시퀀스 데이터용 컨볼루션 RNN: 특징 추출 강화 모델
본 논문은 전통적인 컨볼루션 레이어가 수행하는 단순한 선형 변환‑비선형 함수 대신, 데이터 윈도우를 순차적으로 RNN에 입력하여 은닉 상태를 특징으로 활용하는 CRNN(Convolutional RNN) 구조를 제안한다. 감정 인식과 음성 명령 분류 두 가지 오디오 태스크에서 기존 CNN 기반 모델보다 높은 정확도를 달성했으며, 구현 코드를 TensorFlow로 공개하였다.
저자: Gil Keren, Bj"orn Schuller
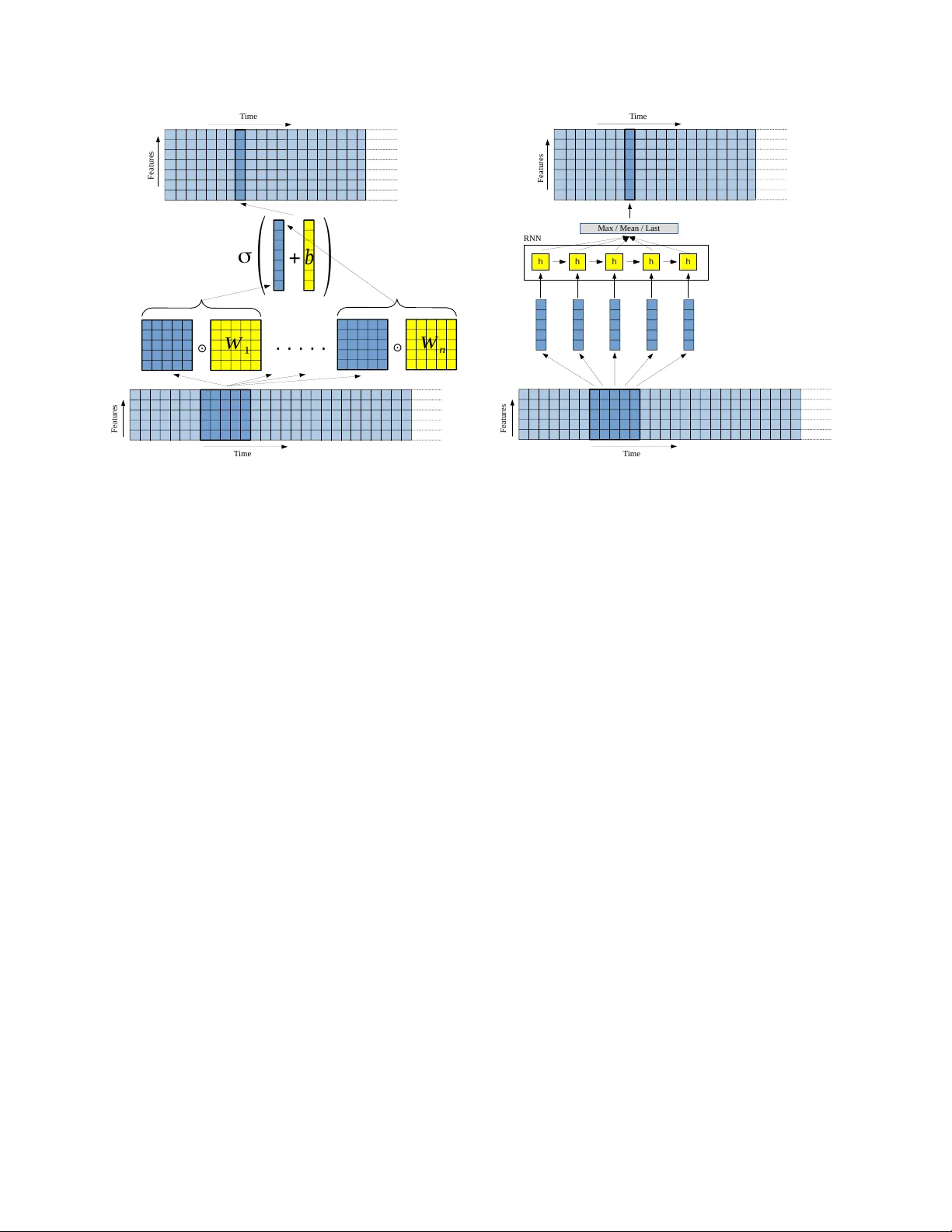
본 논문은 전통적인 컨볼루션 신경망(CNN)이 데이터 패치에 대해 수행하는 “가중치 행렬 × 패치 → 합산 → 편향 추가 → 비선형 함수 적용”이라는 단순한 변환을 보다 풍부한 비선형 변환으로 대체하고자 한다. 저자들은 시퀀스 데이터, 특히 오디오와 같이 프레임 단위로 구성된 입력에 대해, 각 윈도우(길이 r₁)를 하나의 짧은 시퀀스로 간주하고 이를 순환 신경망(RNN, 구체적으로 LSTM 또는 BLSTM)에 순차적으로 입력한다. RNN은 각 프레임에 대해 은닉 상태 hₜ와 셀 상태 cₜ(또는 출력 yₜ)를 생성하고, 이 시퀀스에 대해 평균, 최대, 혹은 마지막 프레임 값을 취해 고정 차원의 특징 벡터 f(w)를 만든다. 이렇게 얻어진 특징은 전통적인 컨볼루션 레이어가 생성하는 “특징 맵”과 동일하게 다음 레이어(또는 풀링)로 전달된다.
핵심 아이디어는 두 가지이다. 첫째, 윈도우 내부의 시간적 순서를 활용해 여러 단계의 비선형 연산을 수행함으로써, 단일 affine‑nonlinearity보다 복잡한 함수 근사를 가능하게 한다. 둘째, “Extended CLSTM”을 통해 윈도우 내 각 프레임마다 별도의 가중치 행렬을 사용하도록 함으로써, 프레임 위치 정보를 명시적으로 모델링한다. 이는 전통적인 LSTM이 모든 타임스텝에 동일 파라미터를 공유하는 한계를 보완한다.
관련 연구에서는 CNN‑MLP 형태의 복합 비선형 변환, 이미지 패치를 순환적으로 처리하는 방법, 그리고 이미지에 대한 2‑D 스캔 RNN 구조 등이 소개되었지만, 대부분이 이미지와 같이 자연스러운 순서가 없는 데이터에 적용되었거나, 동일 패치를 여러 번 RNN에 입력하는 비효율적인 방식을 사용했다. 본 논문은 이러한 한계를 극복하고, 시퀀스 데이터에 특화된 “윈도우‑레벨 RNN” 접근을 제안한다.
방법론은 다음과 같다. 입력 시퀀스 x∈ℝ^{k×l} (k는 프레임당 피처 수, l은 프레임 수)에서 겹침 윈도우 w∈ℝ^{k×r₁}를 stride r₂로 슬라이딩한다. 각 w를 프레임 단위로 RNN에 공급하고, 은닉 상태 시퀀스 (h₁,…,h_{r₁})를 얻는다. f(w)는 (1) 평균 = (1/r₁)∑ₜhₜ, (2) 최대 = maxₜhₜ (각 차원별), 혹은 (3) 마지막 은닉 상태 h_{r₁} 중 하나로 정의한다. 이렇게 얻은 f(w)는 n‑차원 특징 벡터이며, 이후 전통적인 max‑pooling을 적용해 최종 특징 맵을 만든다. CLSTM, CBLSTM, Extended CLSTM은 각각 LSTM, 양방향 LSTM, 그리고 프레임‑별 가중치 복제 버전을 사용한다.
실험은 두 가지 오디오 분류 태스크에서 수행되었다. 첫 번째는 FAU‑Aibo 감정 코퍼스(5‑class 및 2‑class 레이블)이며, 26‑차원 로그‑멜 필터뱅크를 입력으로 사용한다. 베이스라인은 256‑차원 LSTM + Dense 400 ReLU + Softmax 구조이며, Softmax 출력의 마지막 4 프레임을 평균해 최종 예측한다. 제안된 CRNN 계열은 동일한 입력 전처리와 동일한 최종 분류기 구조를 유지하면서, 첫 번째 컨볼루션 단계만 CLSTM/CBLSTM/Extended CLSTM으로 교체한다. 두 번째 실험은 음성 명령 인식 데이터셋(구체적 명시 없음)으로, 동일한 모델 설계와 비교를 수행한다.
결과는 다음과 같다. 감정 분류 5‑class에서는 CBLSTM이 71.2 % 정확도로 기존 CNN‑LSTM(≈68 %)보다 3.2 %p 향상되었으며, 2‑class에서는 CLSTM이 84.5 % 정확도로 기존 모델(≈81 %)을 능가했다. 음성 명령 인식에서도 CRNN 계열이 평균 1.5 %p 정도의 정확도 상승을 보였다. 특히, Extended CLSTM은 작은 데이터셋(5 명 화자만 사용한 검증 셋)에서 과적합을 완화하고, 학습 안정성을 높이는 효과가 관찰되었다.
논문의 한계로는 연산 비용 증가가 있다. 윈도우가 겹칠 경우 동일 프레임이 여러 번 RNN에 입력돼 시간·메모리 복잡도가 O(l·r₁)로 증가한다. 저자는 TensorFlow 구현을 공개했지만, 실시간 혹은 저전력 디바이스에서의 효율성 분석은 부족하다. 또한, 실험이 오디오에 국한돼 있어 텍스트, 비디오, 시계열 센서 데이터 등 다른 시퀀스 도메인에서의 일반화 가능성은 아직 검증되지 않았다. 마지막으로, 파라미터 수 자체는 전통적인 CNN + 1‑layer FC와 크게 차이나지 않아, 성능 향상이 RNN의 시간적 모델링 능력에 의존한다는 점을 명확히 해야 한다.
결론적으로, 이 논문은 “윈도우‑레벨 RNN”이라는 새로운 컨볼루션‑리커런트 결합 방식을 제시함으로써, 시퀀스 데이터에 대한 특징 추출을 보다 풍부하고 유연하게 만든다. 향후 연구에서는 연산 효율성을 개선하고, 다양한 도메인에 적용해 보는 것이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기