음악을 처음부터 배우다: MusicNet 데이터와 자동 음표 예측
MusicNet은 34시간 분량의 클래식 연주와 130만 개 이상의 시간 라벨을 포함한 대규모 공개 데이터셋이다. 논문은 이 데이터를 활용해 멀티라벨 음표 예측 과제를 정의하고, 스펙트로그램 기반 모델, 엔드‑투‑엔드 신경망, 그리고 컨볼루션 신경망을 비교한다. 실험 결과, 엔드‑투‑엔드 모델은 학습 과정에서 주파수 선택 필터를 자동으로 학습해 스펙트로그램과 유사한 저수준 표현을 얻으며, 약간의 성능 향상을 보인다.
저자: John Thickstun, Zaid Harchaoui, Sham Kakade
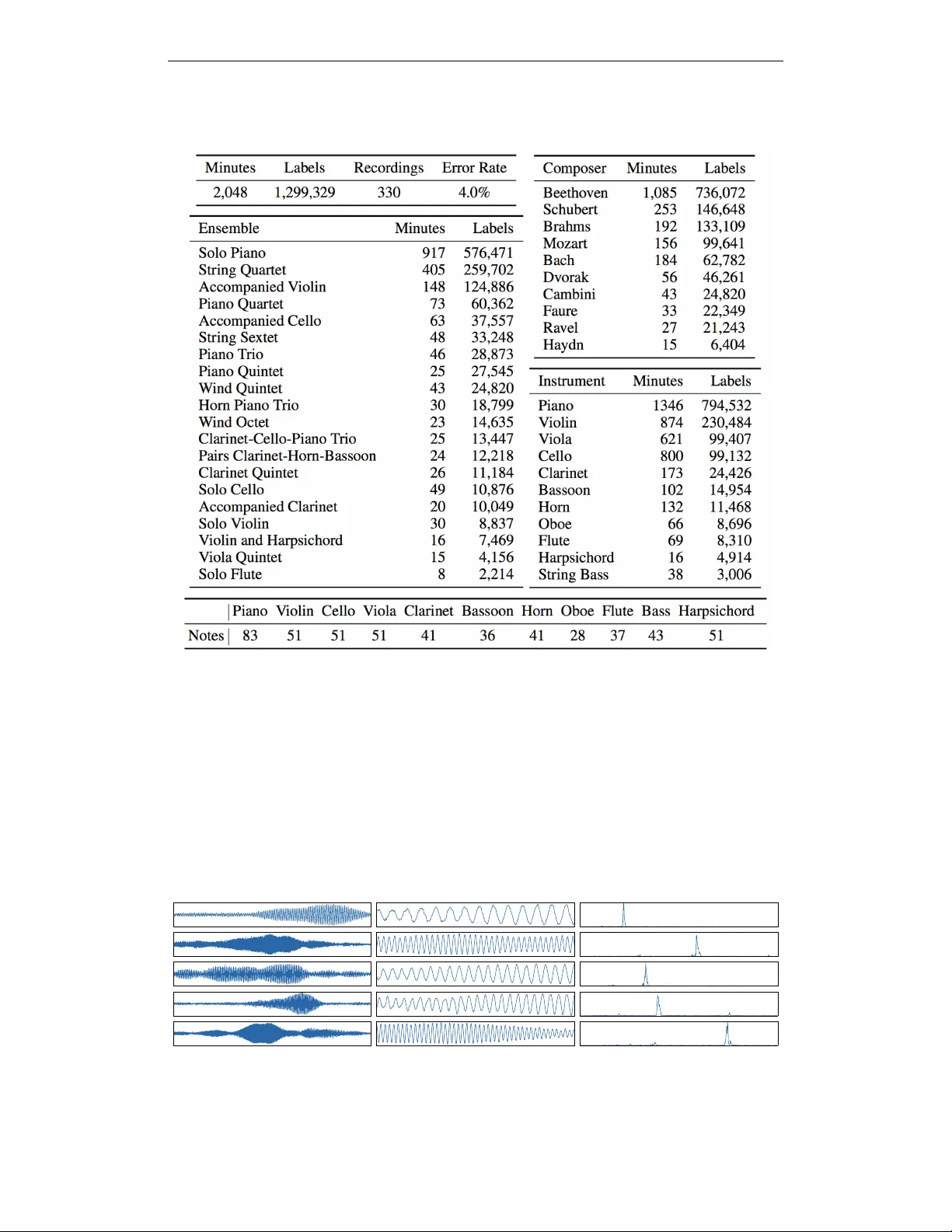
이 논문은 음악 정보 검색(MIR) 분야에서 라벨링된 대규모 데이터의 부재가 연구를 제한해 온 문제를 해결하고자, 34시간 분량의 클래식 연주와 1,299,329개의 시간 라벨을 포함한 MusicNet 데이터셋을 공개한다. 데이터는 10명의 작곡가, 11개의 악기, 330개의 자유 라이선스 녹음으로 구성되며, 각 녹음은 디지털 MIDI 스코어와 정밀하게 정렬되어 있다. 정렬 과정은 동적 시간 왜곡(DTW)을 기반으로 하며, 스코어를 합성된 오디오와 비교할 때 저주파 50개 bin만을 사용해 높은 정렬 정확도를 확보한다.
논문은 이 데이터를 활용해 “멀티라벨 음표 예측”이라는 과제를 정의한다. 입력은 일정 길이(≈1/3초)의 오디오 세그먼트이며, 출력은 128차원의 이진 라벨 벡터로, 각 차원은 MIDI 음높이에 대응한다. 라벨은 세그먼트 중앙에 해당 음이 존재하면 1, 없으면 0으로 지정한다.
세 가지 모델을 비교한다. 첫 번째는 전통적인 로그‑스펙트로그램을 특징으로 사용하고, 선형 회귀(ℓ2 손실)로 라벨을 예측한다. 두 번째는 원시 파형을 그대로 입력으로 하는 2‑layer ReLU 네트워크이며, 여기서 각 필터는 wᵀx 형태의 선형 변환 후 로그 비선형을 적용한다. 세 번째는 위 구조에 컨볼루션 레이어를 추가한 CNN이다. 모든 모델은 다변량 선형 회귀를 통해 ŷ를 추정하고, 최적 임계값 c를 F1‑score 기준으로 선택한다.
실험 결과, 엔드‑투‑엔드 모델(특히 2‑layer ReLU)은 학습 과정에서 주파수 선택 필터를 자동으로 학습한다. 시각화된 필터는 사인·코사인 변조 파형, 즉 Gabor‑like 형태를 띠며, 이는 스펙트로그램이 저수준에서 수행하는 주파수 에너지 추정과 동일한 역할을 한다는 것을 보여준다. 로그‑스펙트로그램과 비교했을 때, 엔드‑투‑엔드 모델은 약간 높은 F1‑score를 기록했지만 차이는 크지 않다. 이는 충분한 데이터가 주어지면 신경망이 스펙트로그램과 유사한 정보를 스스로 학습한다는 점을 시사한다.
또한, 데이터 자체의 편향도 논의된다. 베토벤 작품과 피아노 연주가 과다 대표되어 있어 악기별 라벨 불균형이 존재한다. 저자는 상업용 녹음과 추가 정렬 프로토콜을 활용해 데이터셋을 확장하고, 플루트·오보에와 같은 부족한 악기를 보완할 수 있음을 제안한다.
마지막으로, 논문은 MusicNet이 MIR 연구에 필요한 대규모 라벨링 인프라를 제공함을 강조한다. 향후 연구 방향으로는 (1) 더 다양한 장르와 악기를 포함한 데이터 확장, (2) 악보와 오디오를 동시에 활용하는 멀티모달 정렬 및 학습, (3) 음표 외에도 다이내믹스·아티큘레이션·표현 기법 등 풍부한 음악 정보를 학습하는 모델 개발을 제시한다. 이러한 발전은 자동 악보 생성, 음악 검색, 그리고 창작 지원 시스템 등 실용적인 응용 분야에 큰 영향을 미칠 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기