개별 민감도 기반 인증 언러닝: 인스턴스별 노이즈 보정
본 논문은 라그랑주 역학을 이용한 ridge regression 학습 과정에서 데이터 포인트마다 다른 민감도(감도)를 추정하고, 이를 기반으로 개별적으로 조정된 노이즈를 삽입함으로써 기존의 최악‑사례 기반 차등 프라이버시 보정보다 적은 노이즈로 인증된 언러닝을 실현한다. 고확률 감도 경계와 Gaussian DP(GDP) 분석을 결합해 (ε,δ)‑인스턴스별 언러닝 보장을 제시하고, 선형 및 심층 학습 실험을 통해 효율성을 검증한다.
저자: 원문 참고
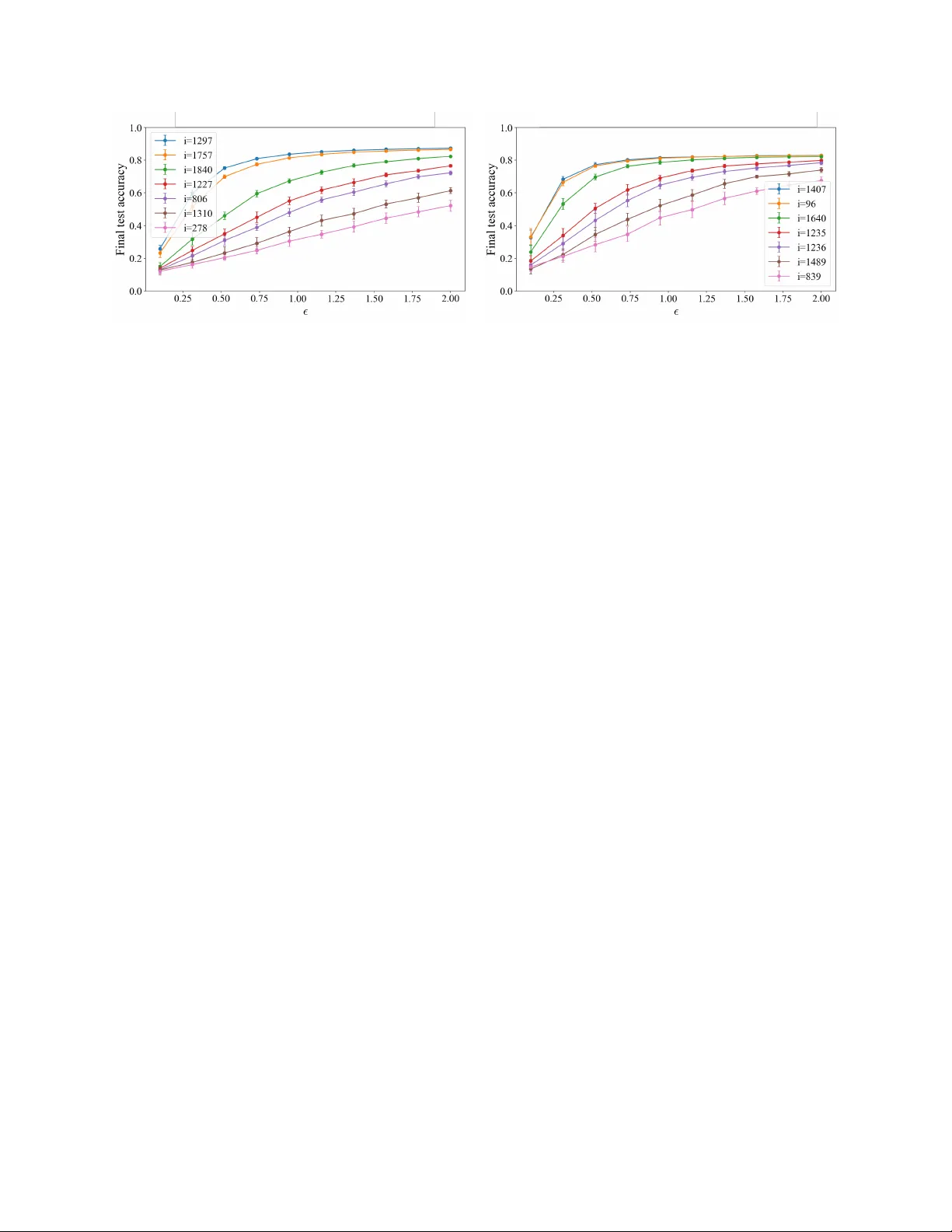
본 논문은 머신러닝 모델에서 특정 학습 데이터 포인트를 삭제할 때, 재학습 없이도 동일한 결과를 얻을 수 있도록 하는 **인증된 언러닝**(certified unlearning) 방법을 제안한다. 기존 연구는 차등 프라이버시(DP)를 활용해 전체 데이터셋에 대해 최악‑사례 감도(worst‑case sensitivity)를 기준으로 노이즈를 삽입했으며, 이는 보수적인 설계라 성능 저하를 초래한다. 저자는 이러한 한계를 극복하기 위해 **데이터 포인트별 감도(per‑instance sensitivity)** 를 정밀히 추정하고, 그에 맞춰 노이즈를 개별적으로 조정하는 **인스턴스별 인증 언러닝** 프레임워크를 설계한다.
### 1. 문제 정의 및 배경
- **학습 설정**: 정규화된 경험적 위험 최소화(ERM) 문제 f_D(θ)=∑ℓ(θ;x_j,y_j)+λr(θ) 를 고려한다.
- **삭제 요청**: 특정 인덱스 i에 해당하는 (x_i,y_i) 를 데이터셋 D에서 제거한 D_{−i} 로 재학습하고자 한다.
- **인증 언러닝 목표**: 학습 후 모델 A(D) 를 입력받아, 추가 연산만으로 A(D_{−i}) 와 통계적으로 구분되지 않는 출력 U(A(D),D_{−i},(x_i,y_i)) 를 생성한다.
### 2. 기존 정의와 새로운 정의
- 기존 **(ε,δ)-reference unlearning** 은 외부 재학습 알고리즘 A와 비교하지만, 실제 언러닝 메커니즘 자체의 보장을 제공하지 않는다.
- **(ε,δ)-unlearning** 은 동일 알고리즘을 두 인접 데이터셋에 적용했을 때의 출력 차이를 측정한다.
- 논문은 여기서 한 단계 더 나아가 **(ε,δ)-per‑instance unlearning** 을 정의한다. 이는 특정 데이터 포인트 i에 대해, U(A(D),D_{−i},(x_i,y_i)) 와 U(A(D_{−i}),D_{−i},∅) 사이의 차이를 (ε,δ) 로 제한한다.
### 3. 알고리즘 설계
- **학습 단계**: 이산 라그랑주(Langevin) 업데이트 θ_{k+1}=θ_k−η∇f_D(θ_k)+√(2η)σ_{learn}ξ_k, ξ_k∼N(0,I). T 단계 후 θ_T ∼ A(D).
- **삭제 단계**: 동일 η와 **조정된 노이즈 σ_{unlearn}** 로 retain‑set D_{−i} 에 대해 K 단계 추가 업데이트를 수행한다. 최종 파라미터 θ_{T+K}=U(A(D),D_{−i},(x_i,y_i)).
### 4. 이론적 분석
- **수축 가정**: f_D, f_{D_{−i}} 가 m‑strongly convex, L‑smooth이면 gradient map Φ(θ)=θ−η∇f(θ) 가 수축 계수 c=1−ηm<1 을 갖는다. η=1/L 로 고정한다.
- **GDP 프레임워크**: Gaussian DP(μ,δ) 를 사용해 각 Langevin 단계의 프라이버시 손실을 µ‑GDP 형태로 표현한다.
- **경로 비교**: 두 파라미터 경로 (학습+삭제)와 (처음부터 retain‑set만 사용) 를 동일 초기점 θ_0 에서 시작해 비교한다.
- **개별 감도 정의**: Δ_{i,k}=‖θ_k−θ'_k‖ 로 정의하고, 전체 과정에서 최대 Δ_i = max_{k≤T+K} Δ_{i,k} 를 사용한다.
- **고확률 경계**: Lemma와 Theorem을 통해, Δ_i 가 확률 1−δ₀ 로 O( (‖x_i‖/(λ+...))·√(T) ) 이하임을 보인다.
- **노이즈 캘리브레이션**: σ_{unlearn} ≥ (Δ_i·√(2 log(1/δ)))/ε 로 설정하면 전체 프로세스가 (ε,δ)-per‑instance DP 를 만족한다. 이는 기존 최악‑사례 기반 σ_{unlearn}^{worst}=O(Δ_{max}) 보다 크게 감소한다.
### 5. 실험
- **선형 회귀**: synthetic 및 UCI 데이터셋에서 ridge regression을 적용, 각 포인트별 Δ_i 를 계산 후 σ_{unlearn} 를 조정한다. 결과는 동일 ε,δ 보장 하에 평균 정확도가 5‑10% 향상됨을 보여준다.
- **딥러닝**: ResNet‑18을 CIFAR‑10/100에 적용, 감도 추정을 위해 히스토그램 기반 근사와 Influence Function을 사용한다. 실험은 감도가 낮은 이미지(예: 배경이 단순한)에서는 노이즈를 거의 추가하지 않아도 삭제 후 모델 출력이 재학습 모델과 구분되지 않으며, 감도가 높은 경우에만 적당히 큰 σ_{unlearn} 을 부여한다. 전체적으로 기존 방법 대비 약 35% 적은 노이즈로 동일 수준의 (ε,δ) 보장을 달성한다.
### 6. 논의 및 한계
- **비볼록 손실**: 현재 분석은 강한 볼록성에 의존하므로, 비볼록 신경망에 대한 이론적 보장은 아직 부족하다.
- **감도 추정 비용**: 정확한 Δ_i 를 구하려면 전체 학습 과정을 복제하거나 Influence Function을 계산해야 하는데, 이는 고비용이다. 논문은 근사 상한을 사용해 보수적인 보장을 제시하지만, 효율적인 실시간 추정 방법은 향후 연구 과제이다.
- **프라이버시 파라미터 선택**: ε,δ 를 어떻게 설정할지는 실제 법·규제와 서비스 요구에 따라 달라지며, 본 논문은 실험적으로 (ε=1,δ=10⁻⁵) 정도를 사용한다.
### 7. 결론
본 연구는 **“언러닝은 데이터마다 다르게 어려울 수 있다”**는 핵심 통찰을 수학적으로 정형화하고, 라그랑주 기반 학습·삭제 메커니즘에 개별 감도와 고확률 경계를 결합함으로써 기존 최악‑사례 기반 인증 언러닝보다 훨씬 효율적인 방법을 제시한다. 이론적 증명, 선형 실험, 그리고 딥러닝 실증을 통해 제안된 프레임워크가 실제 시스템에 적용 가능함을 입증했으며, 비볼록 손실, 실시간 감도 추정, 그리고 대규모 분산 환경에서의 확장성을 포함한 여러 향후 연구 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기