페이스넷 임베딩으로 티inder 프로필 자동 분류: 개인 맞춤형 모델 구축
본 논문은 사용자의 과거 ‘좋아요/싫어요’ 기록을 기반으로 FaceNet으로 추출한 얼굴 임베딩을 특징으로 활용해 Tinder 프로필을 자동으로 분류하는 개인 맞춤형 모델을 제안한다. 단일 얼굴 이미지만을 대상으로 두 가지 임베딩 집계 방법(전체 임베딩 연결 vs 평균)으로 특징을 만들고, 로지스틱 회귀, SVM, 신경망 등을 학습시켰다. 20개의 라벨링된 프로필만으로도 65% 검증 정확도를 달성했으며, 80개 정도에서 정확도 상승이 완만해져 …
저자: Charles F Jekel, Raphael T. Haftka
본 논문은 Tinder와 같은 온라인 데이팅 플랫폼에서 사용자가 프로필을 일일이 검토하는 과정을 자동화하기 위해, 개인 맞춤형 얼굴 기반 분류 모델을 제안한다. 연구자는 FaceNet이라는 사전 학습된 얼굴 인식 모델을 활용해, 사용자가 과거에 ‘좋아요’ 혹은 ‘싫어요’를 표시한 프로필 이미지에서 얼굴 임베딩을 추출한다. 전체 데이터는 한 명의 이성애 남성 사용자가 한 달 동안 검토한 8,545개의 Tinder 프로필이며, 이 중 2,411개는 ‘좋아요’로 라벨링되었다. 각 프로필은 평균 3.01장의 단일 얼굴 이미지를 포함하고, 총 38,218장의 이미지가 수집되었다.
데이터 전처리 단계에서는 MTCNN을 사용해 640×640 픽셀 이미지에서 최소 60×60 픽셀 크기의 단일 얼굴을 검출하고, 182×182 픽셀로 정규화하였다. 다중 얼굴이 포함된 사진은 완전히 제외했으며, 결과적으로 8,130개의 프로필(95.1%)이 단일 얼굴 이미지로 변환되었다. 검출 과정에서 발생한 가짜 양성(예: 스냅챗 필터 적용 얼굴)은 제거하지 않고 학습에 포함시켜 모델의 강건성을 높이려는 시도를 보였다.
특징 추출 방법은 두 가지로 나뉜다. 첫 번째는 각 이미지의 128차원 임베딩을 모두 연결해 128 × n 차원의 고차원 벡터(i_p)를 만드는 방식이다. 두 번째는 동일 프로필 내 모든 임베딩을 평균해 128차원 벡터(i_avg)를 얻는 방식이다. i_p는 최대 10장의 이미지까지 0 패딩을 사용해 고정 길이로 맞추었으며, i_avg는 차원 감소와 계산 효율성을 제공한다.
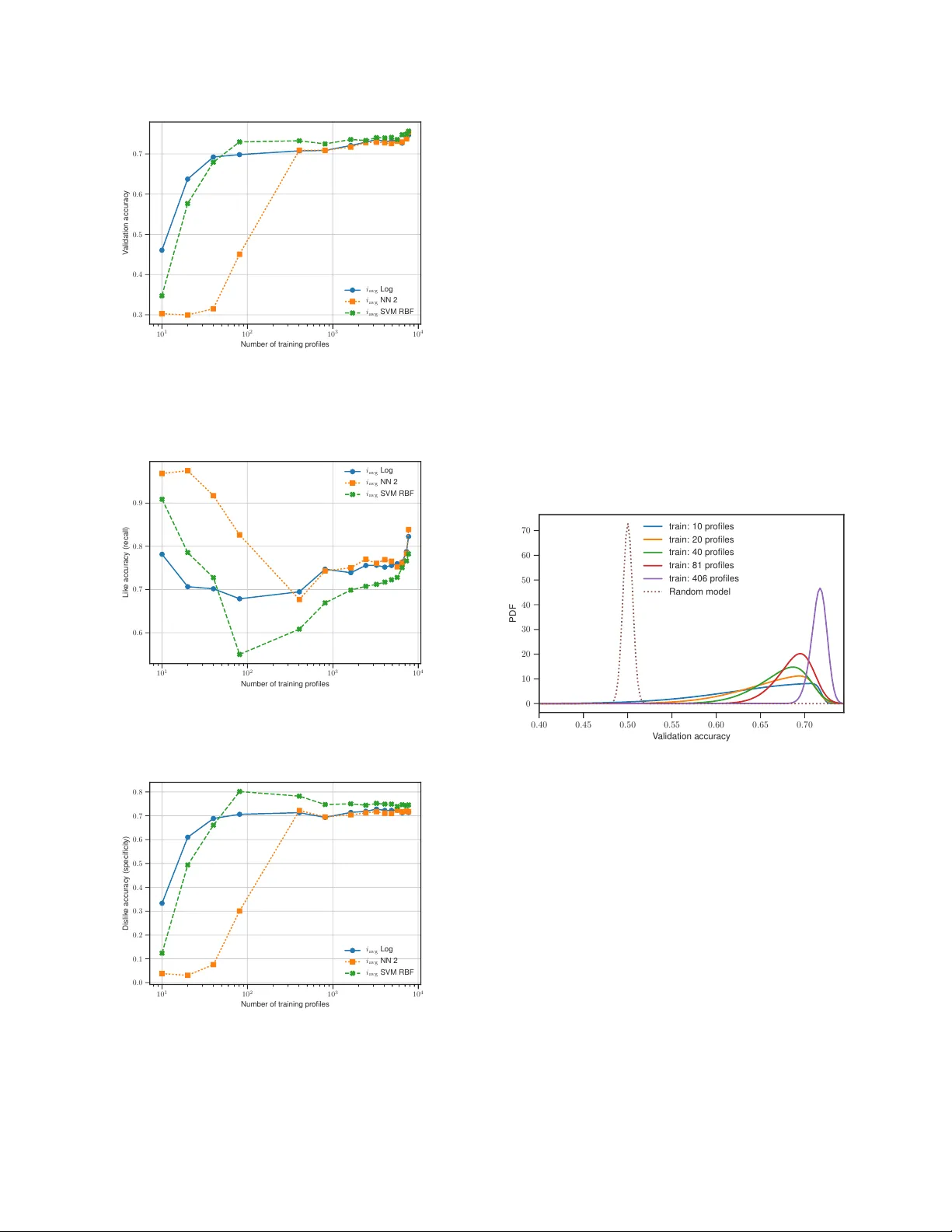
분류 모델로는 로지스틱 회귀, RBF 커널 SVM, 두 종류의 신경망(NN1, NN2)을 사용했으며, Scikit‑learn과 TensorFlow/Keras를 통해 구현하였다. 모델 학습은 전체 데이터의 0.125%(10개 프로필)부터 95%(7,723개 프로필)까지 다양한 샘플 크기로 수행했으며, 무작위 10:1 훈련‑검증 비율을 기본으로 했다. 클래스 불균형(좋아요 28%)을 고려해 균형 가중치를 적용했으며, 정확도 외에 ‘좋아요 정확도(재현율)’와 ‘싫어요 정확도(특이도)’도 보고하였다.
성능 평가 결과, 로지스틱 회귀와 신경망이 AUC 0.82~0.83 수준으로 비슷한 성능을 보였으며, i_avg와 i_p 간에 큰 차이는 없었다. 특히 로지스틱 회귀는 20개의 라벨링된 프로필만으로도 검증 정확도 65%를 달성했으며, 80개 정도에서 정확도 상승이 완만해져 최종 73%에 머물렀다. 학습 정확도는 0.75 수준에 수렴했으며, ‘좋아요 정확도’는 0.7, ‘싫어요 정확도’는 0.6 정도였다. SVM은 ‘싫어요’에 편향된 경향을 보였고, 신경망은 ‘좋아요’에 편향되었다.
연구의 주요 가정은 (1) 프로필 판단은 이미지만으로 가능, (2) 단일 얼굴을 정확히 검출할 수 있음, (3) 다중 얼굴 사진은 무시해도 무방, (4) 사용자의 선호에 일관된 얼굴 패턴이 존재, (5) 사전 학습된 FaceNet이 새로운 얼굴에 대해 유효한 임베딩을 제공한다는 것이다. 이러한 가정은 실제 서비스 적용 시 제한점으로 작용할 수 있다. 예를 들어, 프로필에 텍스트, 직업, 위치 등 비시각적 정보가 큰 영향을 미칠 수 있으며, 다중 얼굴 사진을 완전히 배제하면 중요한 사회적 신호를 놓칠 위험이 있다.
윤리적·사회적 논의도 포함된다. 데이터가 한 명의 남성 사용자에 국한돼 있어 성별·연령·인종 편향이 존재한다. 얼굴만으로 ‘매력도’를 판단하는 자동화는 차별적 결과를 초래할 가능성이 크다. 따라서 향후 연구에서는 다수 사용자와 다양한 인구통계학적 그룹을 포함한 데이터셋 구축, 공정성 및 편향 측정, 그리고 사용자가 모델 결과에 대해 피드백을 제공할 수 있는 인터페이스 설계가 필요하다.
결론적으로, 이 논문은 얼굴 임베딩을 활용한 개인 맞춤형 프로필 분류가 소량의 라벨링 데이터만으로도 실용적인 수준의 성능을 달성할 수 있음을 보여준다. 그러나 모델의 정확도 한계, 데이터 편향, 윤리적 문제 등을 고려해 실제 서비스에 적용하려면 추가적인 연구와 보완이 요구된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기