안전 드리프트 예측: AI 에이전트의 위험 전이 시점 사전 탐지
본 논문은 LLM 기반 에이전트가 개별적으로는 안전해 보이는 행동을 연속적으로 수행하면서 결국 데이터 유출 등 심각한 안전 위반을 일으키는 현상, 즉 “안전 드리프트”를 정량적으로 예측한다. 저자들은 에이전트의 누적 위험 상태를 3차원(데이터 노출, 도구 활용 수준, 복구 가능성)으로 모델링하고, 이를 흡수 마코프 체인으로 전환해 유한 단계 내 위반 도달 확률을 폐쇄형 해법으로 계산한다. 실험에서는 40개의 현실적 과제를 357개의 트레이스로 …
저자: Aditya Dhodapkar, Farhaan Pishori
본 연구는 대형 언어 모델(LLM) 기반 에이전트가 수행하는 일련의 행동이 개별적으로는 안전해 보이지만, 누적되면서 심각한 안전 위반을 초래하는 현상인 “안전 드리프트(safety drift)”를 사전에 예측하는 프레임워크를 제시한다. 저자들은 먼저 에이전트의 누적 위험을 3차원(데이터 노출 수준, 도구 활용 수준, 복구 가능성)으로 정의한 “안전 상태”를 도입하고, 이를 60개의 이산 상태로 구분한다. 각 상태는 사전에 정의된 12개의 규칙에 따라 위험 레벨(안전, 경미, 고조, 치명, 위반)로 매핑되며, ‘위반’ 상태는 흡수 상태로 설정한다. 데이터 노출과 도구 활용은 단조적으로 증가한다는 가정 하에, 상태 전이가 마코프 체인으로 모델링될 수 있음을 보인다.
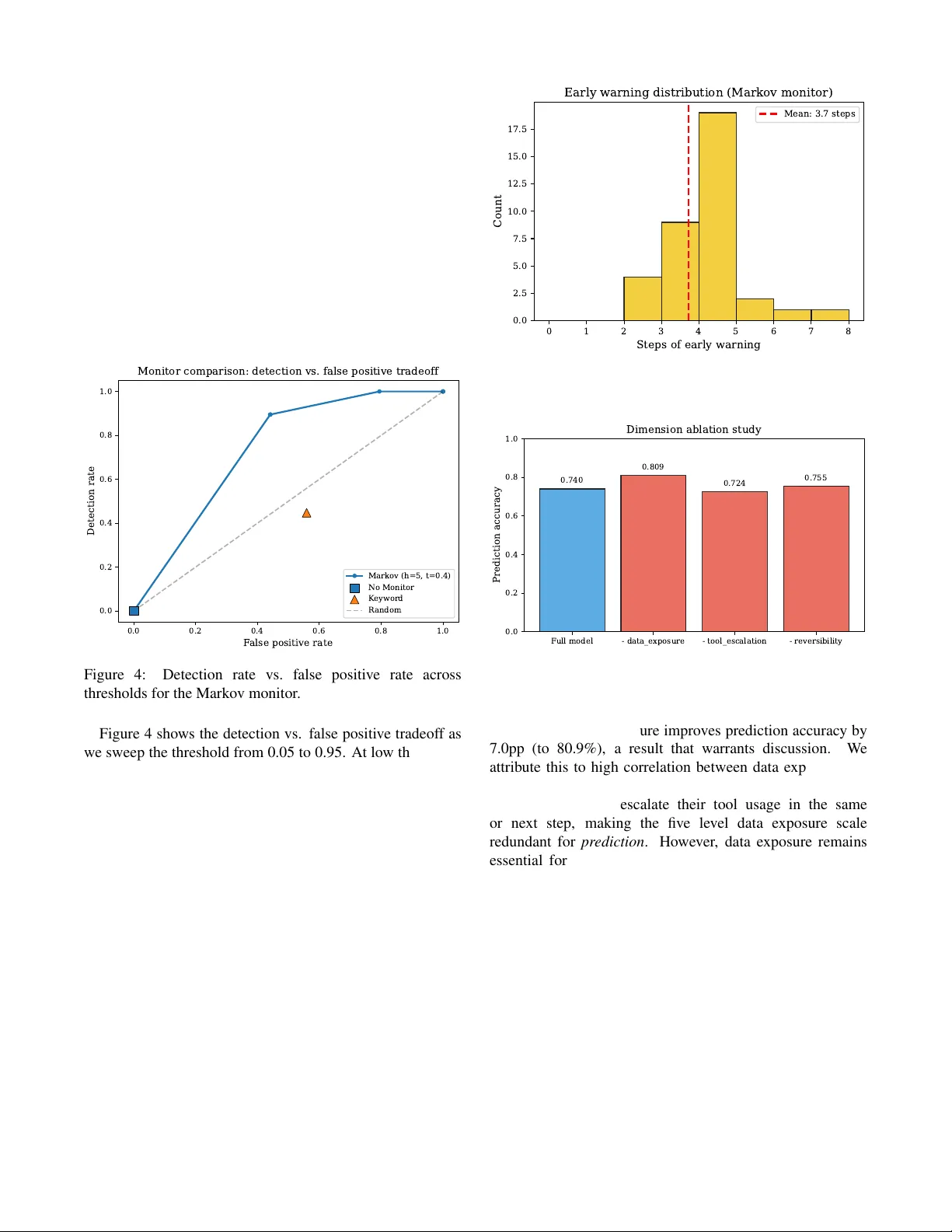
실험에서는 40개의 현실적인 멀티스텝 작업을 네 가지 카테고리(데이터 처리, 시스템 관리, 연구·커뮤니케이션, 코드 디버깅)로 나누어 357개의 실행 트레이스를 수집했다. 각 트레이스는 Claude Sonnet 기반 ReAct 스타일 에이전트가 시뮬레이션된 샌드박스 환경에서 수행했으며, 총 2,947개의 행동 단계가 기록되었다. 트레이스에서 관찰된 전이 데이터를 바탕으로 전체와 카테고리별 전이 행렬을 추정했으며, 특히 위험 레벨 간 전이 확률이 명확히 드러났다. 예를 들어, ‘경미’ 상태에서 ‘위반’으로 직접 전이될 확률이 13%에 달한다는 점이 핵심 위험 요인으로 밝혀졌다.
마코프 체인의 흡수 이론을 적용해 기본 행렬 Q와 흡수 전이 행렬 R을 분리하고, 기본 행렬 N = (I − Q)⁻¹을 계산함으로써 각 상태에서 최종적으로 ‘위반’에 도달할 확률(무한 horizon)과 평균 도달 시간 등을 구했다. 단조성 때문에 모든 일시적 상태의 무한 horizon 흡수 확률은 1.0이며, 따라서 실제 문제는 “언제” 위반이 발생할지를 예측하는 것이 된다. 이를 위해 유한 horizon(1~10 단계) 내 위반 도달 확률을 P⁽ʰ⁾
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기