프리트레이닝 초기화가 파인튜닝 편향을 결정한다
본 논문은 대각선 선형 네트워크를 이용해 프리트레이닝‑파인튜닝 파이프라인을 이론적으로 분석한다. 초기 가중치 절대·상대 스케일(cₚₜ, λₚₜ)과 파인튜닝 읽기층 초기화(γ𝒻ₜ)가 네트워크를 네 가지 미세조정(regime) 중 하나로 몰아넣으며, 각 regime은 특징 학습·재사용 능력에 따라 일반화 오차가 달라진다. 작은 초기 스케일을 앞층에 두면 특징 재사용과 정제가 동시에 가능해, 프리트레이닝 특징이 부분적으로만 필요한 파인튜닝 작업에서 …
저자: Nicolas Anguita, Francesco Locatello, Andrew M. Saxe
**1. 서론**
현대 딥러닝은 대규모 일반 데이터로 사전 학습(pretraining)한 뒤, 특정 작업에 맞춰 미세 조정(fine‑tuning)하는 두 단계 파이프라인을 널리 사용한다. 이 과정에서 프리트레이닝 단계에서 학습된 특징을 재사용하고, 파인튜닝 단계에서 추가로 정제하거나 새로운 특징을 학습하는 것이 성공의 핵심이다. 그러나 초기 가중치가 이러한 특징 재사용·학습에 어떤 영향을 미치는지는 아직 체계적으로 이해되지 않았다. 기존 연구는 초기화가 ‘레이지(lazy)’와 ‘리치(rich)’ 학습 모드 사이를 전환한다는 점을 밝혀냈지만, 다단계 학습에 대한 확장은 부족했다.
**2. 관련 연구**
레이지와 리치 학습은 각각 커널 방식과 특징 학습 방식으로 구분된다. 초기 가중치의 절대·상대 스케일이 이 두 모드 사이를 연속적으로 이동시킨다는 최근 연구들을 바탕으로, 본 논문은 프리트레이닝‑파인튜닝 상황에서 이러한 스케일이 어떻게 작용하는지를 탐구한다. 또한, 대각선 선형 네트워크는 복잡한 비선형 모델의 핵심 현상을 분석하기 위한 트랙터블 모델로, 기존에 ℓ₂‑최소화(레이지)와 ℓ₁‑최소화(리치) 사이의 전이를 보여준다.
**3. 이론적 설정**
- **네트워크 구조**: 1‑hidden‑layer 대각선 선형 네트워크 f_{w,v}(x)=β(w,v)ᵀx, 여기서 β는 양·음 경로의 요소별 곱으로 정의된다.
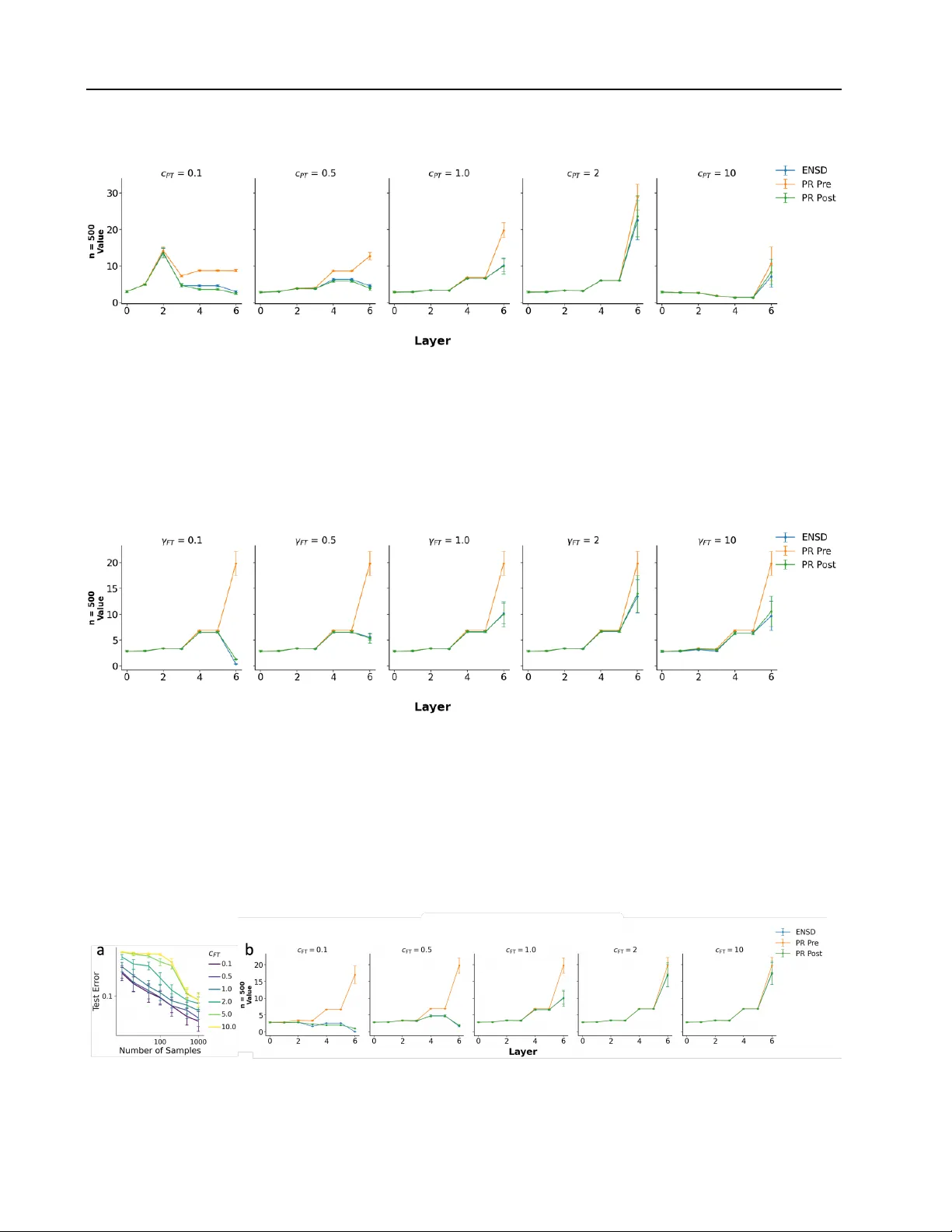
- **학습 절차**: 먼저 프리트레이닝 데이터 (Xₚₜ, yₚₜ)에서 gradient flow 로 0 오차에 도달하도록 학습하고, 이후 파인튜닝 데이터 (X𝒻ₜ, y𝒻ₜ)에서 동일한 방식으로 학습한다. 파인튜닝 시작 시 β를 0으로 재설정하고, 읽기층(v)만 γ𝒻ₜ 로 초기화한다.
- **초기화 파라미터**: 절대 스케일 cₚₜ = ‖wₚₜ(0)‖²+‖vₚₜ(0)‖², 상대 스케일 λₚₜ = (‖wₚₜ(0)‖²−‖vₚₜ(0)‖²)/cₚₜ, 파인튜닝 읽기층 스케일 γ𝒻ₜ.
- **데이터 생성 모델**: 교사‑학생 설정으로, 각 차원 d는 J개의 그룹 중 하나에 속하고, 프리트레이닝과 파인튜닝에서 활성화 확률 ρₚₜ, ρ_shared𝒻ₜ, ρ_new𝒻ₜ 로 정의된 스파이크‑앤‑슬래브 분포를 따른다.
**4. 일반화 오차의 이론적 특성화**
Replica 방법을 이용해 고차원 한계(D→∞)에서 파인튜닝 최적화 문제를
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기