FEM‑Bench: 과학 코드 생성 LLM 평가를 위한 유한요소 기반 벤치마크
본 논문은 물리·수치 모델링 능력을 검증하기 위해, 대학원 수준의 유한요소(FEM) 과제를 33개로 구성한 FEM‑Bench 2025를 제시한다. LLM이 함수 구현과 pytest 기반 단위 테스트를 동시에 생성하도록 요구하며, Gemini 3 Pro와 GPT‑5 등 최신 모델을 5회 시도해 성능을 측정한다. 결과는 현재 모델이 물리·수치 일관성을 완전히 보장하지 못함을 보여주며, 향후 더 복잡한 과제로 benchmark를 확장할 계획을 제시한…
저자: ** - Saeed Mohammadzadeh* (Department of Mechanical Engineering, Boston University) - Erfan Hamdi* (Department of Mechanical Engineering, Boston University) - Joel Shor (Move37 Labs; Department of Mechanical Engineering
본 논문은 인공지능 언어 모델(LLM)이 물리·수치 기반 과학 코드를 자동 생성할 수 있는지를 평가하기 위한 새로운 벤치마크, FEM‑Bench 2025를 제안한다. 기존 코드‑생성 평가가 일반적인 프로그래밍 논리나 API 사용 능력에 초점을 맞추는 반면, FEM‑Bench는 유한요소법(FEM)과 매트릭스 구조해석(MSA)이라는 전통적인 공학 시뮬레이션 분야를 기반으로, 물리 법칙, 수치 해석, 기하학적 변환 등 다중 단계의 구조화된 추론을 요구한다.
벤치마크 설계는 크게 두 축으로 구성된다. 첫 번째는 “코드 생성” 과제로, 각 과제는 물리적 시스템(예: 2D 평판 구조물, 1D 트러스, 비선형 탄성체)의 지배 방정식, 약형식 변환, 요소별 형상함수 정의, 수치 적분, 전역 행렬 조립, 경계조건 적용까지의 전체 파이프라인을 명시한다. LLM은 지정된 파이썬 함수 시그니처에 맞춰 구현을 제공해야 하며, 실행 시 레퍼런스 해와 비교해 수치 오차, 대칭성, 에너지 보존 등 물리·수치 일관성을 만족해야 한다. 두 번째는 “테스트 생성” 과제로, 모델은 pytest 기반 단위 테스트를 자동 생성한다. 이 테스트는 (a) 레퍼런스 구현에 대해 모두 통과하고, (b) 사전에 정의된 오류 구현(예: 행렬 비대칭, 경계조건 누락)에 대해서는 실패하도록 설계돼, 모델이 검증 로직을 이해했는지를 판단한다.
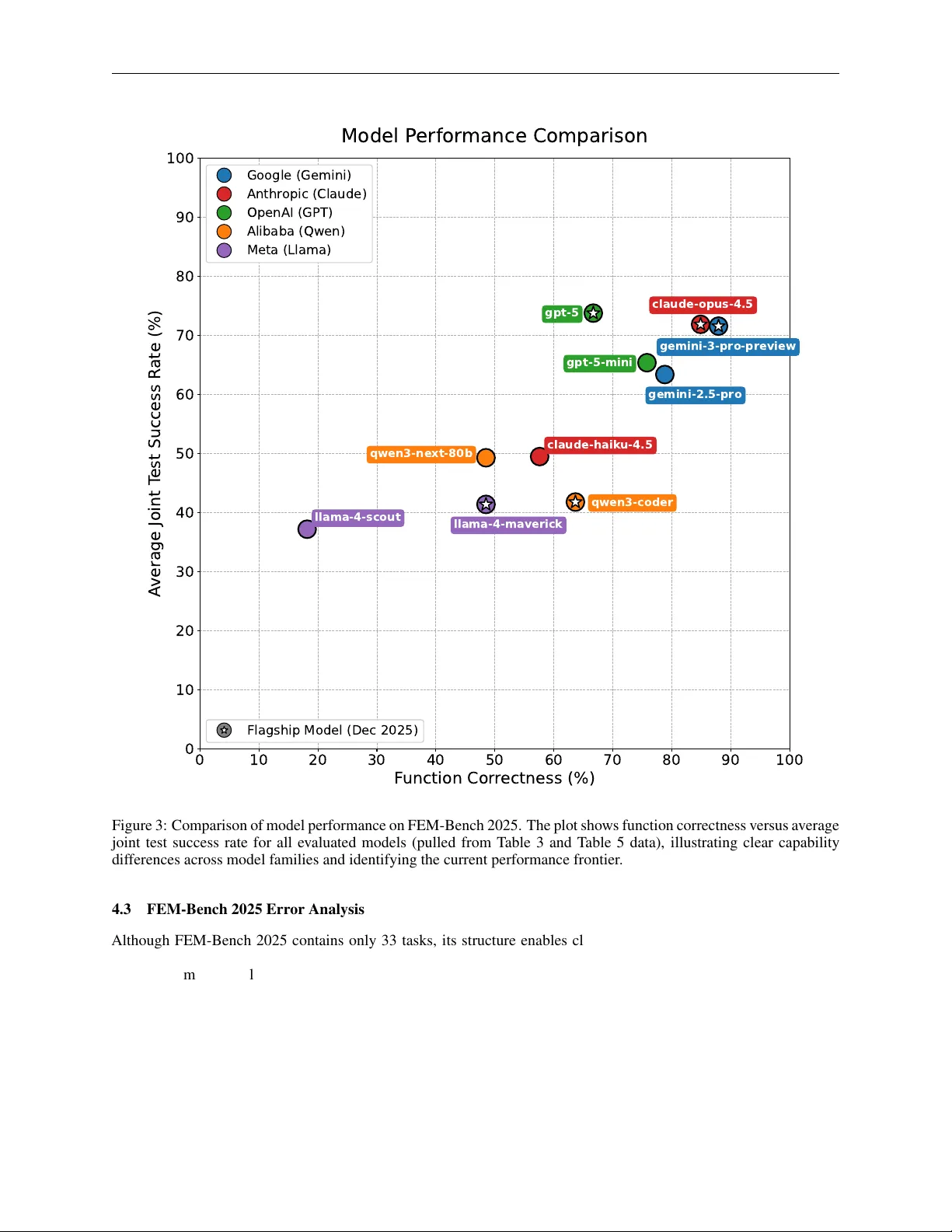
FEM‑Bench 2025는 총 33개의 과제로 구성되며, 각 과제는 독립적인 파이썬 모듈 형태로 제공된다. 모듈에는 (1) 상세 docstring이 포함된 레퍼런스 구현, (2) pytest 스타일 테스트, (3) 의도된 오류 구현, (4) 의존성 함수, (5) task_info() 메타데이터 함수가 포함된다. 이러한 구조는 자동 프롬프트 생성, 모델 호출, 출력 파싱, 정량적·정성적 평가를 가능하게 하며, 재현성과 확장성을 보장한다.
실험에서는 최신 상용·오픈소스 LLM 7종(Gemini 3 Pro, GPT‑5, Claude 3, Llama 2‑70B 등)을 선정해, 각 모델을 5회 독립 실행한다. 평가 지표는 (i) 코드 성공률(문법 오류 없이 실행, 물리·수치 기준 충족), (ii) 테스트 성공률(모든 테스트 통과 및 기대 실패 검증), (iii) Joint Success Rate(코드와 테스트 모두 성공)이다. 결과는 Gemini 3 Pro가 코드 측면에서 30/33 과제를 최소 한 번 이상 성공했으며, 26/33 과제를 5회 모두 성공했다는 점에서 가장 높은 일관성을 보였다. GPT‑5는 테스트 생성에서 평균 Joint Success Rate 73.8%를 기록했지만, 여전히 9개 과제에서 테스트가 부정확하거나 누락되었다. 다른 모델들은 과제 난이도에 따라 성공률이 크게 변동했으며, 특히 비선형 재료 모델링, 좌표 변환, 고차원 수치 적분 단계에서 오류가 집중되었다.
논문은 이러한 결과를 바탕으로 현재 LLM이 “패턴 기반 코드 복제”에는 강점을 보이지만, “물리·수치 의미 해석”과 “다단계 검증 루프”에서는 한계가 있음을 지적한다. 부동소수점 연산 민감도, 행렬 대칭성 유지, 에너지 일관성 등 작은 실수도 물리적으로 비합리적인 결과를 초래하기 때문에, 모델이 이러한 세부 사항을 학습하고 자동 검증 피드백을 통합하는 것이 필요하다.
벤치마크 자체의 제한점도 논의된다. 현재 과제는 대학원 초급 수준에 머물러 있어, 실제 산업·연구에서 요구되는 복합 비선형, 동적, 다물리 커플링 문제를 충분히 반영하지 못한다. 또한 평가가 수치 오차와 테스트 통과 여부에 국한돼, 결과 해석(예: 응력 집중 위치, 모드 형태)까지는 검증하지 않는다. 향후 버전에서는 (1) 고차원 비선형 재료와 대변형 문제, (2) 시간 적분 기반 동적 해석, (3) 열‑구조, 유체‑구조 등 멀티피직스 연계 과제, (4) 시각화·후처리 결과 자동 검증 등을 추가해 벤치마크의 난이도와 적용 범위를 확대할 계획이다.
결론적으로, FEM‑Bench는 LLM이 과학·공학 코드 생성에서 물리·수치 타당성을 보장할 수 있는지를 체계적으로 측정할 수 있는 최초의 정형화된 벤치마크이며, 현재 모델들의 성능 격차를 통해 향후 연구 및 모델 개발 방향을 명확히 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기