비모수 밀도 혼합 해제의 최적 이론과 실천
본 논문은 다수의 그룹에서 관측된 샘플을 이용해, 각 그룹이 K개의 비모수 밀도의 선형 혼합으로 표현된다는 가정 하에, 기본 밀도 \(g_1,\dots,g_K\) 를 추정하는 새로운 방법을 제안한다. 그룹별 가중치를 토픽 모델링으로 추정하고, 이를 U‑통계 기반으로 디바이어싱한 가중 커널 밀도 추정기를 설계한다. Nikol’ski 클래스에 속하는 밀도에 대해 적분 제곱 오차의 최소극대(미니맥스) 수렴률을 구하고, 동일한 조건에서의 하한을 증명해…
저자: Jianqing Fan, Zheng Tracy Ke, Zhaoyang Shi
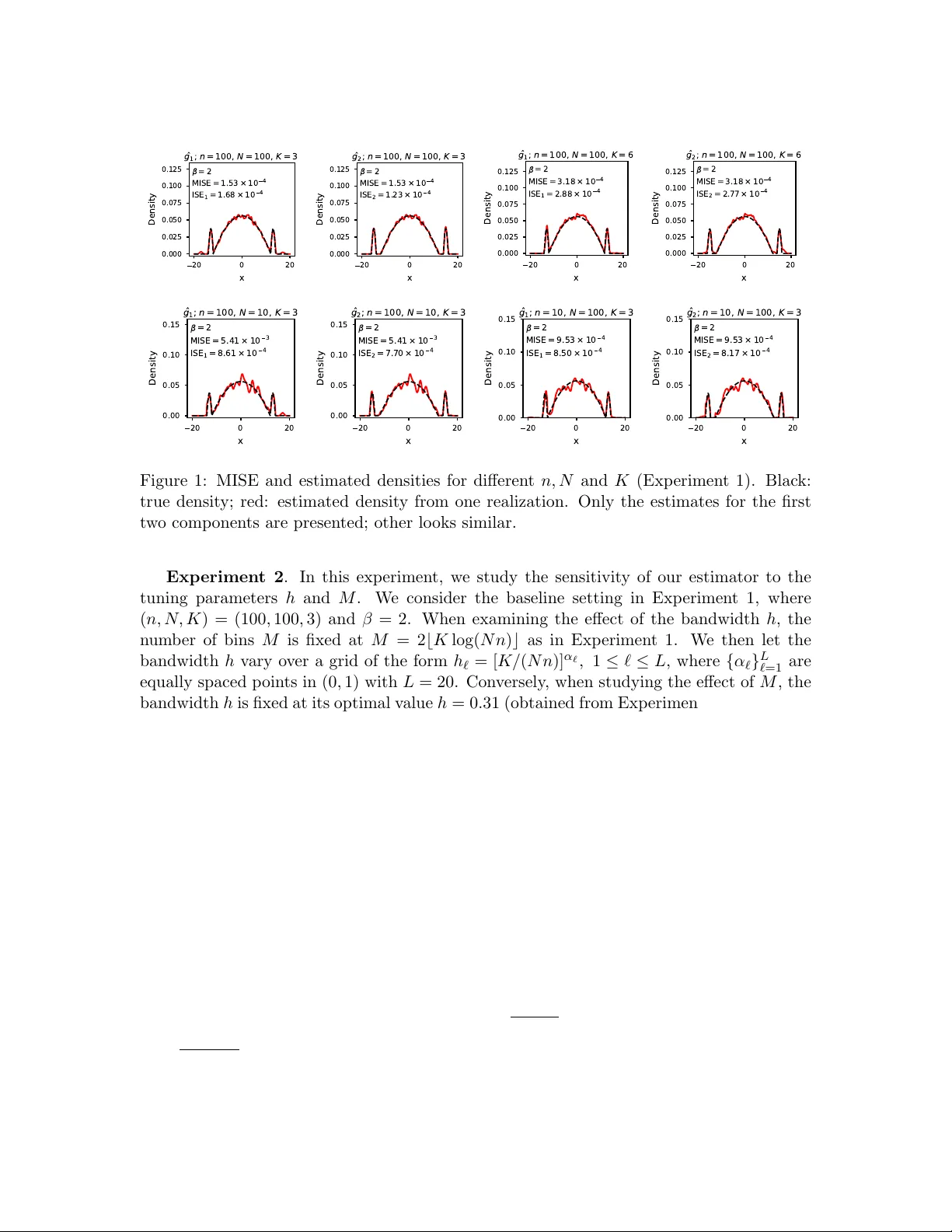
본 논문은 “비모수 밀도 혼합 해제”라는 새로운 통계적 문제를 정의하고, 이를 해결하기 위한 이론적·알고리즘적 프레임워크를 제시한다. 문제 설정은 다음과 같다. \(n\)개의 그룹이 존재하고, 각 그룹 \(i\)는 \(N_i\)개의 독립 샘플 \(\{X_{ij}\}_{j=1}^{N_i}\)을 관측한다. 이 샘플들은 \(d\)차원 공간에서 정의된 밀도 \(f_i(x)=\sum_{k=1}^K\pi_i(k)g_k(x)\) 로부터 생성된다. 여기서 \(g_k(x)\)는 우리가 추정하고자 하는 기본 비모수 밀도이며, \(\pi_i\in\Delta^{K-1}\)는 각 그룹의 혼합 비율을 나타낸다. 목표는 모든 그룹의 관측을 이용해 \(g_1,\dots,g_K\) 를 복원하는 것이다.
### 1. 기존 접근법의 한계
전통적인 커널 밀도 추정(KDE)은 각 그룹을 독립적으로 처리해 \(\hat f_i\) 를 얻는다. 그러나 \(\hat f_i\) 의 수렴 속도는 오직 \(N_i\) 에만 의존하므로, 전체 샘플 수 \(\sum_i N_i\) 를 활용하지 못한다. 또한, 비모수 혼합 모델을 직접 EM 방식으로 추정하려 하면, 각 \(g_k\) 를 파라메트릭 형태로 가정해야 하는 제약이 있다. 기존의 토픽 모델링 기반 방법(Austern et al., 2025)은 히스토그램을 만든 뒤 토픽 행렬을 추정하고, 이를 커널 스무딩해 밀도를 복원한다. 하지만 이 방법은 빈 수 \(M\) 를 \(N^{\alpha}\) 로 설정해야 하며, 고차원에서 최적의 수렴률을 달성하지 못한다.
### 2. 제안된 추정기 설계
논문은 세 단계로 구성된 새로운 추정기를 제안한다.
1. **Oracle 가중 KDE**: \(\Pi=
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기