그룹 편향 탐지와 교정 이질적 처리 효과의 새로운 프레임워크
본 논문은 개별 수준에서 추정된 조건부 평균 처리 효과(CATE)를 그룹 수준으로 집계할 때 발생할 수 있는 체계적 편향, 즉 그룹 편향을 정의하고, 무작위 실험 데이터를 이용해 이를 검출·통계적 검정하는 방법을 제시한다. 또한, 편향을 최소화하는 폐쇄형 형태의 shrinkage 기반 교정 방식을 개발하고, 이 교정이 이익 극대화형 개인화 타깃팅에 미치는 경제적 영향을 분석한다. 대규모 디지털 플랫폼 실험 데이터를 통해 이론적 결과와 실증 성능…
저자: Joel Persson, Jurriën Bakker, Dennis Bohle
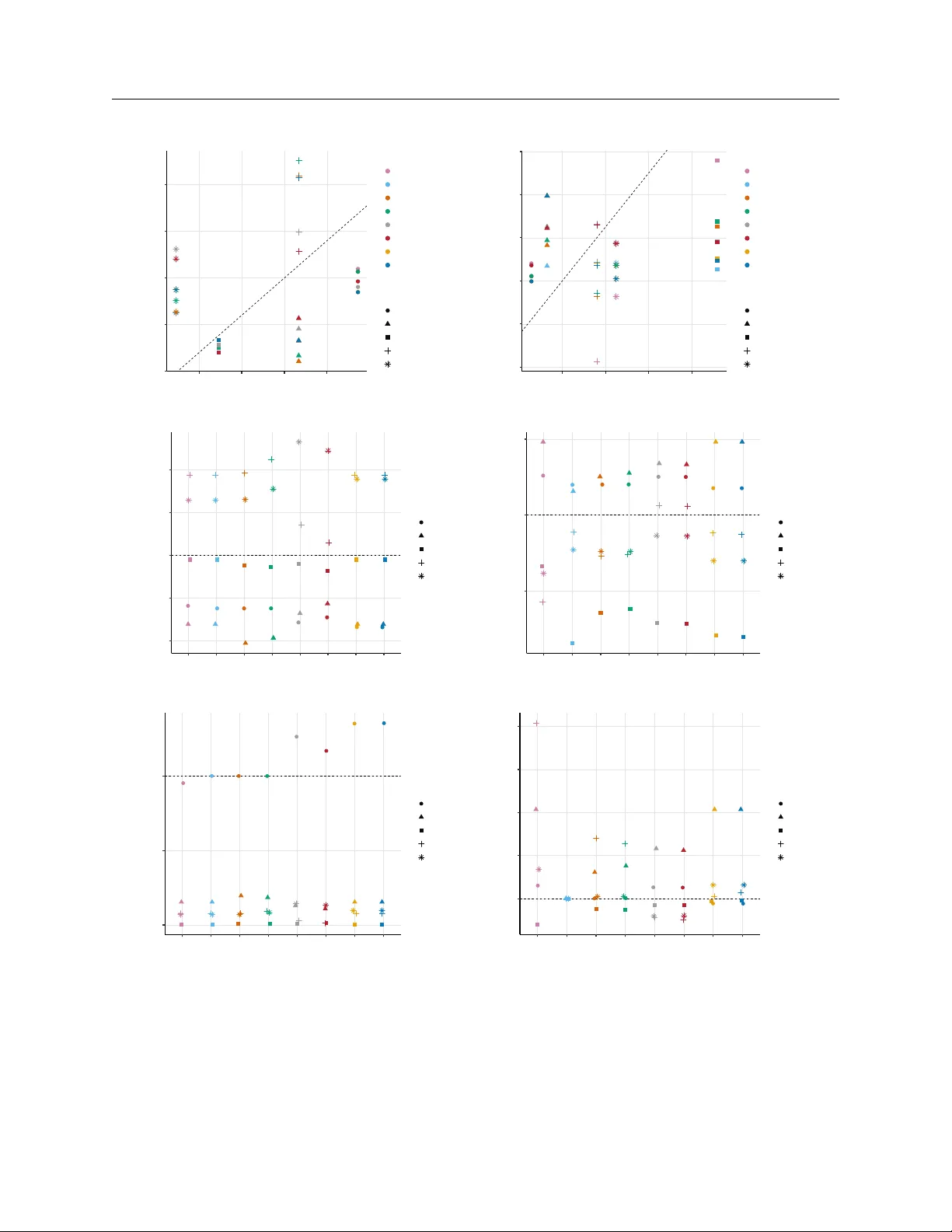
본 연구는 머신러닝 기반의 개별 수준 조건부 평균 처리 효과(CATE) 추정이 실제 비즈니스·정책 현장에서 흔히 수행되는 그룹 수준 평균 처리 효과(GATE) 집계 과정에서 발생할 수 있는 체계적 편향, 즉 “그룹 편향”을 정의하고, 이를 검출·완화하는 통계적 프레임워크를 제시한다.
첫 번째로, 저자는 그룹 편향을 “모델이 암시하는 GATE와 무작위 실험을 통해 비편향적으로 식별된 GATE 사이의 차이”로 정의한다. 이는 CATE 모델이 정확히 지정되고 무편향하게 추정되더라도, 개별 CATE를 단순 평균하거나 가중 평균하여 그룹 수준 효과를 얻을 때 collapsibility(조건부 효과의 가중 평균이 전체 효과와 일치해야 함) 조건이 깨질 경우 발생한다는 점을 강조한다.
그 다음, 그룹 편향을 추정하기 위한 점근적으로 정규분포를 따르는 추정량을 도출한다. 구체적으로 각 그룹 g에 대해 \(\hat\Delta_g = \frac{1}{n_g}\sum_{i\in g}\hat\tau_i - \hat\tau^{\text{exp}}_g\) 로 정의하고, 무작위 실험에서의 차이량이 평균 0, 분산은 표본 크기와 그룹 내 변동성에 의해 결정된다는 점을 이용해 중앙극한정리를 적용, \(\hat\Delta_g\)가 점근적으로 정규분포를 따른다는 정리를 증명한다. 이를 기반으로 표준오차를 추정하고, Z‑검정 혹은 Wald 검정을 통해 그룹별 편향 존재 여부를 검정한다. 검정은 이진·연속형 결과, 절대·상대 효과 척도 모두에 적용 가능하도록 일반화되었다.
교정 단계에서는 단순히 \(\hat\Delta_g\)를 빼는 “naïve correction”이 기대값에서는 편향을 없애지만, 표본이 작을 경우 과도한 보정으로 분산이 증가한다는 문제를 지적한다. 따라서 저자는 손실 함수 \(L(\delta_g)=\mathbb{E}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기