메모가드 알파: 금융 예측 LLM의 기억 오염 신호를 멤버십 추론과 모델 간 불일치로 탐지·필터링
본 논문은 대형 언어 모델(LLM)이 과거 금융 데이터를 기억해 내는 현상, 즉 기억‑오염(look‑ahead bias)을 신호 수준에서 실시간으로 제거하는 프레임워크인 MemGuard‑Alpha를 제안한다. 멤버십 추론 공격(MIA) 5가지와 시간 근접성을 결합한 MemGuard Composite Score(MCS)와, 서로 다른 학습 컷오프 날짜를 가진 다중 모델 간 예측 차이를 이용하는 Cross‑Model Memorization Disa…
저자: Anisha Roy, Dip Roy
본 연구는 금융 분야에서 LLM을 활용한 알파 신호 생성이 과거 데이터의 기억(메모리)으로 인한 ‘look‑ahead bias’를 내포하고 있음을 지적한다. 기존 문헌은 GPT‑4o가 훈련 기간 내 S&P 500 종가를 거의 완벽히 기억한다는 사례를 들어, 이러한 기억이 실제 시장 예측이 아니라 과거 데이터를 재현하는 것에 불과함을 보여준다. 또한, 모델 규모가 커질수록 메모리 양이 증가하고, 이는 ‘스케일링 패러독스’로 이어져 대형 모델일수록 일반화 성능이 저하되는 현상이 보고되었다. 이러한 문제를 해결하기 위해서는 모델 재학습, 입력 익명화, 로그 디코딩 등 비용이 많이 들거나 정보 손실을 초래하는 방법을 넘어, 실시간 거래에 적용 가능한 저비용 솔루션이 필요하다.
MemGuard‑Alpha는 이러한 요구를 충족시키기 위해 두 가지 핵심 알고리즘을 제시한다. 첫 번째는 MemGuard Composite Score(MCS)이다. MCS는 다섯 가지 멤버십 추론 공격(손실 기반, Min‑K%, Min‑K%++, zlib 압축 비율, 레퍼런스 모델 차이)으로부터 얻은 점수를 특징으로 사용하고, 여기에 ‘시간 근접성’(예측 시점과 데이터가 훈련에 포함됐을 가능성 사이의 시간 차) 변수를 추가한다. 로지스틱 회귀 모델을 통해 이들 특징을 결합한 오염 확률을 산출한다. 실험에서는 단일 MIA만 사용할 경우 Cohen’s d가 0.39~1.37에 불과했으나, MCS는 d=18.57이라는 압도적인 구분력을 보였다. 이는 오염 신호와 순수 신호가 거의 완전히 구분된다는 의미이며, 실제 거래 시스템에서 임계값을 정교하게 튜닝할 필요 없이 높은 정확도로 오염을 탐지할 수 있음을 보여준다.
두 번째는 Cross‑Model Memorization Disagreement(CMMD)이다. 여러 LLM이 서로 다른 훈련 컷오프 날짜를 가지고 있다는 사실을 활용한다. 동일 프롬프트에 대해 여러 모델이 예측을 수행했을 때, 특정 시점 이전 데이터에 대한 예측이 모델마다 크게 다르면 이는 해당 정보가 일부 모델에만 학습되었음을 의미한다. 반대로, 모든 모델이 일관된 예측을 보이면 해당 신호는 모델이 일반화된 추론을 통해 도출한 것으로 판단한다. CMMD는 이러한 불일치를 정량화해 ‘불일치 점수’를 계산하고, 높은 점수는 오염 신호로 분류한다.
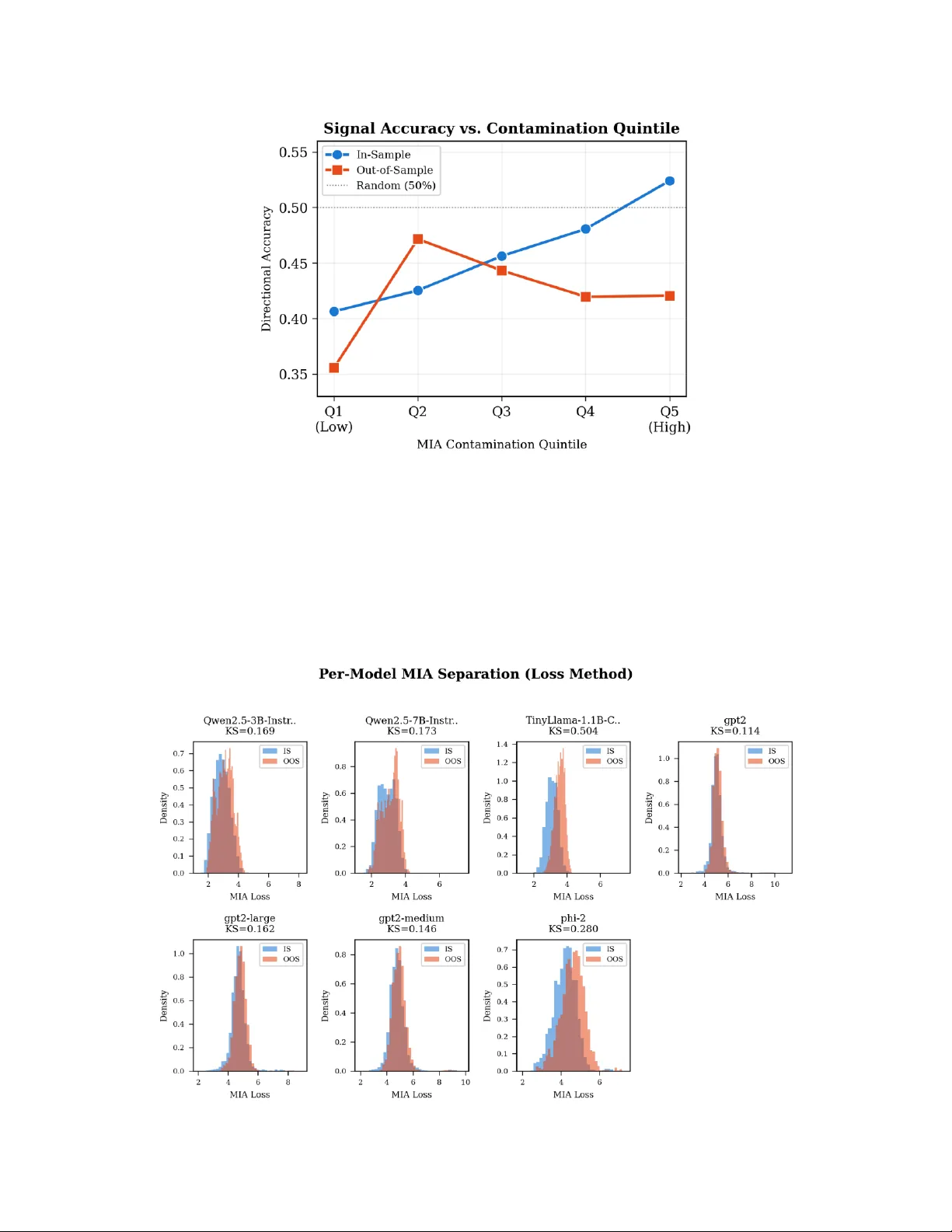
실증 검증은 50개 S&P 100 종목, 4 2800개 프롬프트, 5.5년(2019‑2024) 기간 데이터를 사용했으며, 124M~7B 파라미터 규모의 7개 LLM에 대해 동일 실험을 수행했다. 결과는 다음과 같다. (1) CMMD 기반 필터링 후 포트폴리오 샤프 비율은 4.11로, 필터링 전 2.76 대비 49% 향상되었다. (2) ‘클린’ 신호의 평균 일일 수익률은 14.48bps였으며, ‘오염’ 신호는 2.13bps에 불과해 7배 차이를 보였다. (3) 오염 정도가 증가할수록 인‑샘플 정확도는 40.8%→52.5%로 상승하지만, 아웃‑샘플 정확도는 47%→42%로 감소하는 교차 현상이 관찰되었다. 이는 기억‑오염이 과대 평가된 성과를 만들어내지만 실제 일반화 능력을 크게 저해한다는 강력한 증거이다.
논문의 주요 기여는 다음과 같다. (i) MIA와 시간 근접성을 결합한 MCS를 통해 기존 단일 MIA보다 10배 이상 높은 구분력을 달성했다. (ii) 모델 간 훈련 컷오프 차이를 활용한 CMMD를 제안해, 별도 재학습 없이도 실시간 신호 수준에서 오염을 제거했다. (iii) 7개 모델·50종목·4 2800프롬프트·5.5년 데이터를 아우르는 대규모 실증을 수행해, 실제 금융 환경에서의 적용 가능성을 입증했다. (iv) 인‑샘플·아웃‑샘플 정확도 교차 현상을 발견해, 기억‑오염이 어떻게 성과를 왜곡하는지 정량적으로 보여주었다.
한계점으로는 현재 공개된 LLM에 한정된 실험이며, 폐쇄형 상업 모델에 대한 적용 가능성 검증이 필요하다. 또한, 프롬프트 설계에 따라 MIA 점수와 불일치 점수가 변동할 수 있어, 프롬프트 민감도 분석이 추가로 요구된다. 향후 연구에서는 (1) 다양한 도메인(예: 신용 위험, 파생상품)으로 확장, (2) 실시간 스트리밍 데이터와 결합한 온라인 필터링, (3) 다중 모델 간 상관관계를 활용한 보다 정교한 불일치 메트릭 개발 등을 제안한다.
전반적으로 MemGuard‑Alpha는 비용 효율적이며 확장 가능한 방법으로, LLM 기반 금융 전략에서 기억‑오염으로 인한 look‑ahead bias를 실시간으로 탐지·제거함으로써, 보다 신뢰성 있는 알파 생성과 포트폴리오 성과 향상을 가능하게 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기