스펙트럼 기반 POMDP 강화학습 효율적 탐험과 메모리리스 최적 정책
본 논문은 부분관측 마코프 결정 과정(POMDP)에서 스펙트럼 분해를 이용해 모델 파라미터를 일관적으로 추정하고, 추정된 모델을 기반으로 메모리리스 정책을 최적화하는 SM‑UCRL 알고리즘을 제안한다. 에피소드마다 고정 정책으로 수집한 데이터를 텐서 분해로 학습하고, 상한 신뢰구간을 활용해 탐험‑활용 균형을 맞춘다. 저자는 최적 메모리리스 정책에 대한 O(D·X^{3/2}√(A·Y·R·N)) 형태의 차수 최적(regret) 상한을 증명하며, 관…
저자: Kamyar Azizzadenesheli, Aless, ro Lazaric
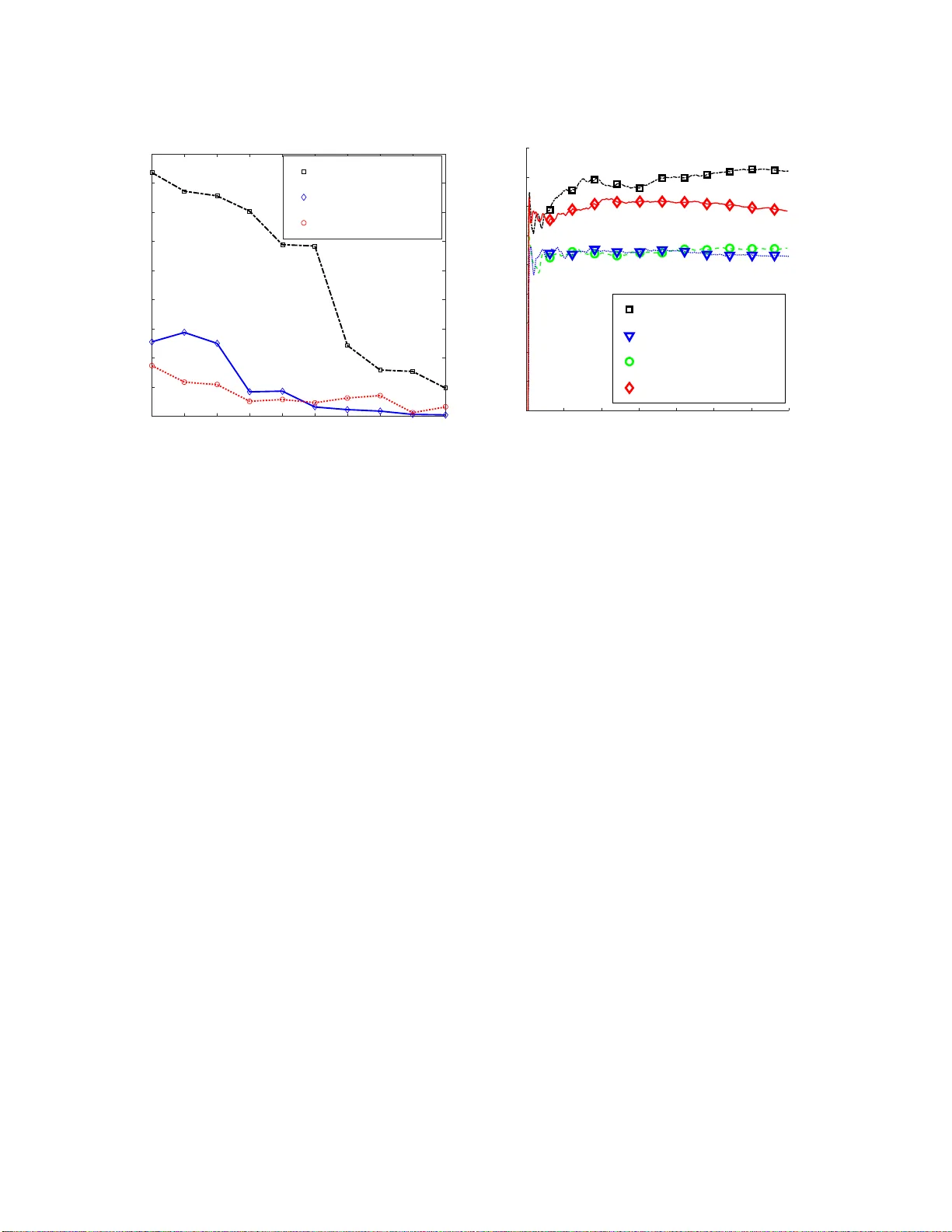
본 논문은 부분관측 마코프 결정 과정(POMDP)에서 강화학습(RL) 문제를 해결하기 위해 스펙트럼 분해 기법을 도입한 새로운 알고리즘 SM‑UCRL(Spectral Method for Upper‑Confidence Reinforcement Learning)을 제안한다. 기존 RL 연구는 대부분 완전 관측 가능한 MDP를 전제로 하며, POMDP와 같이 관측이 노이즈가 섞인 경우에는 상태 전이와 보상 모델을 직접 추정하기 어렵다. 저자는 이러한 어려움을 두 가지 핵심 요소로 나눈다. 첫 번째는 숨겨진 변수 모델(LVM)의 파라미터를 일관적으로 추정하는 문제이며, 두 번째는 추정된 모델을 기반으로 최적 정책을 계산하고 탐험‑활용 균형을 맞추는 문제이다.
스펙트럼 방법은 HMM 등에서 성공적으로 적용된 바 있으며, 관측이 숨겨진 상태보다 많을 때(Y > X) 텐서 분해를 통해 전이, 관측, 보상 확률을 추정한다. POMDP의 경우 행동이 관측에 영향을 주어 독립성이 깨지지만, 메모리리스 정책을 고정하면 각 행동별로 조건부 독립적인 다중 뷰를 구성할 수 있다. 이를 기반으로 각 행동 a에 대해 3차 텐서를 구성하고, 고차원 행렬‑벡터 분해를 수행해 \(\hat{f}_T, \hat{f}_O, \hat{f}_R\)을 얻는다. 저자는 새로운 행렬 Azuma 부등식과 기존의 집중 부등식(Kontorovich 등)을 결합해, 정책이 에피소드마다 바뀌어도 샘플이 비정상적인 분포에서 나오더라도 고확률 오차 경계
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기