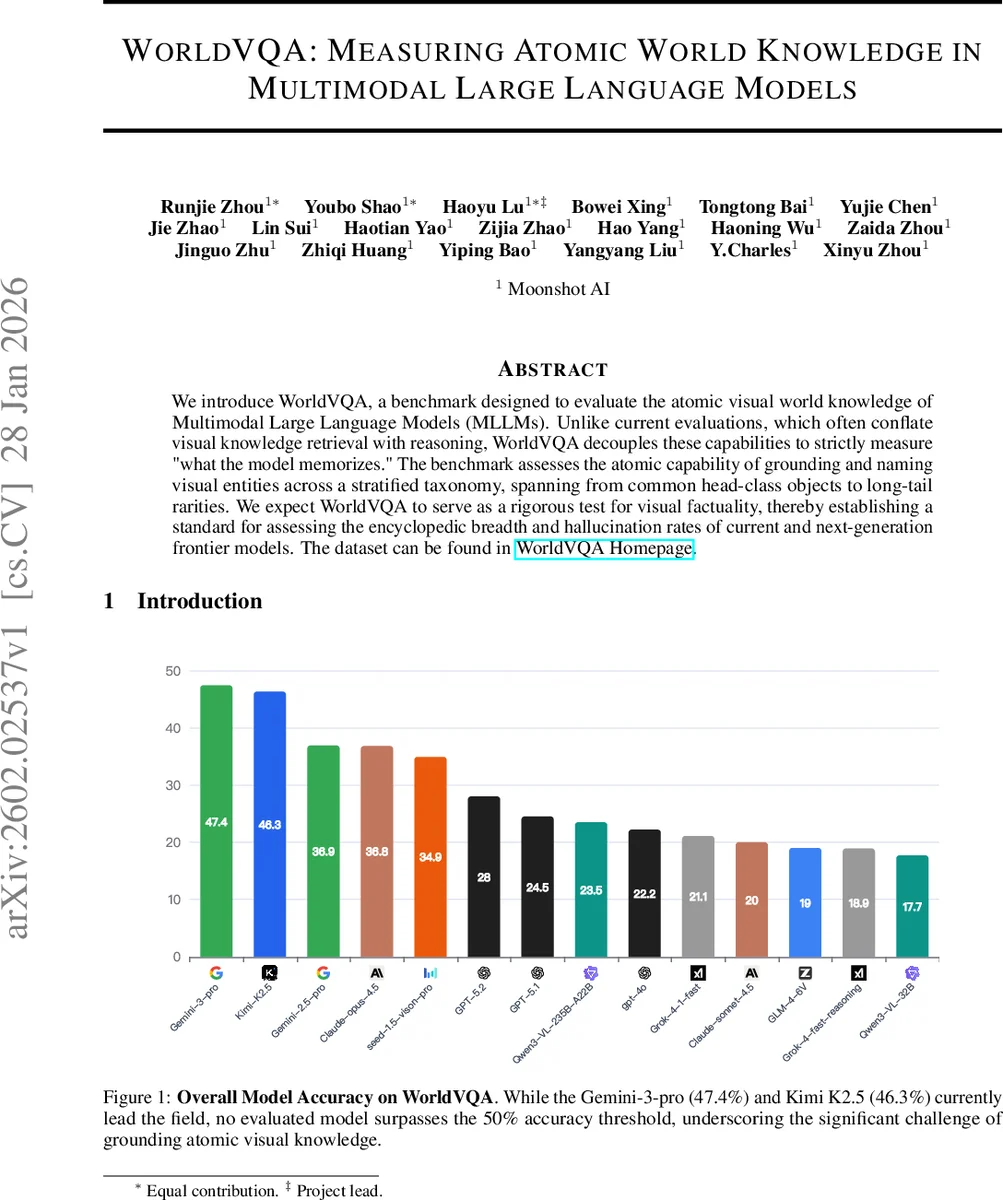
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models

ToolTok: Tool Tokenization for Efficient and Generalizable GUI Agents

Enhancing Post-Training Quantization via Future Activation Awareness

Making Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars

Shuffle Mamba: State Space Models with Random Shuffle for Multi-Modal Image Fusion

Helios 2.0: A Robust, Ultra-Low Power Gesture Recognition System Optimised for Event-Sensor based Wearables

HI-SLAM2: Geometry-Aware Gaussian SLAM for Fast Monocular Scene Reconstruction

Transferring Visual Explainability of Self-Explaining Models to Prediction-Only Models without Additional Training

CoT-RVS: Zero-Shot Chain-of-Thought Reasoning Segmentation for Videos

Entropy-Lens: Uncovering Decision Strategies in LLMs
