비공개 변분 추론을 위한 차등 프라이버시 방법
본 논문은 차등 프라이버시(DP)를 적용한 변분 추론(DPVI) 알고리즘을 제안한다. 기존의 DP 기반 베이지안 방법이 제한적인 모델에만 적용되던 문제를 해결하고자, 이중 확률적 변분 추론(doubly stochastic variational inference, DSVI) 위에 그래디언트 클리핑·노이즈 추가 방식을 결합한다. 미니배치 샘플링을 이용한 프라이버시 증폭과 Moments Accountant를 통한 정확한 프라이버시 비용 계산을 활용해…
저자: Joonas J"alk"o, Onur Dikmen, Antti Honkela
본 논문은 개인 데이터의 프라이버시를 보장하면서도 베이지안 추론을 효율적으로 수행할 수 있는 새로운 방법, 차등 프라이버시 변분 추론(DPVI)을 제안한다. 기존의 차등 프라이버시 기반 베이지안 방법은 크게 두 가지 한계에 직면해 있었다. 첫 번째는 대부분이 지수형족(exp exponential family) 모델에만 적용 가능하다는 점이며, 두 번째는 샘플링 기반 MCMC 방법이 프라이버시 예산을 빠르게 소모해 반복 횟수가 제한된다는 점이다. 이러한 문제를 해결하기 위해 저자들은 최근 각광받고 있는 이중 확률적 변분 추론(doubly stochastic variational inference, DSVI) 위에 그래디언트 클리핑과 가우시안 노이즈 추가 메커니즘을 결합하였다.
논문 초반부에서는 차등 프라이버시의 기본 정의와 순수 DP(ε‑DP)와 (ε, δ)‑DP의 차이를 정리하고, Gaussian 메커니즘을 이용한 노이즈 스케일링 공식(σ² > 2 ln(1.25/δ) Δ₂²/ε²)을 제시한다. 이어서 DP의 핵심 장점인 합성(theorem)과 프라이버시 증폭(privacy amplification) 이론을 소개한다. 특히, 무작위 서브샘플링을 통해 ε를 로그 형태로 감소시킬 수 있음을 보이며, 이는 미니배치 기반 최적화와 자연스럽게 연결된다.
다음으로 변분 베이지안(VB)의 기본 원리와 ELBO(증거 하한) 최적화 과정을 설명한다. 전통적인 VB는 모델이 공액(conjugate)일 때는 닫힌 형태의 업데이트가 가능하지만, 비공액 모델에서는 Monte Carlo 적분과 재파라미터화(trick)를 이용해 스토캐스틱 그래디언트를 계산한다. DSVI는 이러한 스토캐스틱 그래디언트를 미니배치와 샘플링을 동시에 활용해 효율적으로 최적화한다.
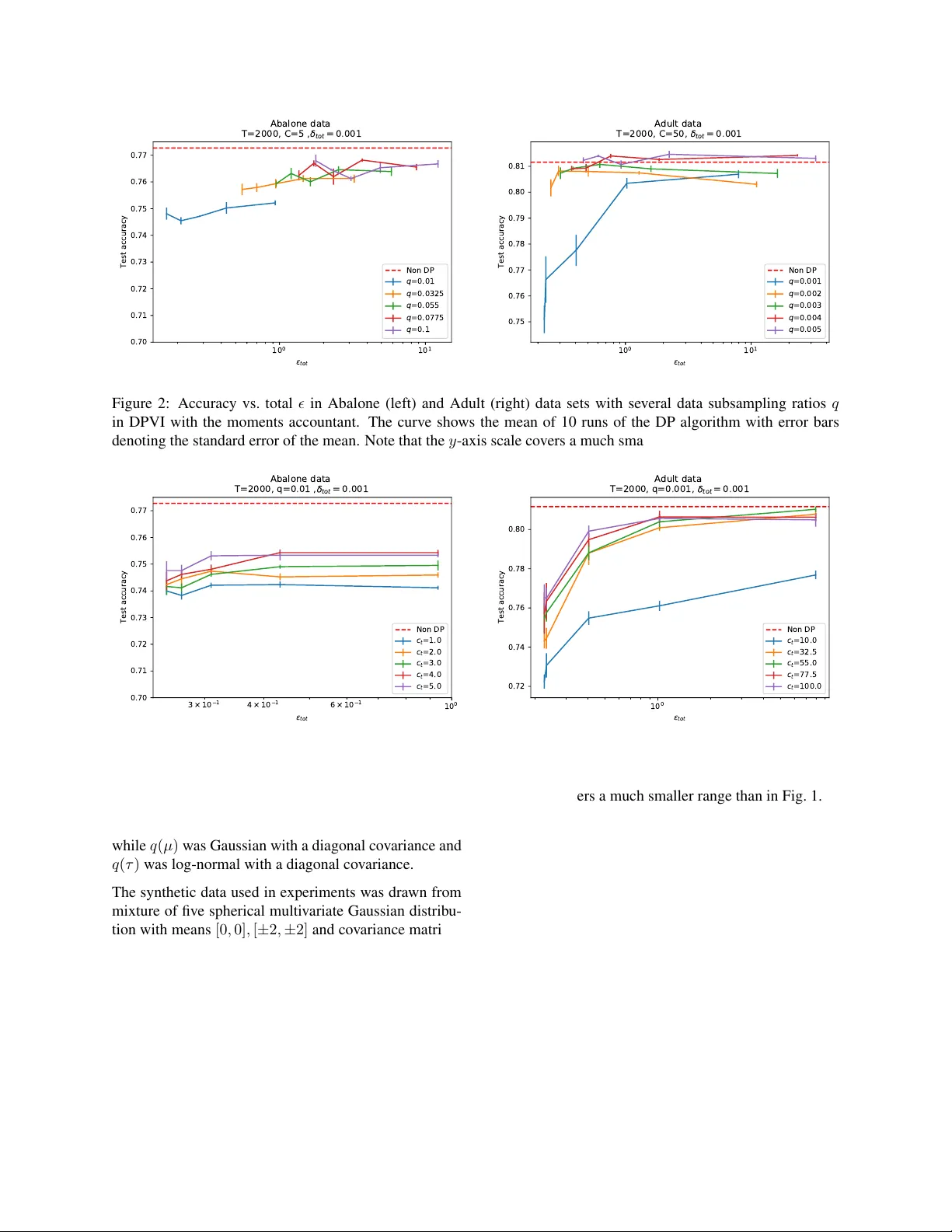
DPVI 알고리즘(Algorithm 1)은 다음과 같은 흐름을 가진다. 1) 전체 데이터셋 D에서 샘플링 비율 q에 따라 미니배치 U를 무작위로 선택한다. 2) 각 데이터 i∈U에 대해 ELBO의 개별 항 Lᵢ(ξ) 의 그래디언트 gₜ(xᵢ)=∇ₓLᵢ(ξₜ)를 계산한다. 3) 그래디언트의 ℓ₂‑노름을 사전에 정한 클리핑 임계값 cₜ와 비교해, ‖gₜ(xᵢ)‖₂>cₜ이면 비율 cₜ/‖gₜ(xᵢ)‖₂만큼 스케일링한다. 4) 클리핑된 그래디언트를 모두 합산하고, 평균에 가우시안 노이즈 N(0, 4cₜ²σ²I)를 추가한다. 5) AdaGrad 방식으로 학습률을 조정하고, 파라미터 ξₜ를 업데이트한다. 이 과정은 T번 반복된다.
잠재 변수를 포함하는 모델에 대해서는 두 가지 전략을 제시한다. 첫 번째는 EM‑알고리즘 관점에서 잠재 변수를 완전 데이터의 일부로 보고, 전체 데이터 요약에만 DP 보호를 적용한다. 이 경우 잠재 변수 자체는 노이즈가 추가되지 않으며, 최종 추정값도 공개되지 않는다. 두 번째는 가능한 경우 잠재 변수를 직접 마진화하여, 변분 추론이 관측 데이터만을 사용하도록 만든다. 이는 기존 VIPS와 달리 비공액 모델에도 적용 가능하게 만든다.
하이퍼파라미터 선택에 관한 논의는 실용적인 가이드를 제공한다. 클리핑 임계값 cₜ는 그래디언트 민감도와 직접 연결되며, 너무 작게 설정하면 신호가 과도하게 억제돼 수렴이 느려지고, 너무 크게 설정하면 노이즈 규모가 커져 프라이버시 비용이 급증한다. 샘플링 비율 q는 프라이버시 증폭 효과와 학습 효율 사이의 트레이드오프를 결정한다; q가 작을수록 각 반복당 사용되는 데이터가 적어 프라이버시가 강화되지만, 전체 반복 횟수 T를 늘려야 한다. 논문은 실험을 통해 q=0.01~0.05, cₜ≈1.0, σ≈1.0 정도가 실용적인 설정임을 보인다.
실험에서는 베이지안 로지스틱 회귀와 가우시안 혼합 모델을 대상으로 DPVI와 기존 방법(예: 차등 프라이버시 MCMC, 차등 프라이버시 충분통계 perturbation) 을 비교하였다. ε=1, δ=10⁻⁵ 수준의 강한 프라이버시에서도 DPVI는 비공개 기준에 근접한 정확도(예: 로지스틱 회귀에서 AUC 차이 <0.02)를 달성했으며, 특히 샘플링 기반 MCMC는 동일 ε에서 수렴이 불안정하거나 정확도가 크게 떨어지는 반면, DPVI는 안정적인 수렴과 높은 효율성을 보였다. 가우시안 혼합 모델 실험에서도 DPVI는 클러스터 할당 정확도가 비공개가 아닌 경우와 거의 차이가 없었으며, 모델 복잡도가 증가해도 프라이버시 비용이 크게 증가하지 않는 점을 확인했다.
마지막으로 논문은 DPVI의 장점과 한계를 정리한다. 장점으로는 (1) 비공액 모델에 대한 일반화 가능성, (2) 자동 미분 프레임워크와의 손쉬운 통합, (3) Moments Accountant를 통한 정확한 프라이버시 비용 계산, (4) 미니배치 기반 학습으로 대규모 데이터셋에 적용 가능함을 들었다. 한계로는 (1) 클리핑 임계값과 노이즈 스케일 선택이 경험적이며, (2) 잠재 변수가 많은 복잡한 모델에서는 EM‑스타일 접근이 필요해 구현 복잡도가 증가한다는 점을 언급한다. 향후 연구 방향으로는 적응형 클리핑, 프라이버시‑예산을 동적으로 할당하는 스케줄링, 그리고 딥러닝 모델에 대한 확장 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기