드롭아웃 기반 신경망 압축: 효율적인 모델 경량화 기법
본 논문은 드롭아웃 학습 과정에서 각 유닛별 유지 확률을 베타 사전으로 제어함으로써, 학습 중 자동으로 불필요한 은닉 유닛을 제거하고 최종적으로 50% 이하의 파라미터로도 원본 모델과 동등한 성능을 달성하는 “드롭아웃 컴팩션” 방법을 제안한다. 실험은 MNIST와 실제 음성 인식 과제에서 수행되었으며, 압축률 2.5배에 가까운 추론 속도 향상을 보였다.
저자: Yotaro Kubo, George Tucker, Simon Wiesler
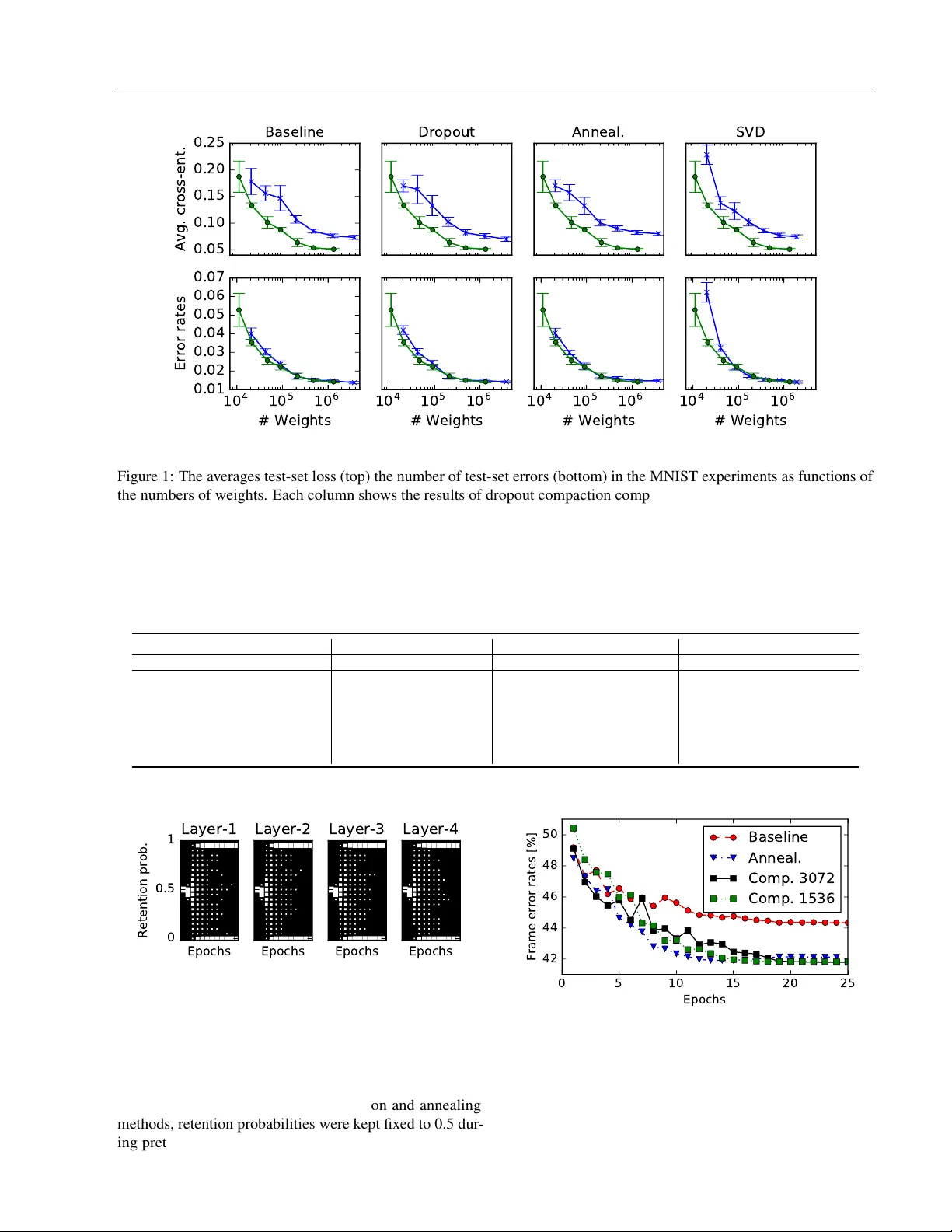
본 논문은 대규모 피드포워드 신경망에 드롭아웃을 적용하여 일반화 성능을 크게 향상시키는 기존 연구들을 바탕으로, 학습 단계에서 모델 자체를 압축하는 새로운 방법인 “드롭아웃 컴팩션”을 제안한다. 전통적인 드롭아웃은 각 레이어에 동일한 유지 확률 p를 적용하고, 테스트 시에는 전체 네트워크를 그대로 사용하면서 출력값을 p로 스케일링한다. 이러한 방식은 큰 모델을 과적합으로부터 보호하지만, 실제 서비스 환경에서는 연산량과 메모리 사용량을 줄이기 위해 모델 크기를 제한해야 한다는 제약이 있다. 기존의 모델 압축 기법은 가중치 행렬에 L1 정규화, 2차 미분 기반 프루닝, SVD 기반 저차원 근사, 혹은 지식 증류와 같은 방법을 사용한다. 그러나 가중치 수준의 희소화는 실제 하드웨어에서 dense 연산에 비해 큰 이점을 제공하지 못하고, SVD나 지식 증류는 추가적인 파라미터 또는 별도의 학습 단계가 필요하다.
드롭아웃 컴팩션은 이러한 한계를 극복하기 위해, 각 은닉 유닛 i에 대해 개별 유지 확률 π_i를 도입하고, 이들에 대해 0과 1에 집중되는 양측 베타 사전(p(π_i) ∝ π_i^{α‑1}(1‑π_i)^{β‑1})^γ을 적용한다. α와 β를 1보다 작게 설정하면 사전 확률이 0과 1 근처에서 무한히 커져, 최적화 과정에서 π_i가 두 극단값 중 하나로 수렴하도록 강제한다. γ는 사전의 강도를 조절하는 파라미터로, 큰 값일수록 π_i가 0 혹은 1에 더 빠르게 수렴한다.
학습 목표는 로그우도와 사전 로그확률의 합인 공동 로그우도 L(Θ;Π) + log p(Π)이다. Θ에 대한 업데이트는 기존 드롭아웃과 동일하게 확률적 경사 하강법(SGD)으로 수행한다. π에 대한 그래디언트는 마스크 M에 대한 기대값 형태로 도출되며, 직접 계산이 불가능하므로 두 번의 전방패스(하나는 실제 마스크를 샘플링하고, 다른 하나는 기대 마스크를 사용)로 근사한다. 구체적으로, w_t(M) = p(k_t|x_t,M,Θ) / ˜p(k_t|x_t,Π,Θ) 로 정의하고, 이 값을 이용해 ∂L/∂π_i = E_M
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기