순서형 분류를 위한 모델 독립형 풀링 기법
본 논문은 기존 비순서형 분류기를 순서형 회귀에 적용할 수 있는 모델‑agnostic 방법인 차분형(Classifier Pooling)과 트리형(Classifier Pooling) 두 가지 풀링 기법을 제안한다. Python 패키지 statlab을 오픈소스로 제공하여 sklearn 호환 분류기와 손쉽게 결합할 수 있다. 6개의 실제 데이터셋(의료, 자동차, 와인, 안과 영상, MNIST, 어베이놀)에서 실험한 결과, 특히 클래스 수가 많거나 데…
저자: Noam H. Rotenberg, Andreia V. Faria, Brian Caffo
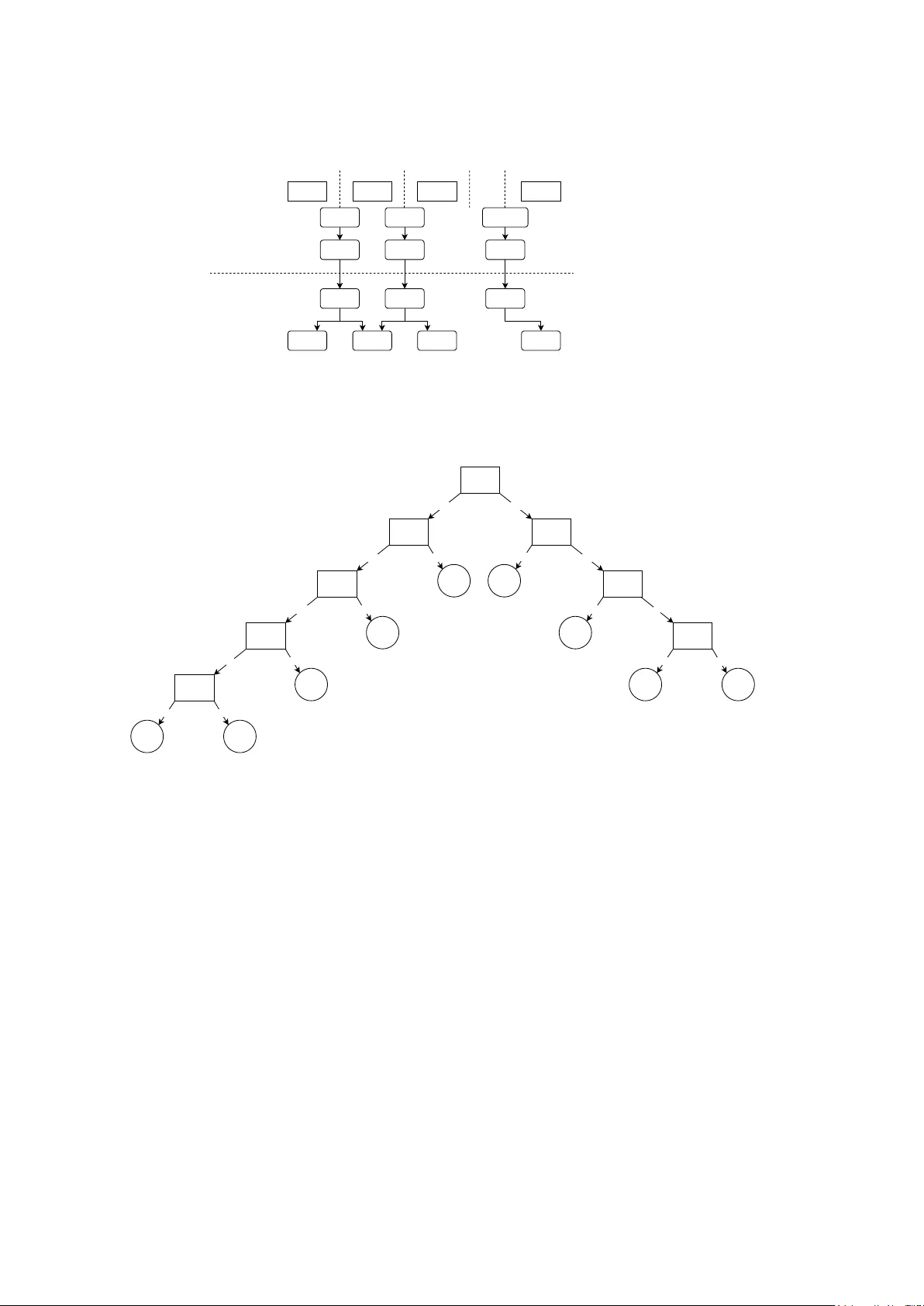
본 논문은 순서형 데이터가 임상, 설문, 이미지 등 다양한 분야에서 널리 사용됨에도 불구하고, 현대 머신러닝 기반의 순서형 회귀 방법과 공개 소프트웨어가 부족한 상황을 해결하고자 한다. 이를 위해 저자들은 모델‑agnostic한 두 가지 풀링 기법, 즉 차분형(Classifier Pooling)과 트리형(Classifier Pooling) 방법을 제안한다. 차분형은 각 인접 클래스 쌍 사이에 임계값을 두고, 해당 임계값을 초과하는지를 예측하는 이진 분류기들을 학습한다. 학습 단계에서는 전체 데이터셋을 사용해 각 임계값에 대한 이진 라벨을 재구성하고, 4‑fold 교차검증을 통해 가장 균형 잡힌(또는 검증 성능이 가장 좋은) 임계값을 “best split index”로 선정한다. 추론 단계에서는 인접한 두 임계값에 대한 예측 확률 차이를 계산해 각 클래스의 확률을 얻으며, monotonic constraint를 적용해 확률이 비단조적으로 변하지 않도록 보정한다. 이 과정은 전통적인 누적 로짓·프로빗 모델과 수학적으로 동등함을 증명했으며, 구현상 sklearn‑style API와 완벽히 호환된다.
트리형은 임계값을 이진 트리 구조로 배치하고, 각 노드에서 조건부 확률을 예측한다. 루트 노드(최적 split index)를 기준으로 좌·우 하위 노드로 순차적으로 조건부 확률을 곱해 최종 클래스 확률을 도출한다. 이 방식은 클래스 간 간격이 비균등하거나 데이터 불균형이 심한 경우에 특히 유리하다. 임계값 선택 전략으로는 첫 번째·마지막, 중앙, 균등 분할, 검증 기반 네 가지를 제안하고, 실험을 통해 검증 기반 방법이 가장 안정적인 성능을 제공함을 확인하였다.
저자들은 Python 패키지 statlab을 오픈소스로 제공하여, sklearn 호환 분류기(예: Logistic Regression, Gaussian Naïve Bayes, SVM, Gradient Boosting)와 손쉽게 결합할 수 있게 하였다. 또한 “BaseOrdinalClassifier”를 통해 예측 확률을 지원하지 않는 분류기에도 순서형 변환이 가능하도록 설계하였다.
실험은 6개의 실제 데이터셋(태아 심전도 기반 건강 데이터, 자동차 평가, 와인 품질, RetinaMNIST 기반 안과 영상, MNIST(비순서형 대조군), 어베이놀 나이 추정)에서 수행되었다. 데이터는 70 %/30 % 비율로 학습·평가 세트로 분할했으며, 일부 데이터셋은 이미지 수를 제한해 소규모 상황을 시뮬레이션하였다. 평가 지표는 정확도, 가중 역클래스 크기 정확도(AW), 다중 순서형 상관계수(PC), OVR‑AUC 등이다.
결과는 차분형과 트리형이 각각 75 %·79 %의 경우에서 기본 비순서형 모델을 능가했으며, 전통적인 순서형 로짓·프로빗 모델보다도 전반적으로 우수했다. 특히 클래스 수가 많고(6개 이상) 데이터가 제한된 상황(예: 어베이놀 소규모 샘플)에서 두 풀링 기법의 성능 향상이 두드러졌다. 트리형은 일부 데이터셋(예: 자동차 평가)에서 모든 지표에서 기존 모델을 앞섰으며, 차분형도 대부분의 경우에서 비슷하거나 더 나은 결과를 보였다. 또한 split index 선택에 있어 검증 기반 방법이 가장 일관된 성능을 제공함을 확인하였다.
본 연구는 순서형 회귀를 위한 현대적인 머신러닝 파이프라인을 구축하는 데 필요한 핵심 요소—모델 독립성, 쉬운 구현, 다양한 기본 분류기와의 호환성—를 모두 만족시키며, 오픈소스 패키지 제공을 통해 실무와 연구 현장에서 바로 활용할 수 있는 기반을 마련하였다. 향후 연구에서는 하이퍼파라미터 자동 튜닝, 딥러닝 기반 이진 분류기와의 결합, 그리고 대규모 멀티모달 데이터에 대한 확장성을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기