단일채널 음원 분리에서 위상 정보의 실질적 효과
본 연구는 인간 청각계가 위상 정보를 유지한다는 생물학적 근거를 바탕으로, 위상 정보를 보존한 스펙트럼 표현이 단일채널 보컬 분리 성능에 미치는 영향을 조사한다. 512‑점 STFT 기반의 위상 보존형과 위상 제거형 데이터를 각각 희소 코딩(LCA)으로 학습시킨 뒤, GSIR, GSAR, GNSDR 지표로 평가하였다. 결과는 위상 보존이 인공물(artifact) 감소에 기여함을 보여주지만 전체 왜곡 감소에는 큰 차이가 없으며, 후처리된 ‘Den…
저자: Mohit Dubey, Garrett Kenyon, Nils Carlson
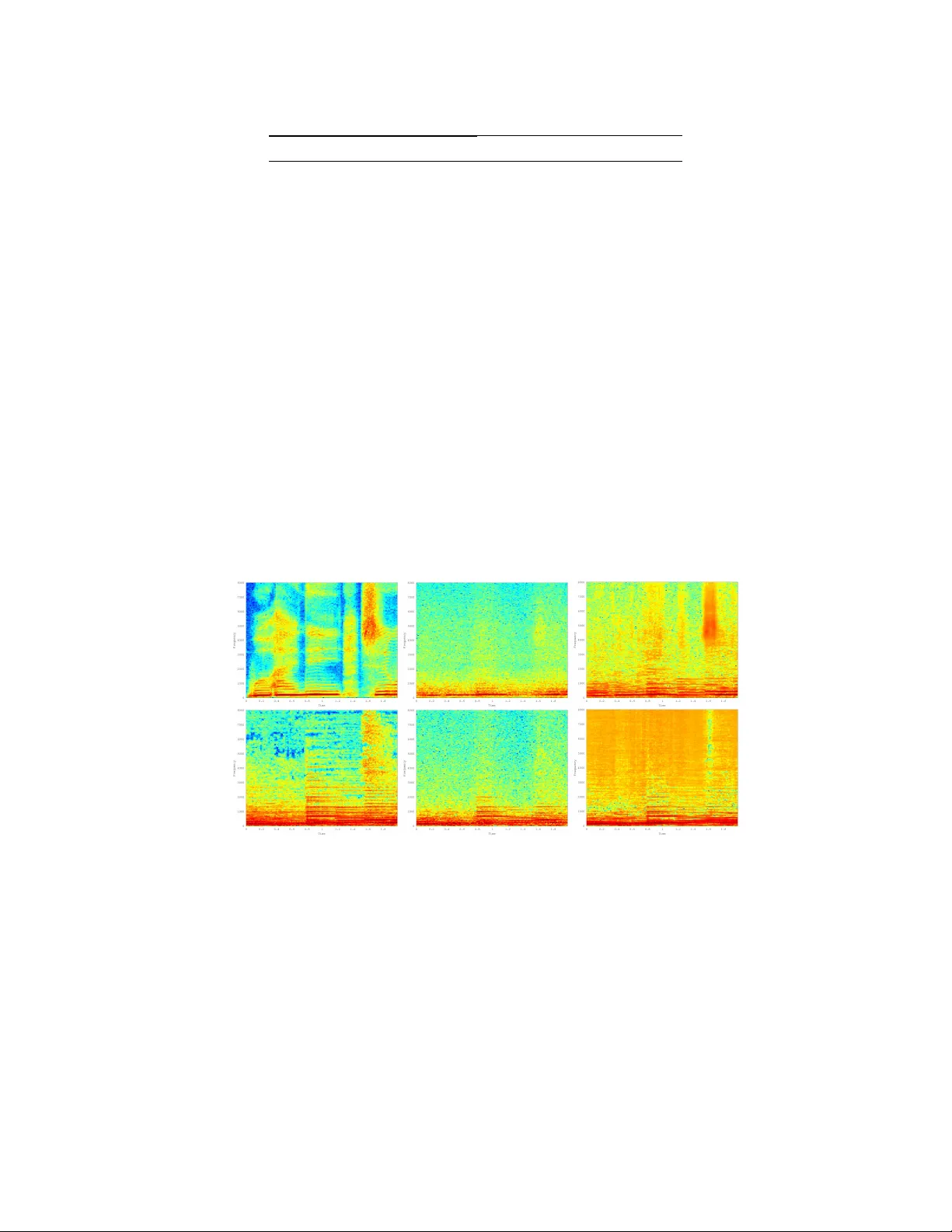
본 논문은 인간 청각계가 소리를 분석할 때 위상 정보를 지속적으로 활용한다는 신경생리학적 근거를 바탕으로, 단일채널(모노) 음원에서 보컬을 분리하는 작업에 위상 정보를 포함시키는 것이 실제로 성능 향상에 기여하는지를 실험적으로 검증한다. 연구자는 먼저 MIR‑1K 데이터셋을 선택하였다. 이 데이터셋은 1000개의 4~16초 길이의 중국어 카라오케 트랙으로 구성돼 있으며, 보컬과 반주가 각각 스테레오 채널에 별도로 저장돼 있다. 실험 편의를 위해 모든 클립을 2초로 잘라내고, 16 kHz로 재샘플링하였다. 이후 보컬과 반주를 동일 비율로 섞어 단일채널 혼합 신호를 만든다.
스펙트럼 변환 단계에서는 512‑점 STFT를 적용해 256개의 주파수 bin(0~8 kHz)과 128개의 시간 프레임을 얻었다. 두 가지 변형을 만든다. 첫 번째는 복소수 형태(실수·허수)를 모두 보존한 “위상 보존” 스펙트럼이며, 두 번째는 절댓값(진폭)만을 남긴 “위상 제거” 스펙트럼이다. 위상 제거 경우 정보량이 절반으로 감소하는 것을 보정하기 위해 주파수 bin을 512개(즉, 2배)로 늘렸다. 이렇게 구성된 세 개의 데이터셋(Phase, No‑Phase, No‑Phase × 2)은 동일한 학습 파이프라인에 투입된다.
학습 알고리즘은 Locally Competitive Algorithm(LCA)이다. LCA는 입력 I와 딕셔너리 Φ, 활성화 a 사이의 에너지 함수 E(I, Φ, a)=‖I‑Φa‖²+λ‖a‖₁을 최소화한다. 여기서 λ는 희소성 페널티이며, 저자는 여러 λ 값을 실험한 뒤 0.625가 최적임을 확인했다(희소도 약 2.8 %). 활성화 a는 연속 시간 미분 방정식 du/dt=‑∂E/∂a에 따라 업데이트되며, Φ는 Hebbian 규칙과 모멘텀을 결합한 확률적 경사 하강법으로 학습된다. 네트워크는 8192개의 과잉완전(2배 오버컴플리트) 필터를 사용했으며, 각 필터는 전체 주파수 축과 128 ms 길이의 시간 영역을 포괄한다. 학습은 4 epoch 동안 진행되었다.
학습이 완료된 뒤, 각 데이터셋에 대해 얻어진 희소 코드를 기반으로 선형 분류기를 40 epoch 훈련시켜 보컬과 반주를 구분하였다. 분리된 트랙은 BSS_EVAL 프레임워크를 이용해 GSIR(신호‑간섭 비율), GSAR(신호‑인공물 비율), GNSDR(전체 신호‑왜곡 비율)로 평가되었다. 결과는 표 1에 요약된다. 위상 보존 모델은 GSAR이 3.51 dB(±5.92)로 가장 높아 인공물 감소에 유리했지만, GSIR(12.12 dB)와 GNSDR(1.49 dB)는 위상 제거 모델과 큰 차이를 보이지 않았다. 위상 제거 모델은 주파수 bin을 두 배로 늘린 “No‑Phase × 2” 변형에서 GSIR 14.84 dB, GSAR –10.95 dB를 기록했으나, 이는 인공물 증가와 연관된다. 마지막으로, 위상 보존 모델에 추가적인 잡음 제거(denoising) 과정을 적용한 ‘Denoised’ 버전은 GSIR 19.46 dB(±8.61), GSAR 2.88 dB, GNSDR 5.21 dB를 달성했으며, 이는 기존 문헌에 보고된 최고 수준의 성능과 일치한다.
논문의 주요 기여는 다음과 같다. (1) 위상 정보를 보존한 스펙트럼이 희소 코딩 기반의 단일채널 보컬 분리에서 인공물 감소에 기여한다는 실증적 증거를 제공한다. (2) 위상 보존 여부가 전체 SIR이나 SDR에 큰 영향을 미치지 않으며, 이는 현재 사용된 LCA 구조가 복소수 정보를 충분히 활용하지 못하거나, 평가 데이터가 제한적이기 때문일 가능성을 시사한다. (3) 후처리 단계(denoising)를 통해 위상 보존 모델이 현존 최고 수준의 SIR을 달성할 수 있음을 보여준다.
하지만 몇 가지 한계점도 존재한다. 첫째, 실험에 사용된 클립이 2초로 매우 짧아 실제 음악 스트림의 장기적 구조(멜로디, 화성, 리듬)를 반영하지 못한다. 둘째, MIR‑1K는 주로 중국어 카라오케이며, 보컬과 반주의 스펙트럼 특성이 제한적이므로 일반화 가능성이 낮다. 셋째, LCA는 비교적 단순한 선형 희소 코딩이며, 현대의 복합 신경망(예: 복소수 CNN, Transformer)과 비교했을 때 표현력이 제한적이다. 따라서 향후 연구에서는 (a) 더 긴 멀티 장르 데이터셋, (b) 심층 복소수 네트워크와의 하이브리드, (c) 계층적 희소 코딩을 도입해 위상 정보를 다층적으로 활용하는 방안을 탐색할 필요가 있다.
결론적으로, 위상 정보를 보존하면 인공물 감소라는 구체적인 이점을 얻을 수 있지만, 전체적인 소스 분리 성능을 크게 끌어올리려면 보다 정교한 모델 설계와 풍부한 데이터가 필수적이다. 이 연구는 청각 신경과학과 신호 처리 사이의 교차점을 제시하며, 향후 위상‑중심 알고리즘 개발에 중요한 토대를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기