
Cs-Cv
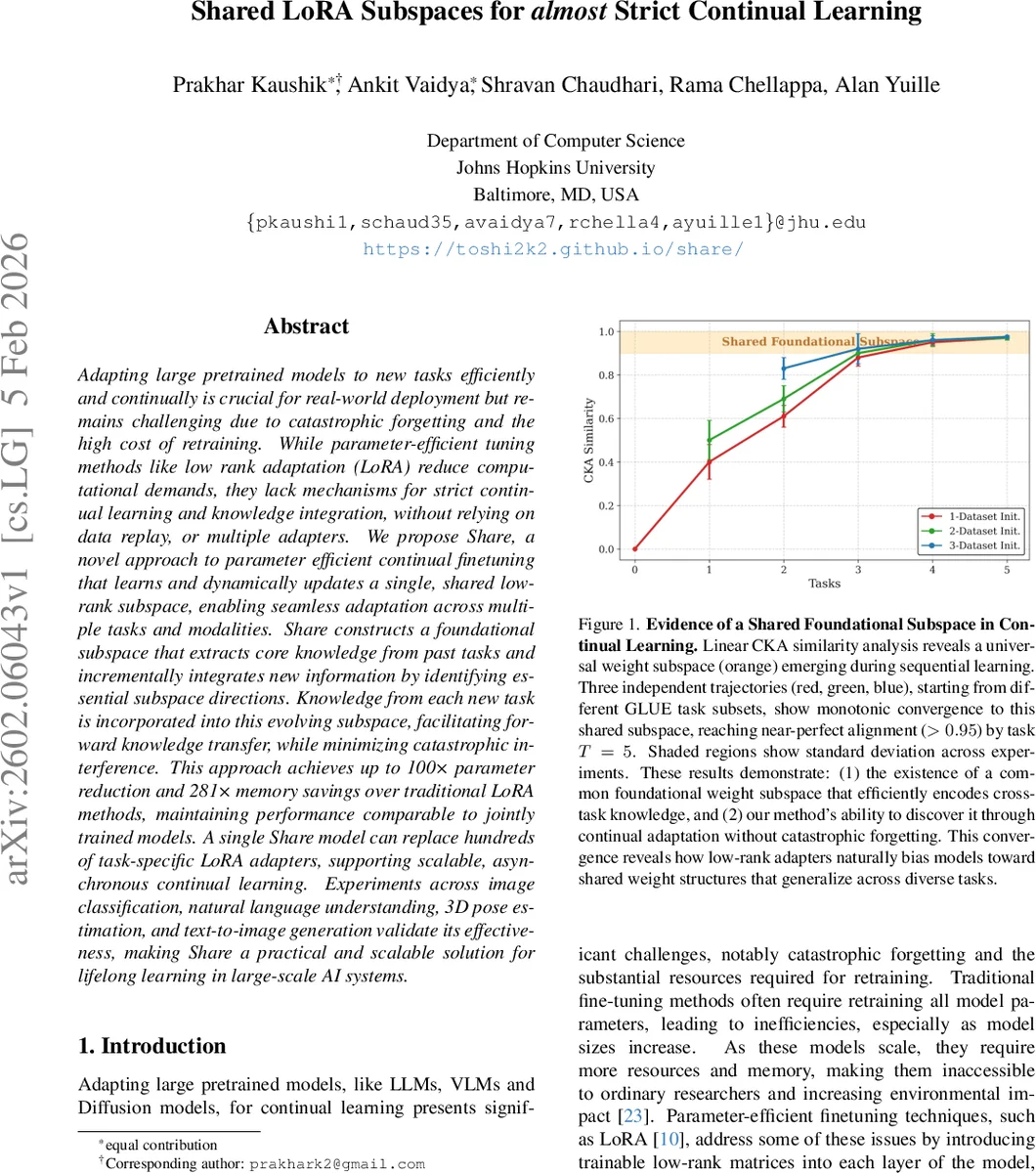
Shared LoRA Subspaces for almost Strict Continual Learning

RISE-Video: Can Video Generators Decode Implicit World Rules?
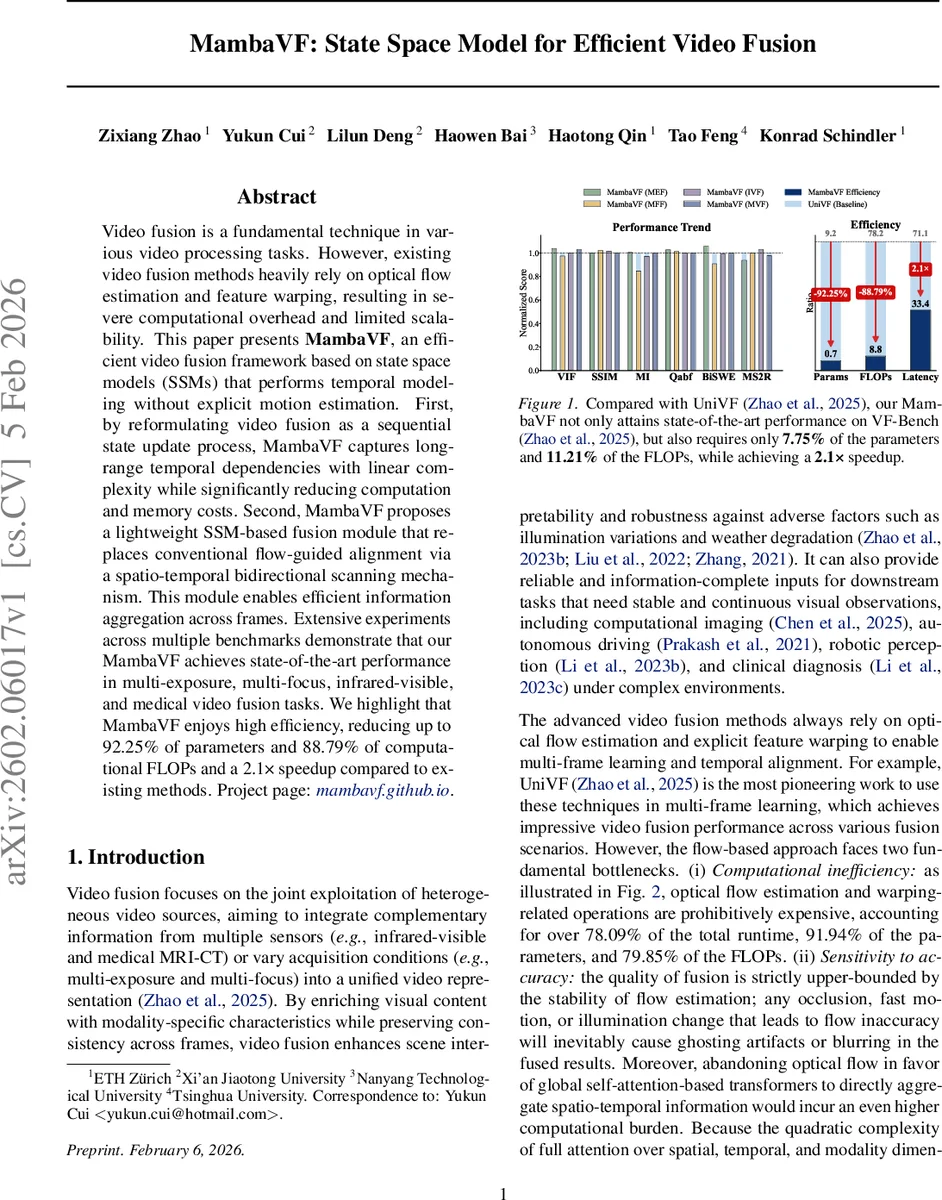
MambaVF: State Space Model for Efficient Video Fusion

VisRefiner: Learning from Visual Differences for Screenshot-to-Code Generation

CommCP: Efficient Multi-Agent Coordination via LLM-Based Communication with Conformal Prediction
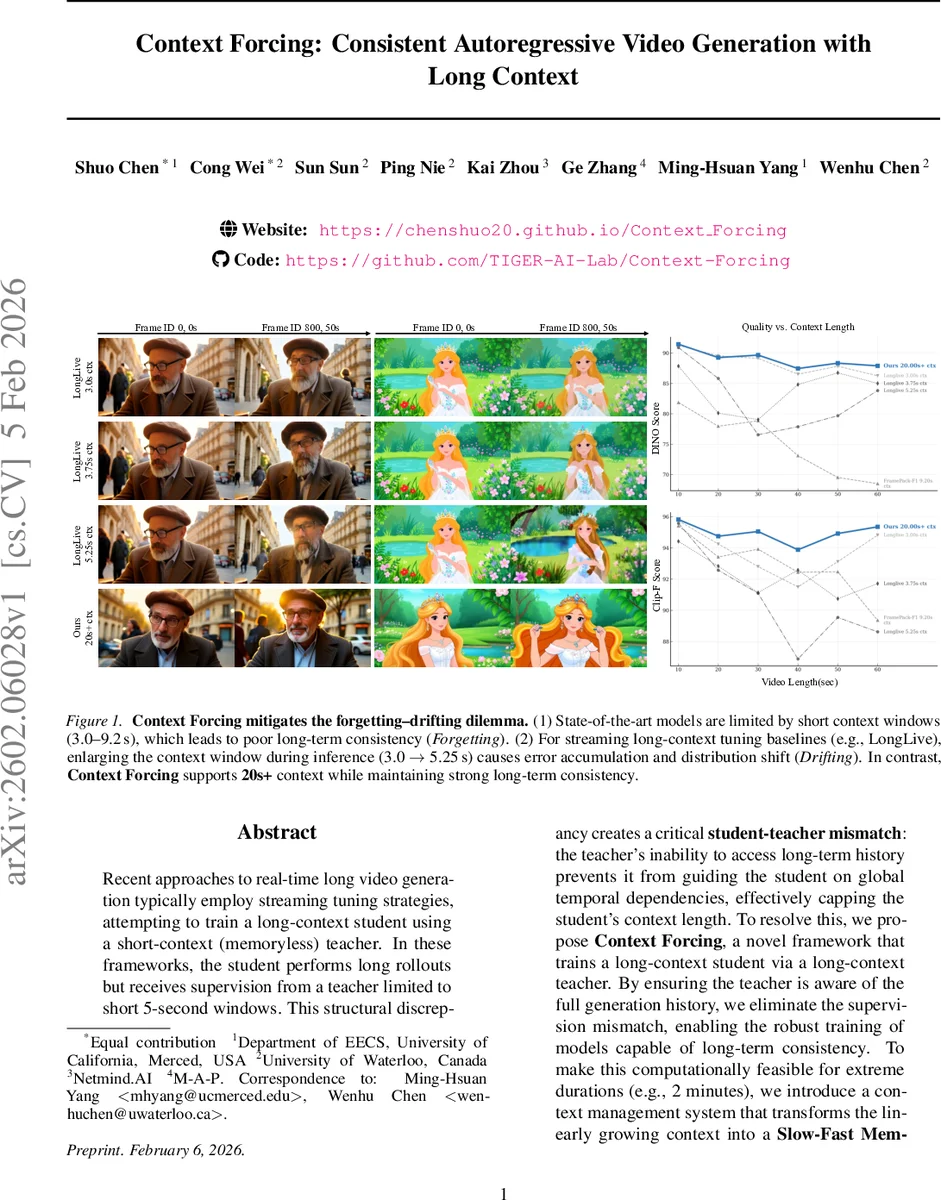
Context Forcing: Consistent Autoregressive Video Generation with Long Context

InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
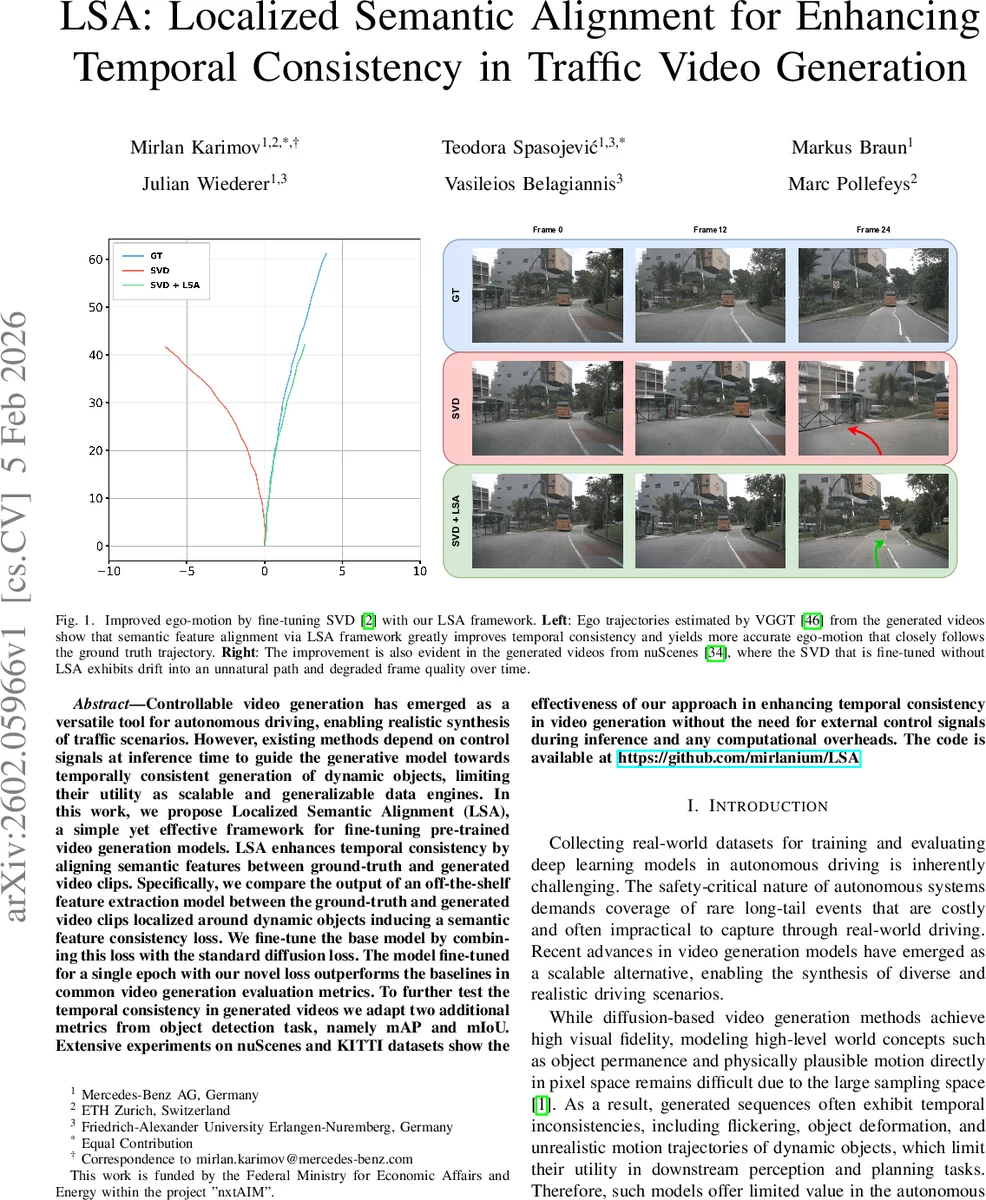
LSA: Localized Semantic Alignment for Enhancing Temporal Consistency in Traffic Video Generation

SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs

CLIP-Map: Structured Matrix Mapping for Parameter-Efficient CLIP Compression

Neural Implicit 3D Cardiac Shape Reconstruction from Sparse CT Angiography Slices Mimicking 2D Transthoracic Echocardiography Views

ALIEN: Analytic Latent Watermarking for Controllable Generation

PromptSplit: Revealing Prompt-Level Disagreement in Generative Models

An Example for Domain Adaptation Using CycleGAN

EgoAVU: Egocentric Audio-Visual Understanding

SPARK: Scalable Real-Time Point Cloud Aggregation with Multi-View Self-Calibration

From Blurry to Believable: Enhancing Low-quality Talking Heads with 3D Generative Priors

SVRepair: Structured Visual Reasoning for Automated Program Repair

Tempora: Characterising the Time-Contingent Utility of Online Test-Time Adaptation

Towards Real Zero-Shot Camouflaged Object Segmentation without Camouflaged Annotations

An Evaluation of Hybrid Annotation Workflows on High-Ambiguity Spatiotemporal Video Footage

DoRAN: Stabilizing Weight-Decomposed Low-Rank Adaptation via Noise Injection and Auxiliary Networks
