음악의 장기 구조 학습을 위한 계층적 잠재 벡터 모델
본 논문은 기존 순환 VAE가 긴 시퀀스의 장기 구조를 포착하지 못하는 문제를 해결하기 위해, 서브시퀀스별 임베딩을 먼저 생성하고 이를 이용해 각 서브시퀀스를 독립적으로 복원하는 계층적 디코더 구조를 제안한다. 음악 데이터에 적용한 MusicVAE는 평면 디코더 대비 샘플링, 보간, 재구성에서 현저히 우수한 성능을 보이며, 잠재 공간을 활용한 속성 조작과 평균화 실험에서도 의미 있는 결과를 얻는다.
저자: Adam Roberts, Jesse Engel, Colin Raffel
본 논문은 변분 오토인코더(VAE)를 순차 데이터, 특히 음악과 같이 긴 시퀀스의 장기 구조를 가진 데이터에 적용하면서 발생하는 두 가지 주요 문제—‘posterior collapse’와 ‘latent bottleneck’를 해결하기 위해 새로운 모델 구조를 제안한다. 기존의 순환 VAE는 디코더 RNN이 자체적으로 강력한 자동회귀 모델 역할을 수행하기 때문에, 학습 과정에서 잠재 변수 z가 무시되는 현상이 빈번히 일어나며, 이는 KL 발산 항이 거의 0에 수렴해 잠재 공간이 사전 분포와 동일해지는 ‘posterior collapse’를 초래한다. 또한, 전체 시퀀스를 하나의 고정 차원 잠재 벡터에 압축하려는 시도는 시퀀스가 길어질수록 정보 손실이 급격히 증가해 재구성 품질이 저하되는 ‘latent bottleneck’ 문제를 야기한다.
이를 극복하기 위해 저자들은 **계층적 디코더**를 도입한다. 입력 시퀀스를 일정 길이의 서브시퀀스로 나누고, 잠재 벡터 z를 먼저 ‘컨덕터(conductor)’ RNN에 전달한다. 컨덕터는 각 서브시퀀스에 대응하는 임베딩 c₁…c_U를 생성하고, 각 임베딩은 공유된 하위 디코더 RNN의 초기 상태로 사용된다. 하위 디코더는 해당 서브시퀀스 내부에서 전통적인 자동회귀 방식으로 토큰을 예측한다. 이 구조는 (1) 잠재 벡터가 디코딩 전 과정에 지속적으로 영향을 미쳐 ‘posterior collapse’를 방지하고, (2) 서브시퀀스 간 장기 의존성을 컨덕터가 담당함으로써 긴 시퀀스에서도 효율적인 정보 전달이 가능하도록 만든다. 음악처럼 구절·마디·박자 등 계층적 구조가 뚜렷한 도메인에 특히 적합하다.
구체적인 모델 구성은 다음과 같다. 인코더는 2‑layer bidirectional LSTM(숨김 크기 2048)으로, 입력 시퀀스 전체에 대한 전·후방 정보를 모두 포착한다. 최종 은닉 상태를 통해 평균 μ와 표준편차 σ를 추정하고, 재파라미터화 기법을 이용해 잠재 벡터 z를 샘플링한다. 잠재 차원은 512로 설정하였다. 컨덕터는 2‑layer unidirectional LSTM(숨김 1024, 출력 512)이며, z를 초기 상태로 받아 각 서브시퀀스에 대한 임베딩을 생성한다. 하위 디코더는 2‑layer LSTM(숨김 1024)으로, 각 단계에서 현재 서브시퀀스의 컨덕터 임베딩과 이전 토큰을 결합해 다음 토큰의 확률 분포를 출력한다. 학습 안정성을 위해 β‑VAE와 ‘free bits’ 기법을 적용해 KL 항에 가중치를 부여하고, 필요 시 KL 발산이 일정 임계값 이하일 경우 자유 비트를 제공한다.
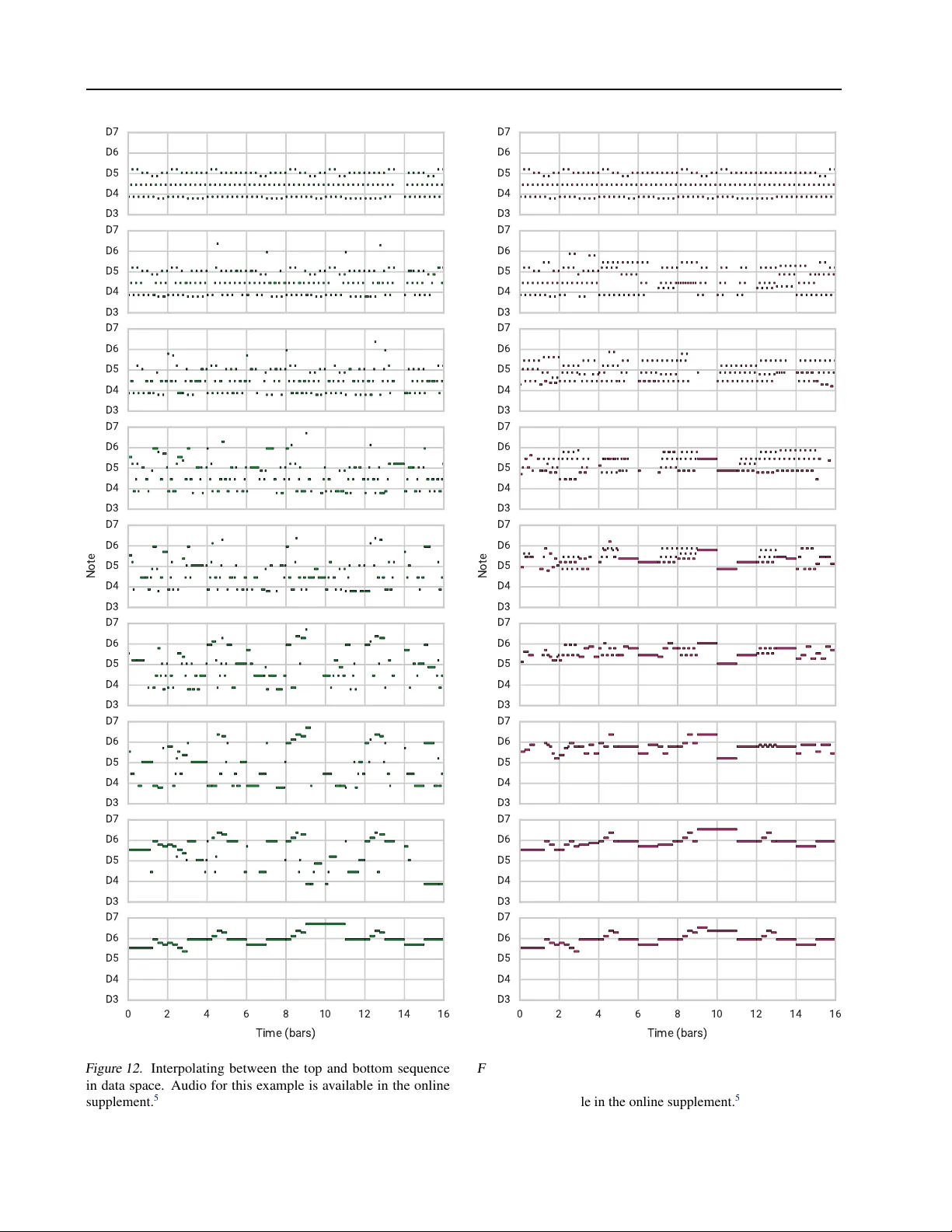
실험은 두 가지 음악 데이터셋, 즉 멜로디(단일 트랙)와 피아노 롤(다중 트랙) 시퀀스에 대해 수행되었다. 평면 디코더(단순 stacked RNN)와 비교했을 때, 제안 모델(MusicVAE)은 다음과 같은 우수한 성능을 보였다. 첫째, **재구성 손실**이 크게 감소했으며, 이는 ELBO의 로그우도 항이 향상된 결과이다. 둘째, **샘플링 품질**이 주관적 청취 평가와 객관적 로그우도 모두에서 평면 디코더보다 월등히 높았다. 셋째, **잠재 공간 보간** 실험에서 두 멜로디 사이를 선형(또는 구면) 보간했을 때, 중간 단계의 출력이 두 멜로디의 음악적 특성을 자연스럽게 혼합한 형태로 나타났다. 넷째, **속성 벡터 연산**(예: 특정 리듬 패턴이나 음높이 변화를 나타내는 평균 벡터)에서도 의미 있는 변형이 가능했으며, 이는 잠재 공간이 해석 가능하고 조작 가능함을 보여준다. 특히, 두 입력 시퀀스의 잠재 코드를 평균화했을 때 생성된 중간 시퀀스는 상위 패턴은 유지하면서도 하위 디테일(예: 옥타브 변동, 휴지기)에서 두 입력의 특성을 적절히 섞어냈다.
논문은 또한 **‘posterior collapse’를 방지하기 위한 실험적 검증**을 제공한다. 동일한 하이퍼파라미터 설정 하에 평면 디코더는 KL 발산이 거의 0에 수렴해 잠재 변수가 무시되는 현상이 관찰되었지만, 계층적 디코더를 사용한 경우 KL 발산이 일정 수준을 유지하면서도 재구성 품질이 크게 향상되었다. 이는 컨덕터와 하위 디코더 사이의 구조적 의존성이 잠재 변수를 효과적으로 활용하도록 만든 결과이다.
마지막으로, 저자들은 제안 모델이 음악 외에도 **텍스트, 동작 시퀀스, 비디오 등 장기 의존성을 갖는 다양한 순차 데이터**에 적용 가능함을 언급한다. 계층적 디코더는 서브시퀀스 단위로 정보를 압축·전달함으로써, 긴 시퀀스에서도 효율적인 학습과 생성이 가능하도록 설계되었기 때문이다. 코드와 사전 학습된 모델은 공개되어 있어, 연구 커뮤니티가 쉽게 재현하고 확장할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기