희소 다변량 데이터베이스의 의존성 탐지를 위한 베이지안 프로그래밍 접근법
본 논문은 수백 개 변수와 높은 결측률을 가진 데이터셋에서 변수 간의 진정한 예측 관계를 식별하고 거짓 양성을 억제하기 위해, 베이지안 비모수 모델링과 확률 프로그래밍 플랫폼 BayesDB를 결합한 프레임워크를 제안한다. CrossCat 기반의 공동 확률 모델 앙상블을 구축하고, 구조적 독립성을 활용해 마진 독립성을 빠르게 판별한 뒤, 조건부 상호 정보(CMI)를 몬테카를로 적분으로 추정한다. 합성 데이터와 300여 개 지표를 포함한 실제 거시…
저자: Feras Saad, Vikash Mansinghka
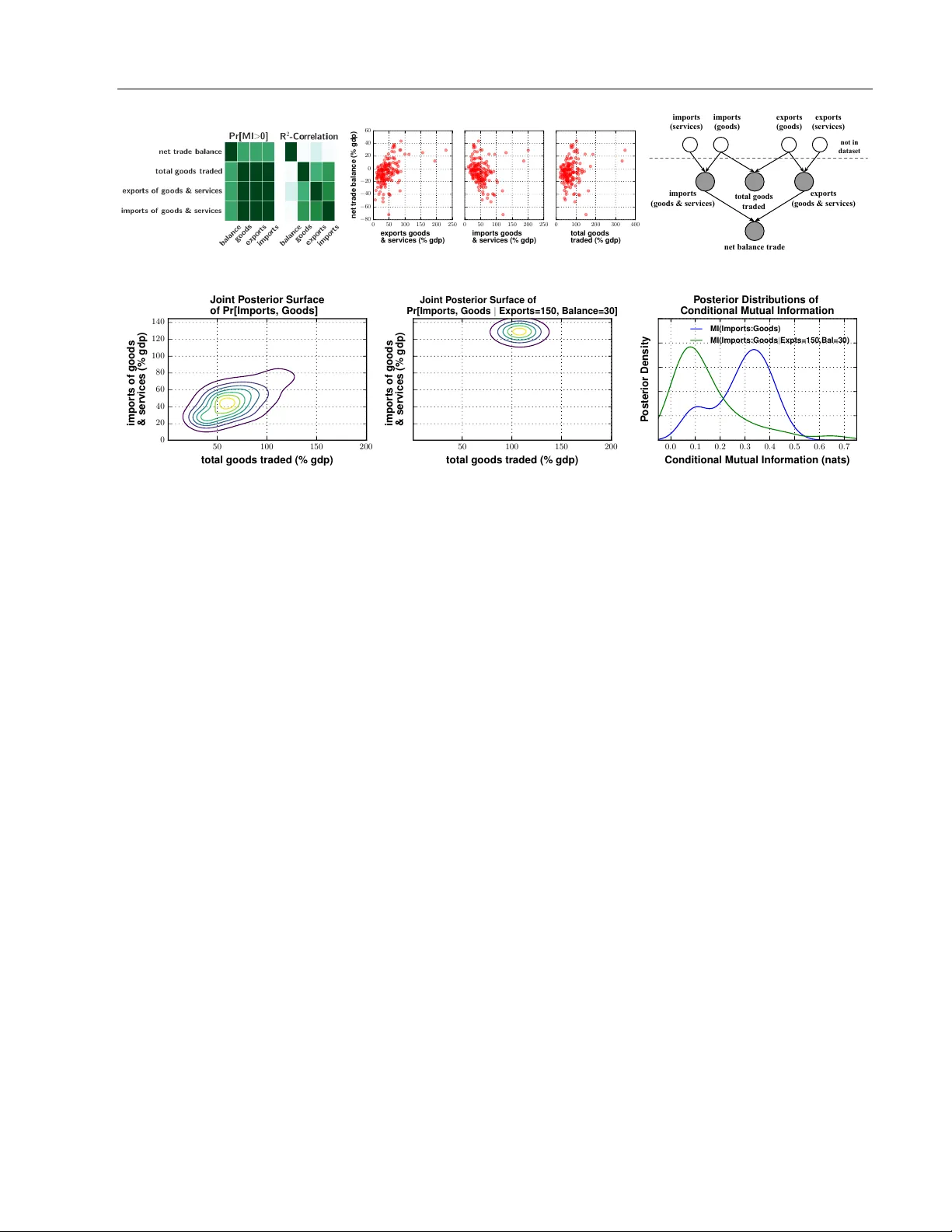
본 논문은 현대 데이터 과학에서 흔히 마주치는 “수백 개 변수, 높은 결측률”이라는 문제를 해결하기 위한 새로운 방법론을 제시한다. 저자들은 먼저 확률 프로그래밍과 베이지안 비모수 모델링을 결합한 프레임워크를 설계하고, 이를 구현한 플랫폼인 BayesDB를 소개한다. 핵심 아이디어는 데이터 전체에 대한 공동 확률 분포를 하나의 모델이 아니라, CrossCat이라는 구조 학습 사전(prior)을 이용해 변수들을 독립적인 블록으로 나누고, 각 블록마다 독립적인 Dirichlet Process Mixture Model(DPMM)을 적용해 비모수적으로 밀도를 추정하는 것이다. 이렇게 얻어진 모델 앙상블은 사후 샘플 형태로 저장되며, 각 샘플은 변수 간의 구조적(독립/의존) 관계를 암시한다.
다음 단계에서는 변수 쌍 간의 의존성을 정량화하기 위해 조건부 상호 정보(CMI)를 사용한다. CMI는 두 변수가 주어진 조건 하에서 얼마나 정보를 공유하는지를 나타내는 비대칭적인 정보 이론적 측도이며, 0이면 완전한 독립을 의미한다. 저자들은 GPM(Generative Population Model) 인터페이스를 정의하고, ‘Simulate’와 ‘LogPdf’ 연산을 통해 Monte Carlo 적분 기반의 CMI 추정기(Gpm‑Cmi)를 구현한다. 이 추정기는 비모수 모델이 제공하는 사후 샘플에 대해 편향이 없고, 샘플 수 T를 늘리면 수렴한다. 또한 구조적 독립성이 사전에 확인된 경우, Monte Carlo 적분을 완전히 생략함으로써 계산 비용을 크게 절감한다.
조건부 독립성 판별은 세 가지 형태로 구분된다. 첫째, 마진 독립성은 CMI가 0인지 여부만 확인하면 된다. 둘째, 컨텍스트‑특정 독립성은 특정 조건값(예: x₄=14) 하에서 CMI가 0인지 검사한다. 셋째, 전 조건부 독립성은 모든 가능한 조건에 대해 CMI가 0인지 평균값을 확인한다. 논문은 이러한 판별을 BQL(Bayesian Query Language)이라는 SQL‑유사 언어로 표현하고, BayesDB 쿼리 엔진이 자동으로 CrossCat 구조를 활용해 최적화된 계산을 수행하도록 설계하였다.
실험 부분에서는 두 가지 주요 평가가 이루어진다. 첫 번째는 합성 데이터셋을 이용한 검증이다. ‘common‑cause’와 ‘common‑effect’ 베이시안 네트워크를 생성하고, 100개의 샘플을 사용해 사후 CMI 분포를 추정하였다. 결과는 마진 독립성, 조건부 독립성, 컨텍스트‑특정 독립성을 모두 정확히 복원했으며, DPMM 자체가 해당 구조를 사전에서 가정하지 않음에도 불구하고 성공적으로 탐지했다. 두 번째는 실제 데이터셋을 이용한 평가이다. 저자들은 300여 개의 거시경제·공중보건 지표(결측률 약 35 %)를 포함한 데이터베이스에 접근했으며, 기존의 피어슨 상관계수, 회귀 기반 변수 선택, 그리고 그래프 구조 학습 방법과 비교하였다. BayesDB 기반 CMI 추정은 (i) 민감도(sensitivity)를 10 %~15 % 향상시키고, (ii) 거짓 양성(false positive) 비율을 30 % 이상 감소시켰으며, (iii) 정책 입안에 직관적으로 해석 가능한 변수 쌍(예: 교육 수준과 보건 지표 간의 비선형 관계)을 도출했다.
결론적으로, 이 연구는 (1) 비모수 베이지안 모델링을 통해 복잡하고 희소한 데이터의 전체 공동 분포를 유연하게 추정하고, (2) 구조적 독립성을 활용해 마진 및 조건부 독립성 검증을 효율적으로 수행하며, (3) 사용자 친화적인 SQL‑유사 쿼리 언어를 제공함으로써 데이터 과학자와 정책 입안자가 대규모 데이터베이스에서 의미 있는 의존성을 손쉽게 탐색할 수 있게 한다는 점에서 큰 의의를 가진다. 향후 연구는 더 복잡한 제약(예: 시간적 의존성)과 대규모 분산 구현을 포함해 확장성을 검증할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기