프롬프트 구성요소가 LLM 성능에 미치는 영향: 회귀 기반 해석 프레임워크
본 논문은 프롬프트를 여러 층으로 분리하고, 각 층의 텍스트 구성요소를 이진 변수로 인코딩한 뒤 회귀 모델을 적용해 LLM의 출력 점수와의 관계를 정량화한다. Mistral‑7B와 GPT‑OSS‑20B 두 오픈소스 모델을 대상으로 3+2= 문제를 실험했으며, 개별 프롬프트 요소가 전체 성능 변동의 72%·77%를 설명한다. 잘못된 예시(오답 쌍)는 성능을 크게 저하시켰고, 긍정·부정 지시문은 효과가 일관되지 않아 상반된 영향을 보였다. 제안된 …
저자: Andrew Lauziere, Jonathan Daugherty, Taisa Kushner
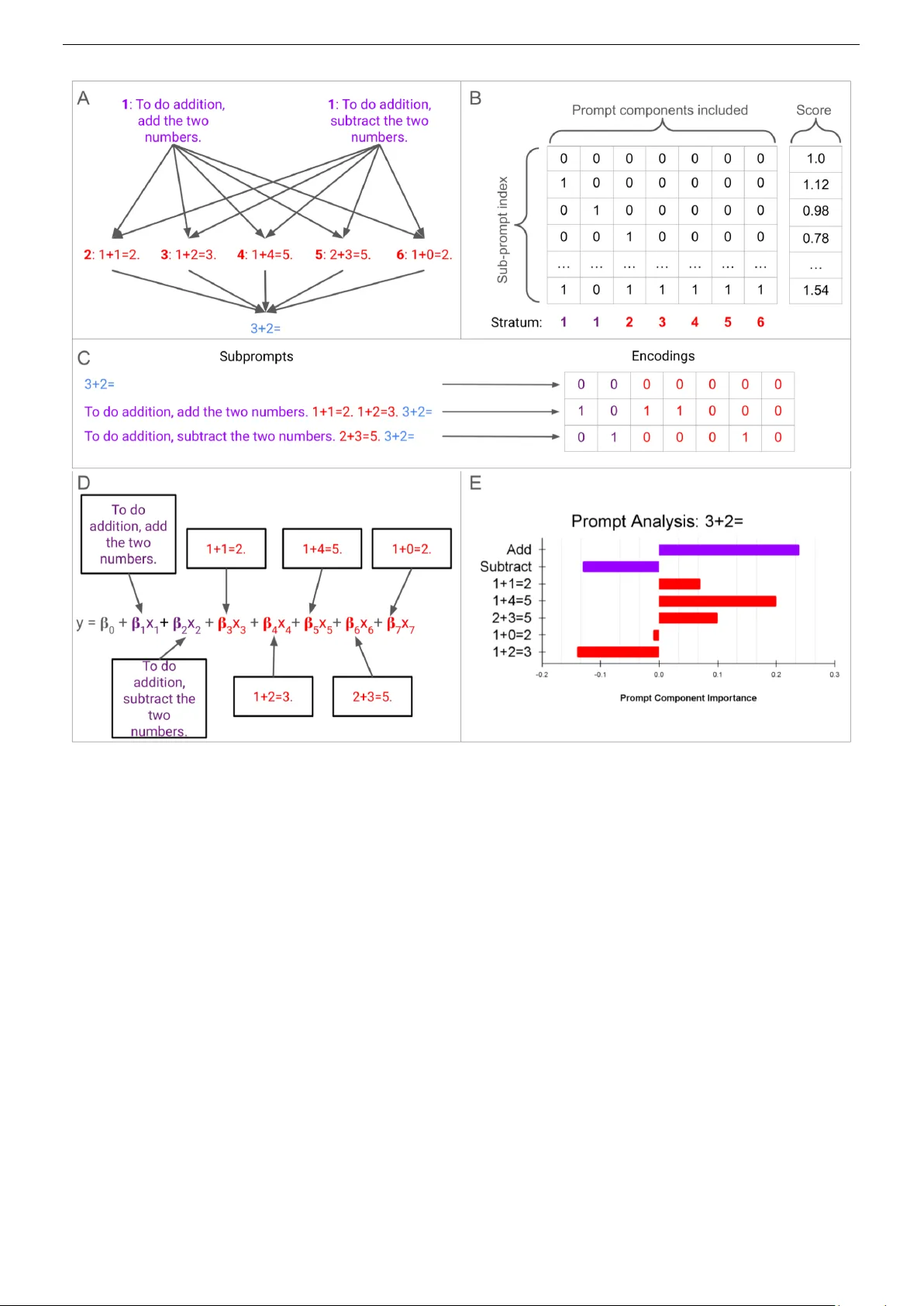
본 논문은 대형 언어 모델(LLM)의 성능을 좌우하는 프롬프트 구성요소를 체계적으로 분석하기 위한 통계적 프레임워크, IAMs(Interpretable Attribution Models)를 제안한다. 기존 XAI 기법인 LIME, SHAP 등을 모델‑불가지론적(local model‑agnostic) 방법으로 활용해 왔지만, LLM은 프롬프트라는 외부 텍스트 입력을 통해 ‘인‑컨텍스트 학습’이라는 독특한 메커니즘을 수행한다. 따라서 프롬프트 자체를 변수화하고, 그 변수가 모델 출력에 미치는 영향을 회귀 분석으로 정량화하는 접근이 필요했다.
프레임워크는 크게 네 단계로 구성된다. 첫째, 프롬프트를 ‘스트라텀(stratum)’이라는 층으로 분해한다. 각 스트라텀은 정적(예: 질문 자체) 혹은 가변(예: 설명 문구, 예시 쌍) 텍스트 선택지를 포함한다. 둘째, 각 선택지를 원‑핫 인코딩해 이진 더미 변수로 변환하고, 빈 문자열을 기준값으로 두어 디자인 매트릭스 X를 만든다. 셋째, LLM에 모든 가능한 서브프롬프트(각 스트라텀에서 하나씩 선택한 조합)를 입력하고, 사용자 정의 스코어링 함수로 출력 점수를 y에 매핑한다. 점수는 정답 토큰 확률(연속형) 혹은 정답 여부(이진형) 등으로 정의될 수 있다. 넷째, X와 y를 이용해 다중 회귀 혹은 로지스틱 회귀를 수행한다. 여기서 L1 정규화(Elastic‑Net)를 적용해 불필요한 변수와 교호작용을 자동으로 제거하고, 변수 선택을 수행한다. 또한, 전진 선택 알고리즘을 변형해 교호작용 항목이 하위 변수들이 모두 포함된 경우에만 모델에 추가하도록 함으로써 차원 폭발을 억제한다. 마지막으로, Shapley 값을 변형해 각 변수와 교호작용의 기여도를 공정하게 할당한다.
실험에서는 두 오픈소스 LLM, Mistral‑7B와 GPT‑OSS‑20B를 대상으로 ‘3+2=’라는 간단한 산술 질문을 사용했다. 프롬프트는 (1) 작업 설명 텍스트 두 가지, (2‑6) 다섯 개의 예시 쌍(정답·오답 포함)으로 구성된 총 7개의 스트라텀으로 나뉘었다. 각 스트라텀에서 하나씩 선택하거나 선택하지 않아 총 2 × 2⁵ = 64개의 서브프롬프트를 생성했고, 이를 두 모델에 입력해 정답 토큰 ‘5.’의 확률을 스코어로 사용했다. 회귀 분석 결과, Mistral‑7B는 R² = 0.72, GPT‑OSS‑20B는 R² = 0.77을 달성해 프롬프트 요소가 성능 변동을 크게 설명한다는 것을 확인했다.
주요 결과는 다음과 같다. 첫째, 오답 예시(예: ‘2+2=5’)를 포함하면 두 모델 모두 정답 확률이 현저히 감소한다. 이는 LLM이 인‑컨텍스트 학습 시 제공된 예시를 강하게 학습해, 잘못된 예시가 전체 추론을 왜곡한다는 증거다. 둘째, 긍정적 지시문(‘정확히 답하라’)과 부정적 지시문(‘틀린 답을 말하지 마라’)은 일관된 효과를 보이지 않는다; 일부 조합에서는 성능이 향상되지만, 다른 조합에서는 오히려 감소한다. 이는 프롬프트 내 지시문의 의미가 모델마다 다르게 해석될 수 있음을 시사한다. 셋째, 작업 설명 텍스트의 두 변형은 모델 성능에 미치는 영향이 미미했으며, 이는 질문 자체가 가장 핵심적인 정보임을 나타낸다.
이러한 정량적 분석은 기존의 ‘프롬프트 엔지니어링’이 주로 경험적·정성적 접근에 의존하던 한계를 극복한다. IAMs는 프롬프트 설계 단계에서 위험 요소(예: 오답 예시)를 사전에 식별하고, 모델‑특정 최적 프롬프트 조합을 도출하는 데 활용될 수 있다. 또한, 회귀 모델에 L1 정규화를 적용함으로써 변수 선택과 해석 가능성을 동시에 달성한다. 향후 연구에서는 더 복잡한 작업(예: 다중 단계 추론, 코드 생성)과 대규모 모델(예: GPT‑4)에도 적용해 프롬프트‑모델 상호작용을 심층적으로 탐구하고, 자동화된 프롬프트 최적화 파이프라인을 구축하는 것이 목표이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기