데이터와 지표가 세계 불평등 측정에 미치는 역할
본 논문은 Giovanni Andrea Cornia 교수의 업적을 기리며, 12개의 세계·지역 Gini 데이터베이스를 통합해 1867‑2024년 사이 222개 국가·지역의 122 000개 관측치를 구축한다. 복지 지표(소득·소비), 기준 단위, 하위 항목, 사후 조정, 설계 차이 등이 동일 연도·국가의 Gini값을 최대 50 포인트까지 차이 나게 함을 실증적으로 보여준다. 복지 지표 선택이 가장 큰 비불일치 원인이며, 하위 항목·동등화 규모도 …
저자: Lidia Ceriani, Paolo Verme
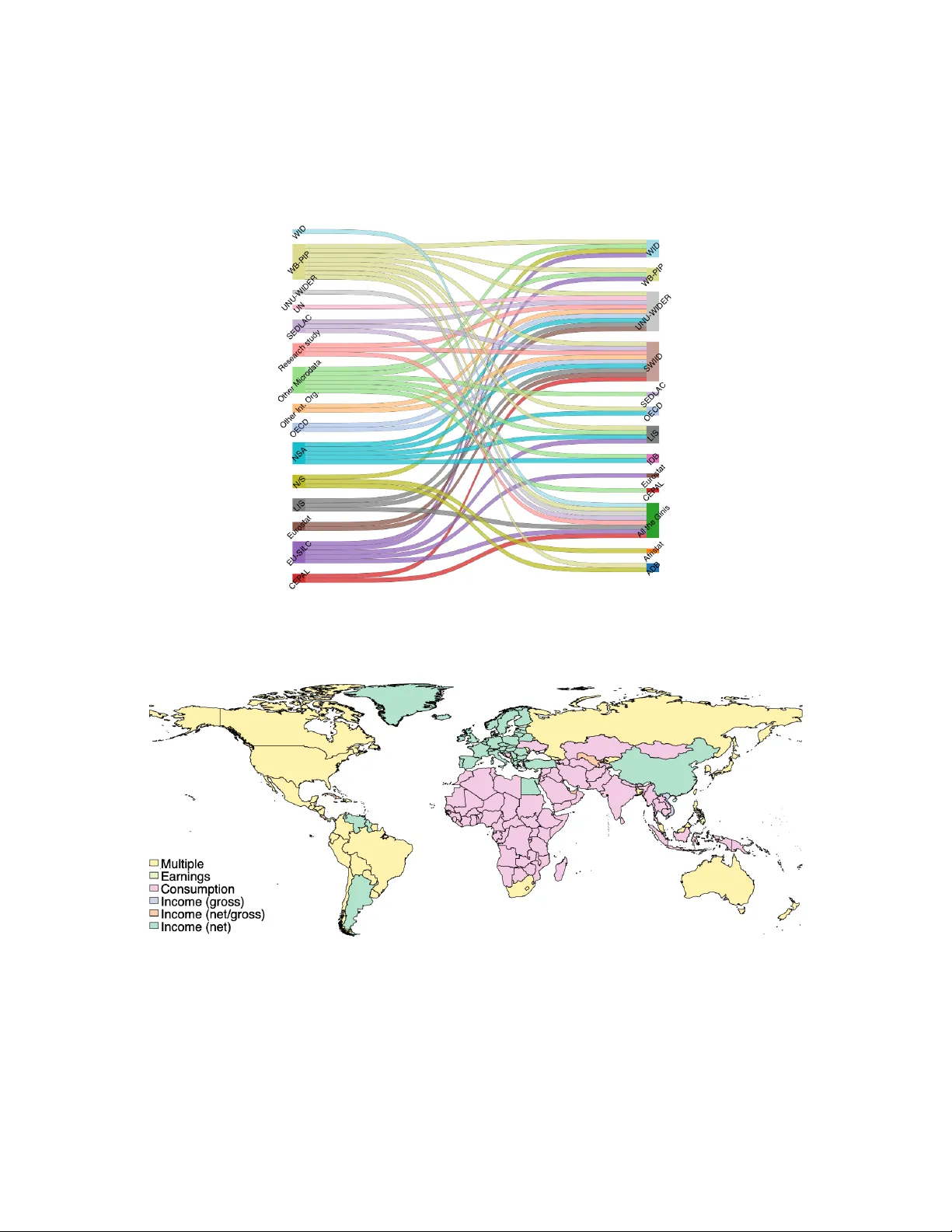
이 논문은 Giovanni Andrea Cornia 교수의 전 생애에 걸친 불평등 측정 연구를 기념하며, 세계 불평등을 정량화하는 핵심 지표인 Gini 계수를 중심으로 12개의 주요 세계·지역 데이터베이스를 종합·분석한다. 연구는 다음 다섯 가지 목표를 설정한다. 첫째, 각 데이터베이스의 수집·계산 방법론을 검토하고 차이점을 정리한다. 둘째, 데이터베이스 간 시간·공간적 커버리지를 시각화해 겹치는 부분과 빈틈을 파악한다. 셋째, 동일 국가·연도에 존재하는 Gini값 차이의 근본 원인을 규명한다. 넷째, 이러한 차이가 실제로 얼마나 큰 규모인지를 정량화한다. 마지막으로, 통합된 대규모 Gini 데이터베이스를 구축해 향후 연구의 기반을 제공한다.
데이터베이스는 ‘글로벌’과 ‘지역’으로 구분되며, 각각 ‘1차원(원시 설문·마이크로 데이터 기반)’과 ‘2차원(다른 연구·데이터베이스에서 재수집)’으로 나뉜다. 글로벌 1차원 데이터베이스에는 LIS, World Bank PIP, WID가 포함되고, 2차원에는 UNU‑WIDER WIID, All the Ginis, SWIID가 있다. 지역 1차원에는 CEPAL/ECLA, CEDLAS, IDB, Eurostat이 있으며, 2차원에는 OECD IDD, ADB KID, Afristat이 있다. 각 데이터베이스는 조사 기간, 지리적 범위, 복지 개념(소득·소비·총·순), 계층 구분(전체·도시·농촌·성별·연령), 집계 단위(가구·세대·개인), 기준 단위(인당·성인동등화·가구) 등에서 차이를 보인다.
연구팀은 이들 데이터를 모두 병합해 122 351개의 관측치를 만든다. 이 데이터는 1867년부터 2024년까지 222개 국가·지역을 포괄한다. 특히 2003‑2017년 기간은 거의 모든 데이터베이스가 겹쳐 가장 완전한 커버리지를 제공한다. 초기 전후 세계대전 시기와 1900년 이전은 주로 WID가 단일 출처로서 역할한다.
데이터 병합 과정에서 드러난 주요 문제는 ‘측정 사슬’ 전반에 걸친 불일치이다. 논문은 이를 여섯 가지 범주로 정리한다. 1) 설문 설계 – 소외 집단(수감자·노숙자·난민·내전 피난민) 포함 여부와 소득·소비 측정 기간(단기·장기) 선택. 2) 설문 시행 – 응답 오류·결측 처리 방식, 특히 고소득층 결측이 MAR·MNAR 형태일 경우 Gini가 하향 편향됨. 3) 복지 지표 – 소득 vs. 소비, 총소득 vs. 순소득, 혼합 지표 등. 4) 복지 하위 항목 – 정부 현금 이전, 연금, 임대료 추정, 가구 생산 등 포함 여부. 5) 기준 단위 – 인당, 성인동등화, 가구 기준 등. 6) 사후 조정 – 인플레이션 보정, 구매력 평준화, 결측 보정 등.
특히 복지 지표 선택이 가장 큰 변동성을 만든다. 동일 국가·연도에 대해 소득 기반 Gini가 소비 기반보다 평균 20‑30 포인트 높으며, 경우에 따라 50 포인트까지 차이가 난다. 이는 소득이 소비보다 더 불평등하게 분포되는 구조적 차이와, 측정 오류·결측이 소득에 더 크게 작용하기 때문이다. 지역별 분석에서는 저소득 국가(아프리카·남아시아)가 주로 소비 기반을 사용하고, 중·고소득 국가(북미·유럽·중국 등)는 소득 기반을 선호한다는 지리적·경제적 패턴이 확인된다.
복지 하위 항목 차이 역시 중요한 요인이다. Eurostat 데이터를 활용한 사례에서는 ‘사회 이전 전 가처분 소득’, ‘사회 이전 포함 가처분 소득(연금 포함)’, ‘사회 이전 포함 가처분 소득(연금·현물 포함)’ 세 가지 버전의 Gini가 각각 10‑30 포인트 차이를 보였다. 이는 데이터베이스마다 ‘가처분 소득’ 정의가 다름을 의미한다.
참조 단위와 사후 조정도 Gini값에 영향을 미친다. 예를 들어, 성인동등화 기준을 사용하면 가구 규모 차이에 따른 왜곡이 감소하지만, 일부 데이터베이스는 인당 기준만 제공한다. 또한, 결측치 보정 방법이 명시되지 않은 경우, 고소득층 결측이 Gini를 인위적으로 낮추는 효과가 발생한다.
통계적 분석에서는 데이터베이스 간 쌍별 평균 절대 차이가 0.12(표준편차 0.07)이며, 복지 지표 차이가 전체 변동성의 약 45 %를 차지한다. 지역·소득군별로는 아프리카·남아시아에서 소비 기반 Gini가 주류이며, 라틴아메리카·유럽·북미에서는 소득 기반이 우세함을 확인한다.
논문은 이러한 복잡성을 감안해 단일 Gini 수치를 정책·연구에 직접 활용하기보다, 복수의 Gini값을 병행 분석하고, 복지 지표·동등화·조정 방식 등 ‘측정 사슬’ 전체를 투명하게 공개할 것을 권고한다. 또한, 구축된 통합 데이터베이스를 공개함으로써 향후 연구자들이 보다 정교한 불평등 분석을 수행할 수 있는 기반을 제공한다. 이는 Cornia 교수가 강조한 ‘데이터의 질·투명성’과 ‘전 세계 비교 가능성’이라는 원칙을 현대 데이터 과학에 적용한 사례라 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기