대규모 딥러닝 학습을 위한 고성능 파라미터 서버 GaDei
GaDei는 작은 미니배치와 높은 통신 빈도가 요구되는 Training‑as‑a‑Service(TaaS) 환경을 위해 설계된 공유 메모리 기반 스케일‑업 파라미터 서버이다. 최소 복사, Hogwild!식 무잠금 업데이트, 온‑디바이스 이중 버퍼링을 결합해 GPU 간 통신 병목을 해소하고, 데드락‑프리와 정확도 보장을 이론적으로 증명한다. 실험 결과, 기존 MPI‑기반 또는 NCCL‑기반 솔루션보다 10배 가량 빠르며, 장애 복구 기능도 제공한다…
저자: Wei Zhang, Minwei Feng, Yunhui Zheng
본 논문은 기업용 딥러닝 Training‑as‑a‑Service(TaaS) 워크로드의 특성을 분석하고, 이를 만족시키는 새로운 스케일‑업 파라미터 서버 시스템인 GaDei를 제안한다. TaaS는 고객이 직접 하이퍼파라미터를 튜닝할 여력이 없으며, 서비스 제공자는 모든 고객에게 동일한 모델과 하이퍼파라미터 설정을 제공해야 한다. 이러한 요구는 모델 정확도를 보장하기 위해 작은 미니배치와 낮은 학습률, 그리고 높은 통신 빈도를 필요로 한다. 그러나 기존의 파라미터 서버 기반 시스템은 매 미니배치마다 그래디언트를 교환해야 하므로 통신량이 급증하고, 특히 클라우드 환경의 제한된 대역폭에서는 성능 저하가 심각해진다.
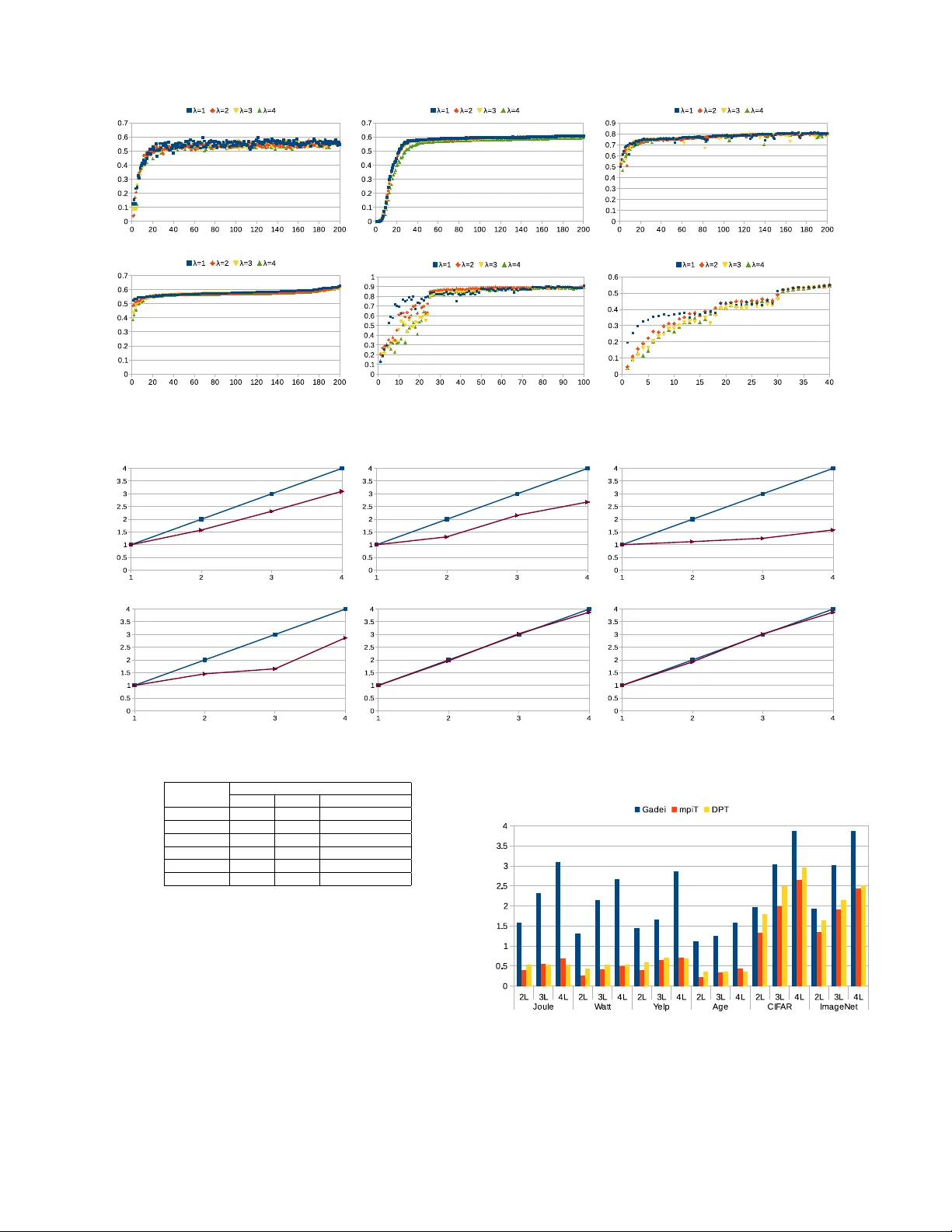
IBM Watson Natural Language Classifier(NLC) 서비스를 사례로 삼아, 논문은 실제 산업 데이터셋 4개에 대해 배치 크기를 1에서 128까지 변화시켰을 때 정확도가 크게 감소함을 실험적으로 입증한다(대부분 3~6% 손실). 또한, 통신 간격(CI)을 늘려 한 번에 여러 배치를 처리하도록 하면 GPU 활용률은 상승하지만, 스터일리시(staleness)가 커져 모델 수렴 속도가 급격히 떨어진다. 이러한 결과는 TaaS 환경에서 ‘작은 배치 + 빈번한 통신’이 필수임을 보여준다.
기존 스케일‑아웃 솔루션인 mpiT(다중 GPU를 MPI로 연결)와 DataParallelTable(DPT, NCCL 기반 동기식 SGD)는 각각 메모리 복사와 동기화 장벽으로 인해 높은 통신 빈도에 적합하지 않다. 특히 mpiT은 GPU‑간 복사와 MPI 런타임 오버헤드가 크고, DPT는 모든 GPU가 동기화될 때까지 대기하는 스트래글러 문제를 야기한다. 게다가 두 시스템 모두 장애 복구 메커니즘이 부재해 상업 서비스에 적용하기 어렵다.
이에 저자들은 GaDei라는 새로운 파라미터 서버 설계를 제안한다. GaDei는 동일 서버 내 다수의 GPU가 공유 메모리를 통해 직접 파라미터와 그래디언트를 교환하도록 설계되었다. 주요 최적화는 다음과 같다.
1. **최소 메모리 복사**: 파라미터와 그래디언트를 공유 메모리 큐에 직접 넣고 꺼내어, GPU‑CPU‑GPU 간 불필요한 복사를 제거한다.
2. **무잠금(Hogwild!) 업데이트**: 파라미터 서버는 락을 사용하지 않고, 여러 워커가 동시에 그래디언트를 적용한다. 이는 업데이트 충돌을 허용하되, 실험적으로 수렴에 큰 영향을 주지 않음이 증명된다.
3. **온‑디바이스 이중 버퍼링 및 멀티스트림**: 각 GPU는 두 개의 버퍼를 교대로 사용해 계산과 파라미터 전송을 동시에 수행한다. CUDA 스트림을 활용해 데이터 이동과 커널 실행을 파이프라인화함으로써 GPU가 대기 상태에 빠지는 것을 최소화한다.
이 설계는 이론적으로 **데드락이 없으며**, 각 그래디언트가 정확히 한 번만 처리된다는 것을 증명한다. 또한, 작은 미니배치가 스터일리시를 감소시켜 ASGD(비동기 SGD)의 수렴성을 보장한다는 수학적 근거를 제시한다.
실험은 6개의 워크로드(텍스트 분류, 이미지 분류, RNN 기반 모델 등)와 3개의 최신 딥러닝 모델(AlexNet, ResNet, LSTM)을 대상으로 수행되었다. 하드웨어는 NVIDIA K20, P100, V100 GPU를 탑재한 다중 GPU 서버이며, 비교 대상은 mpiT와 DPT이다. 결과는 다음과 같다.
- **성능**: GaDei는 동일 정확도 하에서 평균 5배~12배, 최악의 경우 20배에 달하는 학습 시간 단축을 달성했다. 특히 배치 크기가 1~4인 상황에서 가장 큰 이점을 보였다.
- **대역폭 활용**: 공유 메모리 기반 설계 덕분에 PCIe 대역폭 한계에 근접하는 수준으로 통신 효율을 끌어올렸다.
- **정확도**: 모든 실험에서 GaDei는 기존 PS 기반 시스템과 동일하거나 미세하게 높은 정확도를 유지했다.
- **장애 복구**: 워커가 중단되면 파라미터 서버가 남은 워커와 상태를 재조정해 학습을 계속 진행한다. 이는 서비스 수준 협약(SLA) 요구를 충족시키는 중요한 기능이다.
결론적으로, GaDei는 TaaS 환경에서 요구되는 보수적 하이퍼파라미터 설정을 그대로 유지하면서도, 통신 병목을 근본적으로 해소하고, 데드락‑프리·장애 복구까지 제공하는 실용적인 스케일‑업 파라미터 서버이다. 이는 클라우드 기반 딥러닝 서비스 제공자에게 비용 효율적인 고성능 학습 인프라를 제공하며, 향후 더 큰 모델과 데이터셋에도 확장 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기