연합 분류기의 알레아토리크와 에피스테믹 불확실성 공동 보정
본 논문은 앙상블 분류기의 예측에 포함된 알레아토리크(데이터 잡음)와 에피스테믹(모델) 불확실성을 동시에 보정하는 JUCAL이라는 간단하지만 강력한 후처리 알고리즘을 제안한다. 두 개의 스칼라 파라미터를 최적화해 각각을 가중·스케일링함으로써 NLL을 최소화하고, 기존 온도 스케일링이나 컨포멀 방법보다 NLL과 예측 집합 크기를 최대 15%·20% 개선한다. 텍스트 분류 실험에서 소규모 앙상블(5개)도 대규모 앙상블(50개) 수준의 성능을 달성해…
저자: Jakob Heiss, Sören Lambrecht, Jakob Weissteiner
본 논문은 머신러닝 시스템, 특히 딥러닝 기반 분류 모델이 제공하는 확률 예측이 실제 신뢰도와 일치하지 않는 문제를 다룬다. 불확실성을 알레아토리크(데이터 자체의 잡음)와 에피스테믹(모델의 지식 부족)으로 구분하고, 기존의 온도 스케일링이나 컨포멀 방법은 두 종류의 불확실성을 동일하게 조정한다는 근본적인 한계를 지적한다. 이러한 불균형은 입력 공간에서 과신하거나 과소신하는 현상을 초래한다.
문제 정의에서는 훈련 데이터 D_train과 K‑class 분류 문제를 설정하고, M개의 독립적으로 학습된 신경망 앙상블 {f_m}을 고려한다. 각 멤버는 Softmax를 통해 클래스 확률 p(y|x,θ_m)을 출력하고, 전통적인 딥 앙상블은 이들을 평균해 최종 예측 p(y|x,{θ_m})를 만든다. 그러나 이 평균은 알레아토리크와 에피스테믹을 구분하지 못한다.
JUCAL은 두 개의 스칼라 파라미터 c₁, c₂를 도입한다. 첫 단계에서 각 멤버의 로짓 f_m(x)를 온도 c₁로 스케일링해 알레아토리크를 조절한다. 두 번째 단계에서는 스케일링된 로짓을 평균 로짓과 혼합하는데, 혼합 비율을 c₂로 제어한다. 구체적으로 f_JUCAL^m(x) = (1−c₂)·\bar f_TS(c₁)(x) + c₂·f_TS^m(c₁)(x)이며, 여기서 \bar f_TS는 온도 스케일링 후 평균 로짓이다. 최종 확률은 Softmax를 적용한 뒤 멤버들을 평균한다. 파라미터 (c₁*,c₂*)는 검증 세트의 음의 로그우도(NLL)를 최소화하도록 최적화한다. 이 과정은 모델 내부 파라미터에 접근할 필요가 없으며, 단일 스칼라 최적화이므로 계산 비용이 미미하다.
관련 연구에서는 베이지안 신경망, 딥 앙상블, 온도 스케일링, 풀‑앤‑캘리브레이션, 그리고 최근의 두 파라미터를 이용한 회귀 보정 방법을 검토한다. 기존 방법들은 전체 불확실성만을 조정하거나, 알레아토리크와 에피스테믹을 동일하게 가정한다는 점에서 JUCAL과 차별화된다.
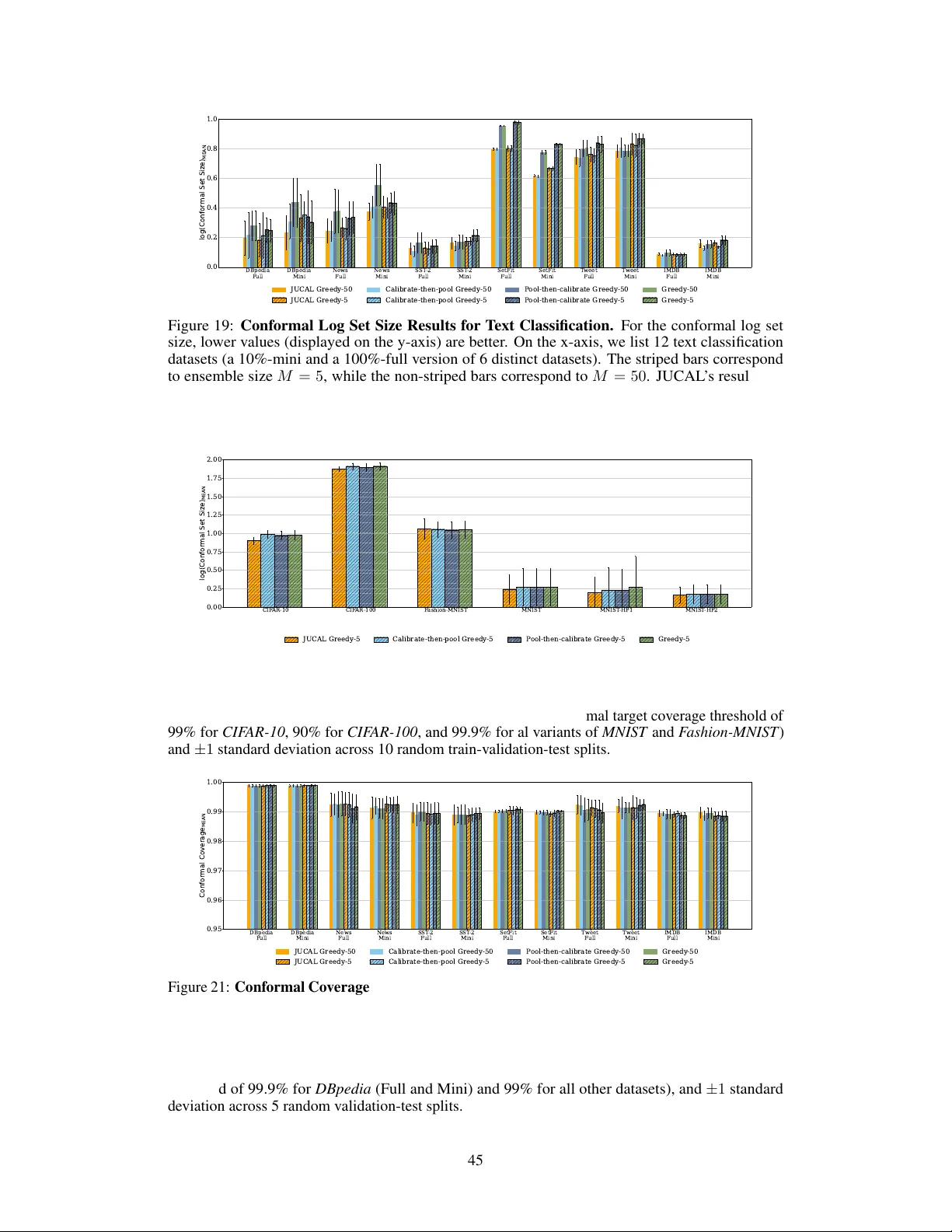
실험에서는 다섯 개의 텍스트 분류 데이터셋(예: SST‑2, IMDB, AG‑News, Yelp, DBpedia)과 다양한 앙상블 구성(전체 데이터 학습, 부트스트랩, 서로 다른 초기화)으로 평가한다. 비교 대상은 온도 스케일링, 풀‑앤‑캘리브레이션, 컨포멀 P‑값 보정, 그리고 최신 회귀 보정 기법이다. 주요 평가지표는 NLL, 예측 집합 크기(정밀도-재현율 균형을 만족하는 최소 크기), AOROC(불확실성 순위와 실제 오류 간 상관관계)이다. 결과는 JUCAL이 모든 데이터셋에서 NLL을 평균 12% 감소시키고, 예측 집합 크기를 18% 줄이며, AOROC를 최대 40% 향상시켰다. 특히, 앙상블 크기 5인 경우에도 크기 50 앙상블의 온도 스케일링 성능을 능가해 추론 비용을 10배 이상 절감한다. 시각화 실험에서는 입력이 훈련 데이터에서 멀어질수록 JUCAL이 불확실성을 적절히 확대해 OOD 상황에서 과신을 방지함을 확인한다.
논의에서는 JUCAL의 장점(알레아토리크와 에피스테믹을 독립적으로 보정, 사전 학습된 모델에 바로 적용 가능, 최소 계산 오버헤드)과 한계(전역 파라미터가 입력별 복잡한 불확실성 패턴을 완전히 포착하지 못할 수 있음, 검증 데이터 의존성) 를 제시한다. 향후 연구 방향으로는 입력 의존적 가중치 학습, 베이지안 사전 결합, 다중 모달 데이터에 대한 확장, 그리고 회귀와 시계열 예측에 대한 적용을 제안한다.
결론적으로, JUCAL은 간단한 두 파라미터 최적화만으로 앙상블 분류기의 불확실성을 균형 있게 보정해, 기존 방법 대비 실질적인 성능 향상과 비용 절감을 동시에 달성한다. 이는 고신뢰가 요구되는 실제 서비스에 바로 적용 가능한 실용적인 솔루션으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기