고차원 CNN을 위한 텐서 분해와 시공간 감정 추정
본 논문은 텐서 분해 기반의 고차원 컨볼루션 블록을 제안하고, 이를 정적 이미지에 사전 학습한 뒤 전이(transduction) 기법으로 영상 데이터에 확장함으로써, 파라미터 수와 연산량을 크게 줄이면서도 얼굴 감정의 연속적 Valence‑Arousal 추정에서 기존 3D CNN을 능가하는 성능을 달성한다.
저자: Jean Kossaifi, Antoine Toisoul, Adrian Bulat
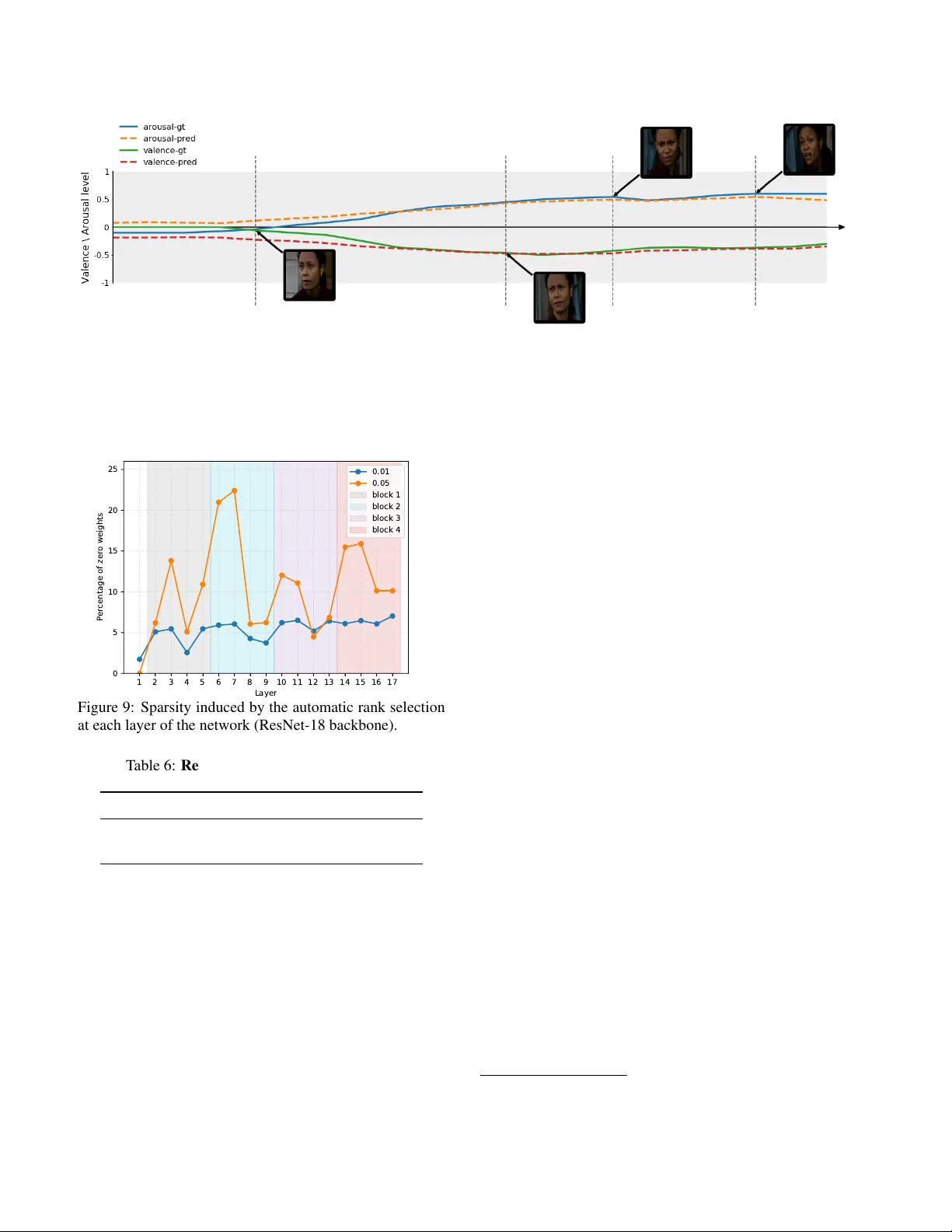
본 논문은 고차원(다차원) 컨볼루션 신경망이 갖는 파라미터 폭증과 연산 비용 문제를 해결하기 위해, 텐서 분해 기법을 활용한 새로운 컨볼루션 블록인 CP‑Higher‑Order Convolution (HO‑CPConv)을 제안한다. 기존 연구에서는 저‑랭크 텐서 분해(CP, Tucker)를 이용해 2D 컨볼루션을 효율화하거나, MobileNet과 같은 depth‑wise separable 구조를 설계했지만, 이들을 고차원(예: 3D) 영상 처리에 일관되게 적용하기는 어려웠다. 저자는 이러한 두 흐름을 하나의 통합 프레임워크로 묶어, 고차원 커널을 저‑랭크 텐서 형태로 재구성하고, 이를 일련의 1×1, depth‑wise, 그리고 작은 공간 커널로 분해함으로써 파라미터와 FLOPs를 크게 감소시킨다.
수학적으로는 1×1 컨볼루션을 n‑mode product와 동일시하고, CP 분해를 적용하면 원래 4차원 커널 W∈ℝ^{T×C×K_H×K_W}를 R개의 rank‑1 텐서들의 합으로 표현한다. 이를 전개하면 depth‑wise conv → 1×1 conv → 1×1 conv 순서의 연산 흐름이 도출되며, 이는 MobileNet의 구조와 일치한다. Tucker 분해를 적용하면 먼저 채널 차원을 압축하고, 작은 3×3 conv를 수행한 뒤 다시 채널을 복원하는 ResNet‑Bottleneck과 동일한 형태가 된다. 따라서 기존 효율적 아키텍처들은 모두 특정 텐서 분해의 특수 케이스로 해석될 수 있음을 보여준다.
핵심 기여는 “higher‑order transduction”이다. 저자는 먼저 정적 이미지(2D) 데이터에 HO‑CPConv 블록을 포함한 네트워크를 학습한다. 이후 시간 차원을 위한 새로운 텐서 팩터(시간 팩터)를 추가하고, 기존 공간 팩터는 고정하거나 미세조정한다. 이렇게 하면 N‑차원 모델을 (N+K)‑차원 모델로 확장할 수 있으며, 공간 정보는 그대로 유지하면서 시간적 동역학을 학습한다. 전이 과정은 텐서 차원에서의 팩터 추가와 동일하므로, 파라미터 재사용률이 높아 데이터가 부족한 상황에서도 안정적인 학습이 가능하다.
실험에서는 대규모 정적 이미지 감정 데이터셋 AffectNet(≈450k 이미지)과 두 개의 동영상 기반 연속 감정 데이터셋 SEWA, AFEW‑VA를 사용했다. 정적 이미지에 대해 사전 학습한 뒤 전이된 모델은 SEWA와 AFEW‑VA에서 기존 3D CNN, I3D, ResNet3D 등과 비교해 Concordance Correlation Coefficient (CCC)와 Mean Absolute Error (MAE) 모두에서 유의미하게 높은 성능을 기록했다. 파라미터 수는 기존 3D 모델 대비 4~6배 감소했으며, 연산량도 5~7배 줄었다. 또한, 동일 파라미터 예산 하에서 MobileNet‑V2 기반 2D 모델보다도 우수한 결과를 보였다.
논문의 마지막 부분에서는 제안 방법이 얼굴 감정 외에도 행동 인식, 의료 영상 시계열 분석 등 다양한 시공간 데이터에 적용 가능함을 논의한다. 텐서 분해와 효율적 아키텍처 설계가 동일한 수학적 원리에서 출발한다는 점을 강조하며, 향후 더 높은 차원의 데이터(예: 4D 의료 영상, 멀티모달 센서 데이터)에도 동일한 전이 메커니즘을 적용해 파라미터 효율성을 극대화할 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기