의료 영상 의미 분할을 위한 작업 분해와 동기화 전략
본 논문은 의료 영상 의미 분할을 하나의 작업이 아닌 픽셀‑단위 분할, 객체 클래스 예측, 이미지 씬 분류라는 세 개의 연속적인 서브 작업으로 분해한다. 각 서브 작업은 개별 손실을 최적화하면서, 작업‑간 컨텍스트 앙상블과 새롭게 제안한 sync‑regularization을 통해 상호 보완적인 정보를 교환한다. 이를 2D·3D 의료 데이터셋(ROBOT18, BRATS18, REFUGE18)에 적용해 기존 최첨단 방법들을 능가하는 성능을 달성하였…
저자: Xuhua Ren, Lichi Zhang, Sahar Ahmad
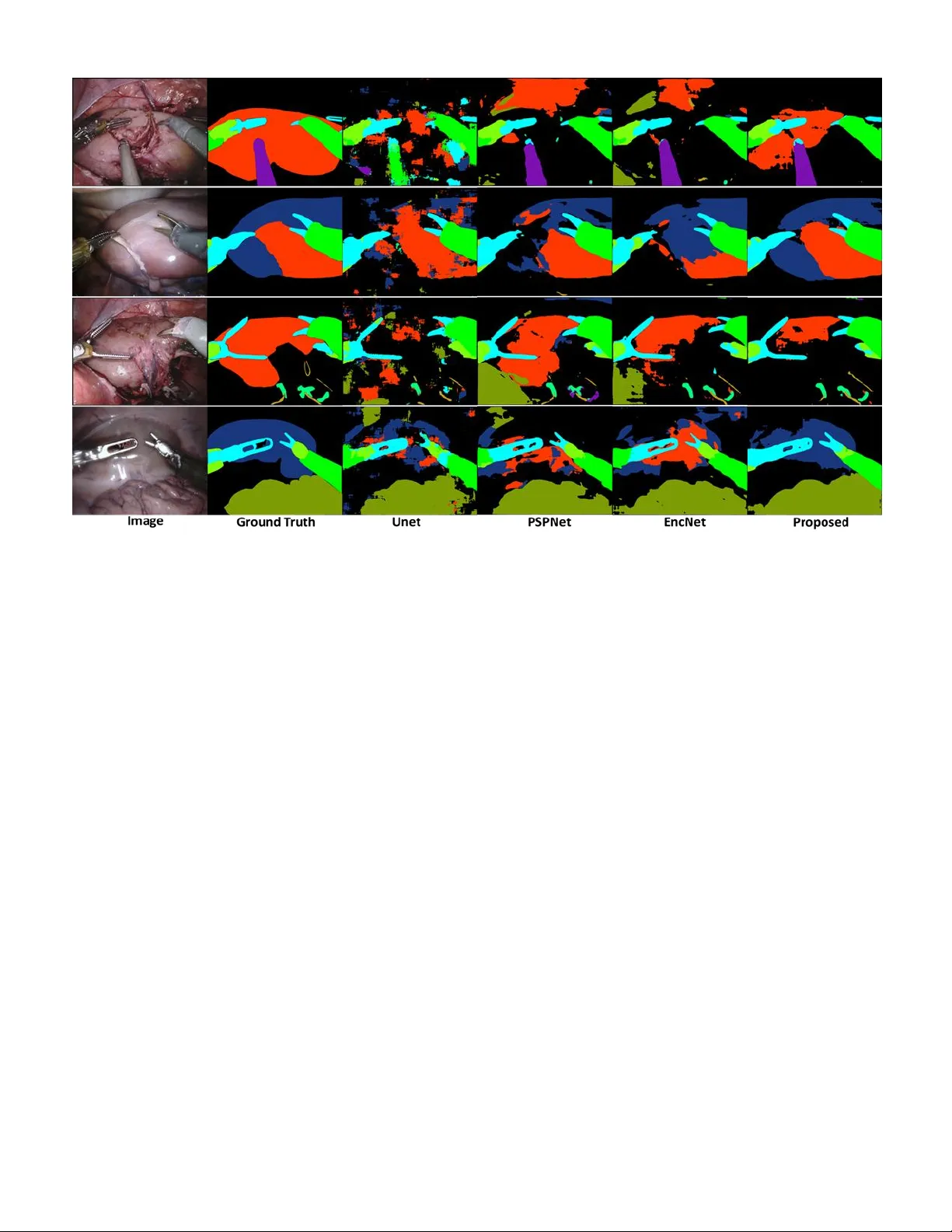
본 논문은 의료 영상 의미 분할을 보다 효율적으로 수행하기 위해, 기존의 단일 FCN 기반 접근법을 재구성한다. 먼저, 의미 분할 작업을 세 개의 연속적인 서브 작업으로 분해한다. 첫 번째 서브 작업은 전통적인 픽셀‑단위 마스크를 생성하는 것이며, 두 번째는 이미지 내에 존재하는 객체 클래스(예: 신장, 종양 등)의 존재 여부를 이진 형태로 예측한다. 세 번째는 전체 이미지가 속하는 씬(예: 수술 단계, 종양 등급)을 분류한다. 이러한 분해는 인간 전문가가 실제 진단 과정에서 먼저 큰 틀을 파악하고, 그 다음 세부 영역을 정밀하게 구분하는 과정과 유사하다.
각 서브 작업은 독립적인 손실 함수를 갖는다. 픽셀‑단위 분할에서는 교차 엔트로피와 Dice 손실을 가중합한 하이브리드 손실을 사용해 경계 정확성을 높이고, 클래스·씬 작업에서는 이진 교차 엔트로피를 적용해 존재 여부를 학습한다. 손실 함수는 각각의 작업이 최적화되도록 설계되었으며, 전체 네트워크는 다중 작업 학습(multitask learning) 프레임워크 하에 동시에 학습된다.
핵심적인 설계 요소는 작업‑간 컨텍스트 앙상블(task‑task context ensemble)이다. 인코더에서 추출된 피처 맵은 다중 스케일 팽창 합성곱 블록을 통과하면서 다양한 수용 영역을 확보한다. 구체적으로, 63, 31, 15, 3, 1의 팽창률을 갖는 5단계 합성곱을 순차적으로 적용해 저수준 세부 정보와 고수준 전역 정보를 동시에 포착한다. 이후 세 서브 작업은 동일한 잠재 공간(latent space)으로 집합되며, 이 공간을 기반으로 각각의 디코더가 독립적으로 출력값을 생성한다. 이렇게 함으로써 각 작업은 서로의 정보를 보완하면서도 독립적인 표현을 학습한다.
또 다른 혁신은 sync‑regularization이다. 클래스 예측은 본질적으로 분할 결과의 존재 여부를 요약한 것이므로, 분할 맵에서 각 클래스에 해당하는 픽셀 수가 0보다 큰지를 Boolean 값으로 변환한다. 이 Boolean 벡터와 클래스 예측 벡터 사이에 이진 교차 엔트로피 손실을 부과함으로써, 두 작업 간의 일관성을 강제한다. 이 과정은 클래스 브랜치에 역전파되어, 클래스 예측이 잘못될 경우 분할 브랜치에도 페널티가 전달되고, 반대로 분할 결과가 클래스 예측과 모순될 경우에도 조정이 이루어진다. 씬 작업은 클래스와의 연관성이 약해 sync‑regularization에서 제외하였다.
아키텍처는 얕은 CNN 인코더와 PSPNet 기반 디코더를 결합하였다. 2D 데이터(ROBOT18, REFUGE18)와 3D 데이터(BRATS18)에 각각 맞춤형 인코더를 설계했으며, 모든 데이터에 대해 동일한 컨텍스트 앙상블 모듈을 적용하였다. 실험에서는 세 데이터셋 모두에서 기존 최첨단 모델(U‑Net, EncNet, PSPNet 등)을 능가하는 성능을 기록하였다. 특히, 제한된 학습 샘플 수에도 불구하고 높은 Dice와 IoU 점수를 달성했으며, 클래스·씬 정보를 활용함으로써 작은 객체와 복잡한 경계가 있는 영역에서 현저한 개선이 관찰되었다.
논문의 주요 기여는 다음과 같다. (1) 의미 분할 작업을 다중 인지 수준으로 분해함으로써 학습 효율성을 높였다. (2) 작업‑간 컨텍스트 앙상블과 sync‑regularization을 도입해 서브 작업 간의 상호 보완성을 강화하였다. (3) 2D·3D 다양한 의료 영상 시나리오에 적용 가능한 실용적인 프레임워크를 구축하고, 세 개의 공통 벤치마크에서 최고 수준의 성능을 입증하였다.
한편, 추가 디코더와 다중 스케일 팽창 합성곱으로 인한 파라미터 증가와 연산 비용이 증가한다는 점이 단점으로 지적된다. 또한 sync‑regularization은 클래스와 분할 사이의 단순 존재‑존재 관계만을 이용하므로, 클래스 내 세부 형태 차이를 반영하기엔 한계가 있다. 향후 연구에서는 보다 정교한 클래스‑분할 매핑(예: 클래스별 형태 템플릿)과 경량화된 컨텍스트 모듈을 탐색함으로써 효율성을 개선하고, 더 복잡한 멀티‑모달 의료 데이터에 대한 확장성을 검증할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기