음성 다이어리제이션을 위한 멀티모달 시퀀스‑투‑시퀀스 모델
본 논문은 단어 텍스트와 MFCC 음향 특징을 동시에 입력으로 받아 화자 변화를 예측하는 시퀀스‑투‑시퀀스(Seq2Seq) 모델을 제안한다. 화자 전환 토큰의 순서를 무시하고 그룹만을 학습하도록 설계한 손실 함수와 32‑단어 윈도우 기반의 중첩 예측 방식을 도입해 정확도를 높였다. Fisher 대화 데이터와 Switchboard ASR 전사에서 실험한 결과, 텍스트와 음향을 모두 활용한 WM 모델이 텍스트 전용 W 모델보다 DER을 4 %p 정…
저자: Tae Jin Park, Panayiotis Georgiou
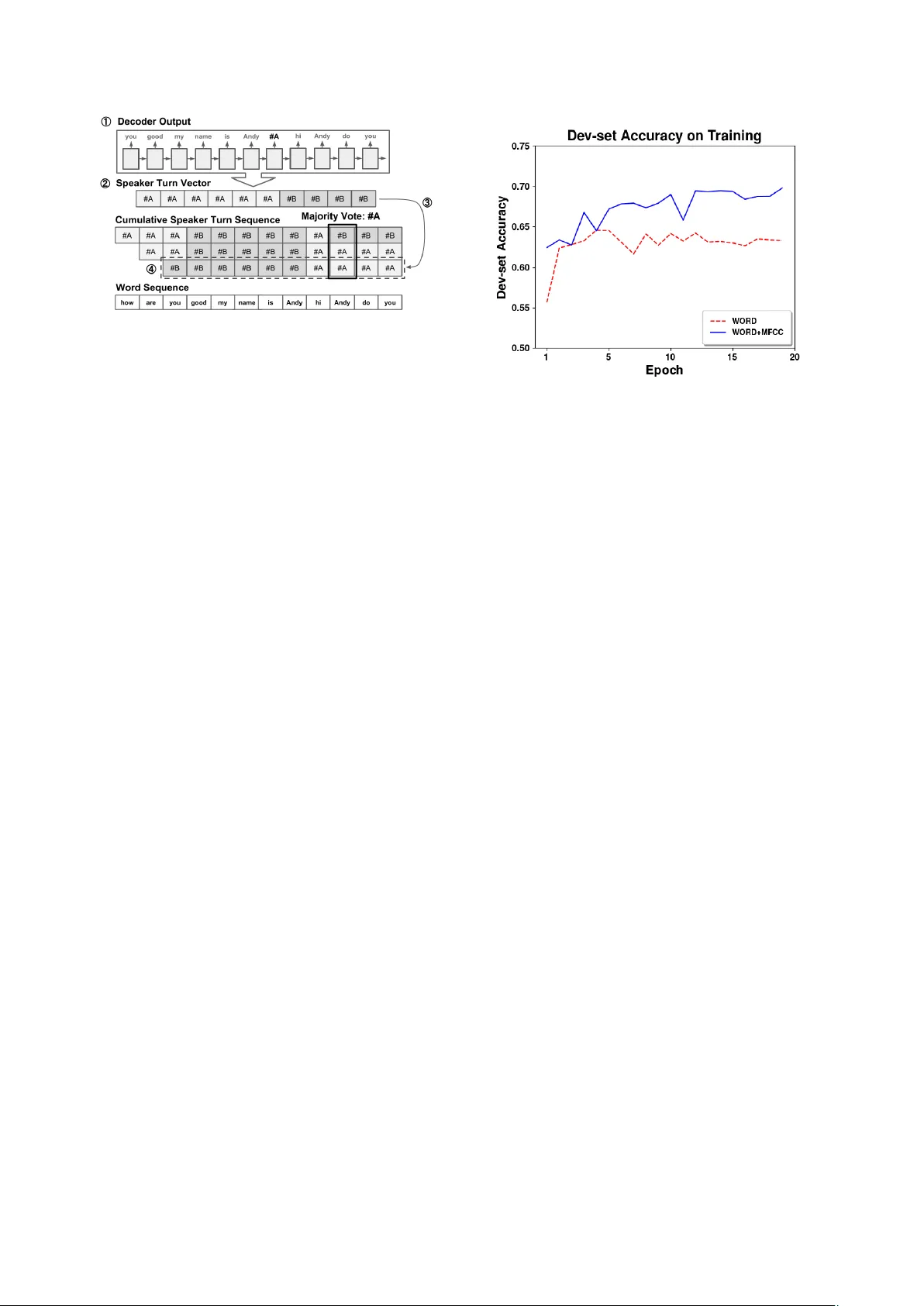
본 논문은 화자 다이어리제이션에서 텍스트와 음향 정보를 동시에 활용하는 멀티모달 접근법을 제안한다. 기존 연구는 주로 음향 기반 BIC, RNN, DNN 등을 이용해 화자 변화를 탐지했으며, 텍스트는 화자 정체성이나 역할 분석에만 제한적으로 사용되었다. 저자들은 인간이 대화를 이해할 때 언어적 단서와 음성적 단서를 모두 활용한다는 점에 착안해, 두 정보를 결합한 시퀀스‑투‑시퀀스(Seq2Seq) 모델을 설계하였다.
**모델 구조**
- **인코더**: 입력은 32개의 연속된 단어와 각 단어에 대응하는 13차원 MFCC 벡터이다. 단어는 원‑핫 인코딩 후 선형 변환을 거쳐 256 차원 임베딩으로 변환되고, MFCC 역시 선형 레이어를 통해 256 차원으로 매핑된다. 두 임베딩을 연결(concatenate)한 뒤 GRU(256 유닛) 인코더에 입력한다.
- **디코더**: 어텐션 메커니즘을 적용한 GRU 디코더가 단어 시퀀스와 동시에 화자 전환 토큰(] A, ] B)을 출력한다. 디코더는 Teacher Forcing 비율 0.5를 사용해 학습한다.
**손실 함수**
화자 전환 토큰은 라벨 순서가 중요하지 않다. 따라서 원본 순서와 뒤집힌 순서(두 화자 라벨을 교환) 두 가지 경우에 대해 교차 엔트로피 손실을 계산하고, 더 작은 값을 최종 손실로 채택한다. 이 방식은 모델이 “화자 A가 먼저 말한다”와 같은 절대 라벨을 학습하지 않게 하여, 라벨 교환이 자유로운 실제 상황에 강인하게 만든다.
**화자 전환 추정 절차**
1. 32단어 윈도우를 전체 대화에 대해 1단어씩 이동하면서 입력한다.
2. 각 윈도우에 대해 디코더가 예측한 전환 토큰 시퀀스를 단어별 라벨로 변환한다.
3. 현재 윈도우의 라벨 벡터와 누적된 라벨 행렬 간 해밍 거리를 계산하고, 필요 시 토큰을 뒤집어(라벨 교환) 거리를 최소화한다.
4. 모든 윈도우를 처리한 뒤, 각 단어에 대해 32번의 예측이 존재하므로 다수결 투표로 최종 화자 라벨을 결정한다.
**클러스터링**
전환 라벨에 따라 MFCC 프레임을 구분하고, 기존 BIC 기반 SCUBA 알고리즘을 사용해 agglomerative clustering을 수행한다. 따라서 제안 시스템은 기존 파이프라인과 호환 가능하며, 비교 실험에서도 동일한 클러스터링 절차를 적용했다.
**실험 설정**
- **데이터**: Fisher English Training Speech Part 1/2 (11 112 대화, 19 M 단어)와 Switchboard‑1 Telephone Speech Corpus.
- **전사**: 두 가지 조건—정확한 레퍼런스 전사와 Kaldi 기반 ASR 전사(평균 WER ≈ 35 %).
- **베이스라인**: LIUM Speaker Diarization Tools (MFCC → SAD → BIC segmentation)와 단어 경계 기반 WS 모델.
**결과**
1. **레퍼런스 전사**:
- 텍스트 전용 W 모델 DER = 28.02 % (Fisher), 27.89 % (Switchboard).
- 텍스트 + MFCC WM 모델 DER = 24.26 % (Fisher), 22.44 % (Switchboard) → 약 4 %p 개선.
- WS 모델 DER ≈ 44–46 %로, 제안 모델이 전반적으로 우수함을 확인.
- Word‑level Diarization Error Rate(WDER)도 동일한 경향을 보이며, WM 모델이 12.32 % (Fisher)·8.56 % (Switchboard)로 가장 낮았다.
2. **ASR 전사**:
- WM 모델 DER = 38.64 % (Switchboard)로, 텍스트 전용 W 모델(50.95 %)보다 오히려 낮아졌지만, 여전히 LIUM(66.57 %)보다 우수.
- WS 모델 DER = 46.02 % 역시 LIUM보다 개선.
- WER와 DER 사이의 상관관계를 분석한 결과, 낮은 WER이 DER을 낮추는 필요조건이지만 충분조건은 아니라는 점을 강조.
**논의 및 한계**
- 텍스트와 음향을 결합하면 화자 전환 검출이 향상되지만, ASR 오류가 전반적인 다이어리제이션 성능을 크게 저해한다.
- 현재 모델은 단일 최우수 전사만을 입력으로 사용하므로, ASR 래티스나 N‑best 후보를 활용해 불확실성을 모델링하면 성능 회복이 기대된다.
- MFCC 외에 i‑vector, d‑vector 등 고차원 음향 임베딩을 도입하거나, 더 깊은 Transformer 기반 인코더/디코더 구조를 적용하면 추가 개선 가능성이 있다.
**결론**
본 연구는 Seq2Seq 기반 멀티모달 화자 다이어리제이션 모델을 제안하고, 텍스트와 음향 정보를 동시에 활용했을 때 DER이 유의미하게 감소함을 실험적으로 입증하였다. 그러나 실제 서비스 환경에서는 ASR 정확도가 핵심 병목이며, 향후 연구는 ASR 불확실성 통합, 고급 음향 특징, 그리고 엔드‑투‑엔드 학습을 통해 이 문제를 해결하는 방향으로 진행될 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기