꼬리 제어 동적 어휘 가지치기로 안정적인 LLM 강화학습
LLM 강화학습에서 고속 추론 엔진과 고정밀 학습 엔진이 같은 파라미터를 사용해도 확률 분포가 달라지는 ‘학습‑추론 불일치’가 발생한다. 이 불일치는 토큰 확률 p에 따라 비대칭적으로 영향을 미치며, 낮은 확률(꼬리) 토큰에서 큰 로그확률 차이를 만든다. 저자는 이러한 꼬리 토큰을 동적으로 제외하는 ‘안전 어휘 집합’으로 목표를 재설계함으로써 불안정성을 제거하고, 최적화 편향을 이론적으로 제한한다. 실험 결과, 제안 방법은 훈련 중 퍼플렉시티 …
저자: ** Yingru Li, Jiawei Xu, Jiacai Liu
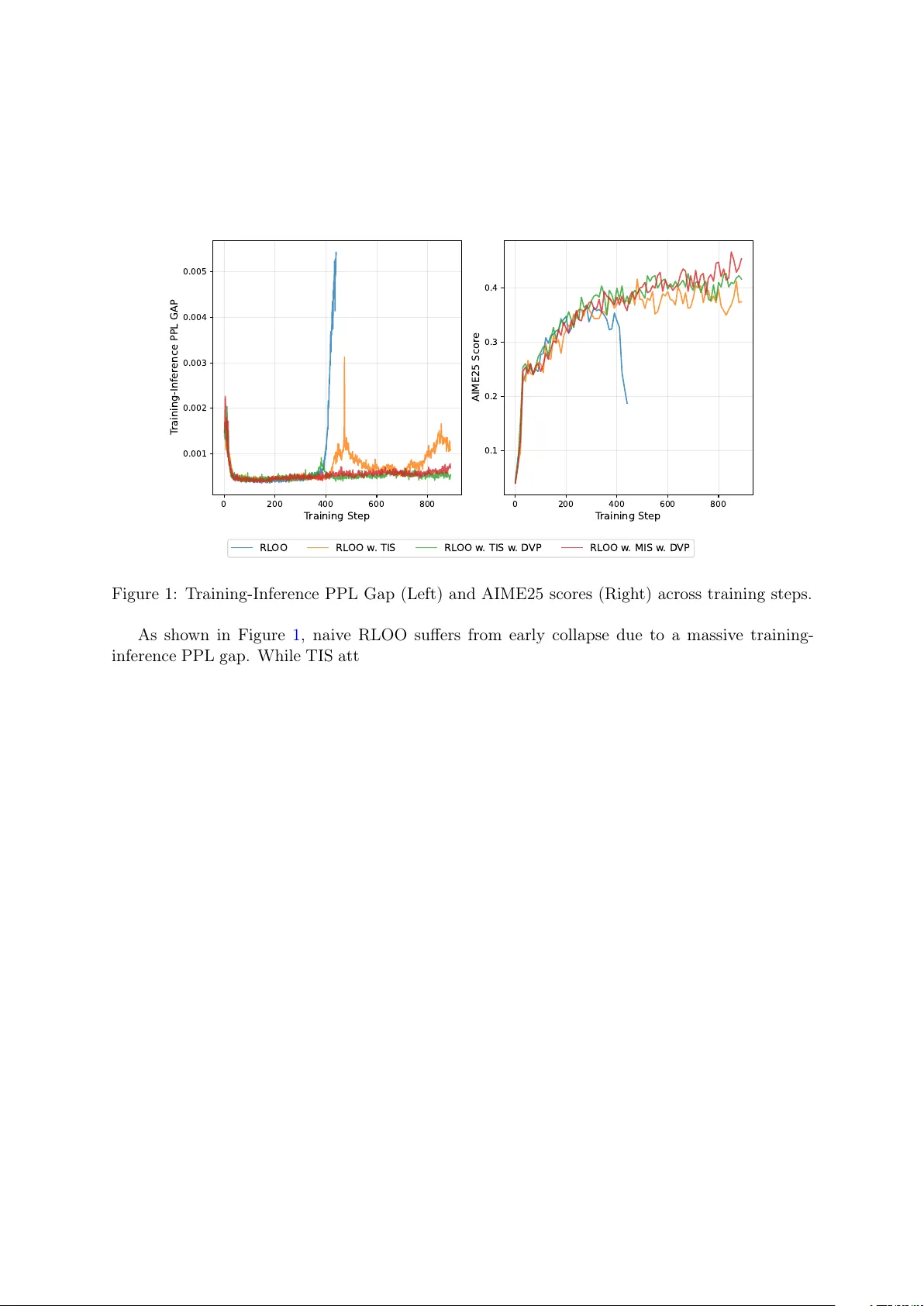
본 논문은 대규모 언어 모델(LLM)의 강화학습(RL) 과정에서 고속 추론 엔진과 고정밀 학습 시스템 간에 발생하는 ‘학습‑추론 불일치’를 심도 있게 분석하고, 이를 해결하기 위한 새로운 목표 설계 방안을 제시한다.
1. **문제 정의와 배경**
- 최신 LLM은 복잡한 추론·다중턴 대화와 같은 고난이도 태스크에 RL을 적용해 보상 기반 학습을 수행한다. 하지만 샘플링을 담당하는 고속 추론 엔진(vLLM, SGLang 등)은 페이지드 어텐션, INT8/FP8 KV‑캐시, 커널 퓨전 등으로 토큰당 처리량을 극대화한다. 반면 학습 시스템(FSDP, Megatron‑LM)은 수치 안정성을 위해 FP32·BF16 등 높은 정밀도를 유지한다.
- 동일 파라미터 θ를 사용하더라도 부동소수점 연산의 비결합성(associativity) 차이와 정밀도 차이로 인해 두 시스템이 출력하는 로그잇(logits) z_train와 z_infer에 미세한 오차 ε가 존재한다.
2. **수학적 진단**
- 로그잇 차이를 z_infer = z_train + ε 로 모델링하고, |ε_k| ≤ ε_max 로 가정한다.
- 토큰 a에 대한 로그확률 차이 Δ_a = log π_train(a|s) − log π_infer(a|s)는 |Δ_a| ≤ 2 ε_max (1−p_a) 로 상한된다(정리 3.2). 여기서 p_a = π_train(a|s)이다. 즉, 고확률 토큰(p_a≈1)에서는 차이가 사라지고, 저확률 꼬리 토큰(p_a→0)에서는 차이가 최대값에 가깝다.
- 샘플링된 저확률 토큰은 Δ_a가 체계적으로 음수(π_infer≫π_train)인 경향을 보이며, 이는 로그확률 차이의 평균이 양수인 형태(정리 3.3)로 수식화된다. 이러한 편향은 시퀀스 수준에서 누적되어 Δ_y = Σ_t Δ_{y_t}가 크게 음수가 되고, exp(−Δ_y)≫1인 비율을 만든다.
- 그라디언트 편향은 g′−g = E_{y∼π_train}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기