음성 및 언어 임베딩을 활용한 방언 인식 종단 종단 시스템
본 논문은 아랍어 방언 식별을 위해 음향 특징(MFCC, FBANK, 스펙트로그램)과 텍스트 기반 언어 임베딩을 결합한 두 가지 종단‑종단 모델을 제안한다. CNN 기반 end‑to‑end 시스템과 Siamese 네트워크 기반 임베딩을 각각 학습하고, 단일 특징만 사용할 경우 73%의 정확도를, 다중 특징을 융합한 경우 78%의 정확도를 달성하였다. 데이터 증강(속도·볼륨 변조)과 무작위 세그멘테이션이 성능 향상에 기여했으며, 언어 임베딩은 차…
저자: Suwon Shon, Ahmed Ali, James Glass
본 논문은 아랍어 방언 식별(DID) 과제를 대상으로, 음향 특징과 언어 임베딩을 결합한 두 가지 종단‑종단 모델을 제안하고, 이를 MGB‑3 데이터셋(5개 방언, 총 63.6시간 훈련, 10.1시간 테스트)에서 평가하였다.
첫 번째 모델은 CNN 기반 end‑to‑end 구조이다. 입력으로 MFCC, FBANK, 스펙트로그램을 각각 40(또는 200) 차원으로 추출하고, 1‑차원 CNN 4계층(필터 크기 40×5, 500×7, 500×1, 500×1)과 전역 평균 풀링(Global Average Pooling)을 통해 프레임‑레벨 출력을 발화‑레벨 고정 길이(3000) 벡터로 변환한다. 이후 두 개의 완전 연결층(1500‑600)과 Softmax 레이어(5 클래스)를 거쳐 방언을 직접 분류한다. 학습은 SGD(learning rate 0.001, 0.98 decay per 50k 배치)와 ReLU 활성화를 사용했으며, 입력 특성은 0‑mean·unit‑variance 정규화를 적용하였다.
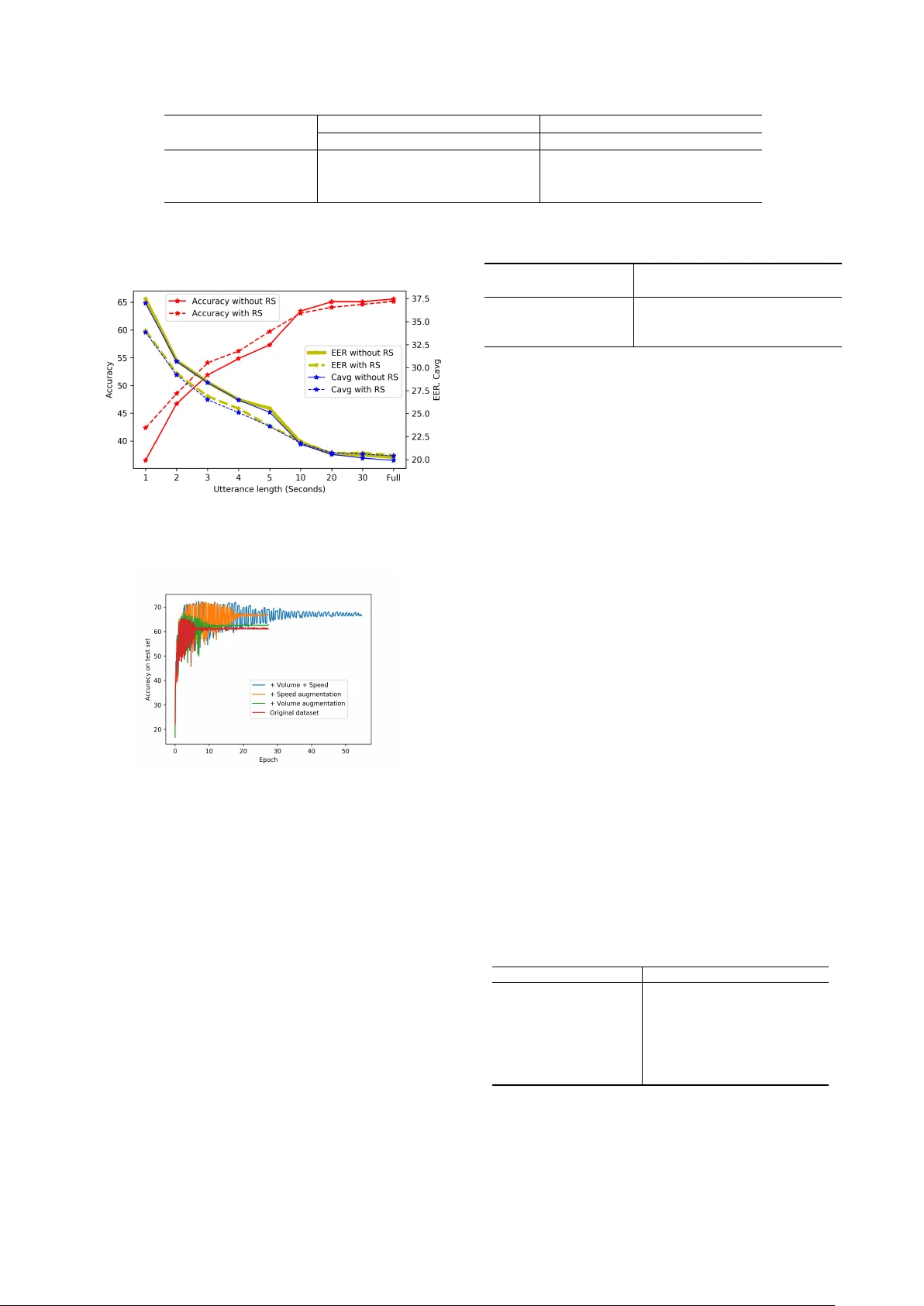
데이터 증강 측면에서, 속도 변조(0.9×, 1.1×)와 볼륨 변조(0.25×, 2.0×)를 적용해 원본 데이터의 다양성을 확대하였다. 또한, 훈련 배치 내에서 2~10초 길이의 무작위 세그멘테이션을 수행해 짧은 발화에 대한 모델의 강인성을 높였다. 실험 결과, FBANK 기반 모델이 MFCC보다 약간 높은 정확도(73% 근접)를 보였으며, 스펙트로그램은 57% 수준으로 낮았다.
두 번째 모델은 언어 임베딩을 추출하기 위한 Siamese 네트워크이다. 먼저, ASR 시스템(시간 지연 신경망 또는 BLSTM)으로부터 단어, 문자, 음소 시퀀스를 추출하고, 이를 VSM(벡터 공간 모델) 형태로 변환한다. 단어 VSM은 466k 차원의 트라이그램 사전을 사용하고, 문자·음소 VSM은 각각 13~51k 차원의 n‑그램 히스토그램을 만든다. 이러한 고차원 희소 벡터는 SVM 기반 코사인 유사도 측정에 활용되었다.
Siamese 네트워크는 두 개의 동일 가중치 서브넷(G_W)으로 구성되며, 입력 쌍(u_d, ~u) 사이의 코사인 유사도를 Euclidean 거리 손실 L = ||Y − D_W(u_d, ~u)||²로 최적화한다. 여기서 Y는 동일 방언이면 +1, 다른 방언이면 −1이다. 네트워크 내부는 FC 레이어(1500‑600‑200)와 ReLU 활성화로 이루어져 있으며, 마지막 은닉층(200 차원)에서 추출된 임베딩이 언어 간 유사성을 반영한다. 이 임베딩은 차원 축소와 동시에 판별력을 유지한다.
비교 실험에서는 i‑vector 기반 베이스라인(400 차원, LDA 후 4 차원)과 전통적인 BN 특징, 그리고 다양한 음소 인식기(체코, 헝가리, 러시아, 영어)에서 추출한 특징들을 포함하였다. i‑vector은 Cosine Similarity와 Gaussian Backend로 스코어링했으며, LDA를 적용해 차원을 크게 축소했다.
전체 시스템 성능을 평가한 결과, 단일 특징(음향 또는 언어)만 사용할 경우 최고 73% 정확도를 기록했으며, 다중 특징을 융합한 경우 78% 정확도에 도달하였다. 특히, 음향 기반 CNN과 언어 임베딩을 결합한 융합 모델이 가장 높은 성능을 보였으며, 이는 두 특징 공간이 서로 보완적인 정보를 제공한다는 점을 확인시켜준다. 데이터 증강은 특히 속도 변조가 모델의 일반화 능력을 크게 향상시켰으며, 무작위 세그멘테이션은 짧은 발화에 대한 인식 정확도를 개선하였다.
결론적으로, 본 연구는 제한된 방언 데이터셋에서도 음향‑언어 융합과 효과적인 데이터 증강을 통해 높은 방언 식별 성능을 달성할 수 있음을 입증한다. 제안된 end‑to‑end CNN 구조와 Siamese 기반 언어 임베딩은 각각 음성 신호와 텍스트 정보를 효율적으로 활용하며, 향후 다국어·다방언 인식 시스템에 적용 가능한 일반화 가능한 프레임워크를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기