자동 구조예측으로 측정하는 모음 지속시간: 기계학습 기반 새로운 방법
본 논문은 강제 정렬기와 달리 문자 전사 없이도 단일 모음의 시작·끝 시점을 예측하는 구조화 예측 모델을 제안한다. 수동 주석 데이터를 이용해 학습한 후, 직접 손실 최소화(DLM) 알고리즘으로 파라미터를 최적화하고 16개의 음향 특징과 음소 분류기 정보를 활용한다. 세 개의 실험 데이터셋에서 인간 주석과의 평균 오차가 강제 정렬기보다 낮으며, 통계 모델 재현에서도 우수한 성능을 보인다.
저자: Yossi Adi, Joseph Keshet, Emily Cibelli
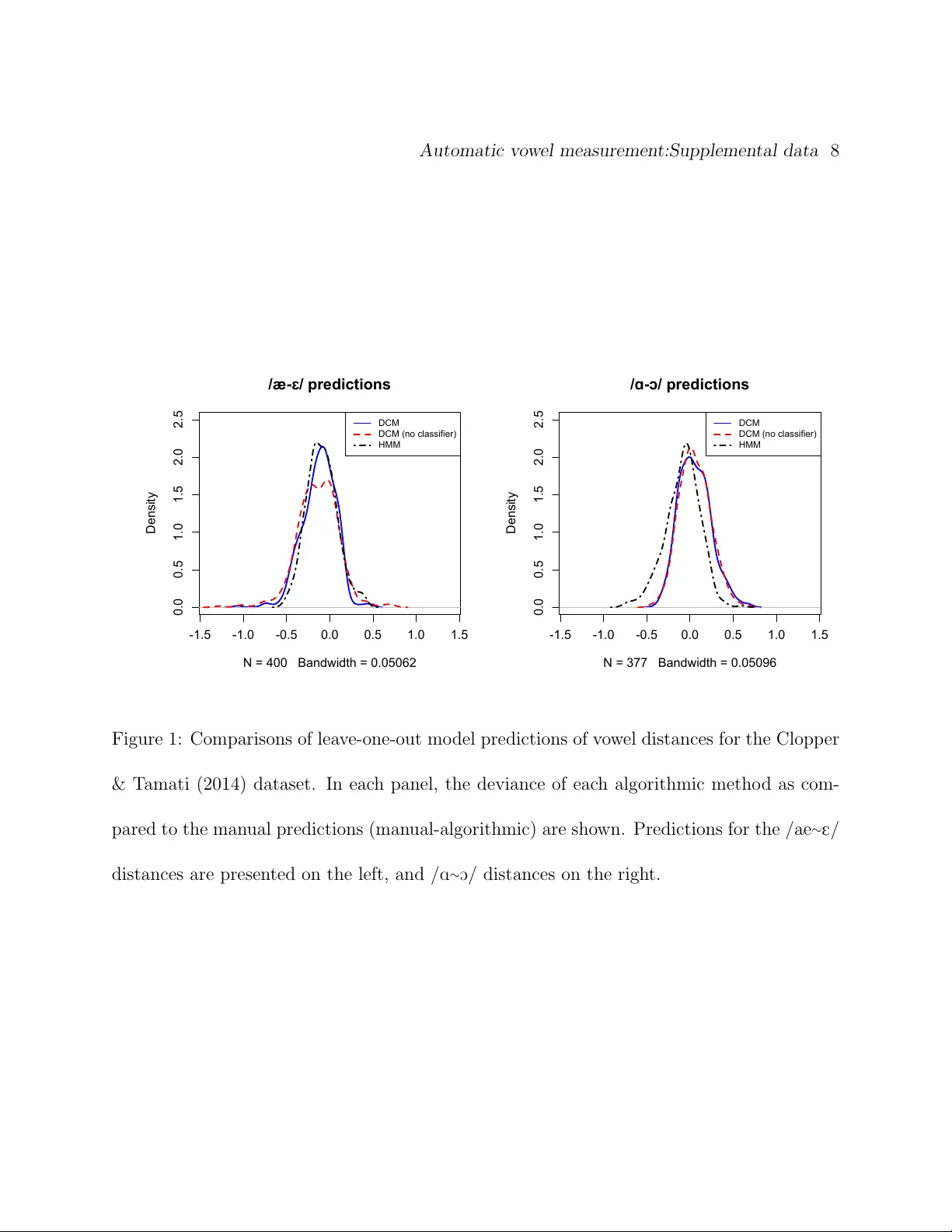
본 논문은 음성학 연구에서 필수적인 ‘모음 지속시간’ 측정을 자동화하기 위해 구조화 예측(structured prediction) 기반의 새로운 알고리즘을 제안한다. 전통적으로는 인간이 직접 스펙트로그램을 확인하거나, 강제 정렬기(HMM 기반)와 같은 도구를 사용해 문자 전사와 함께 경계를 찾았다. 그러나 이러한 방법은 (1) 주관적인 판단에 의존해 재현성이 낮고, (2) 전사 과정이 필요해 대규모 데이터에 적용하기 어렵다는 한계가 있다.
이를 해결하고자 저자들은 ‘임의 길이의 C‑V‑C 구간(전·후에 자음이 있는 단일 모음)’을 입력으로 받아, 모음의 시작 프레임 t_b와 끝 프레임 t_e를 직접 예측하는 함수 f 를 학습한다. 입력 신호는 프레임 단위로 16개의 음향 특징을 추출한다. 이 특징들은 (a) 단순 에너지·스펙트럼 지표(E_short, E_total, E_low, E_high, H_wiener), (b) F0와 voicing 검출기(RAPT), (c) zero‑crossing, (d) 사전 학습된 음소 분류기의 확률·예측값(모음·비음 확률, 전체 음소에 대한 Gibbs 확률), (e) 인접 프레임 간 MFCC 거리 D_j (1≤j≤4) 등으로 구성된다. 이러한 풍부한 특징은 인간 주석자가 스펙트로그램을 보며 경계를 판단할 때 활용하는 정보와 유사하게 설계되었다.
모델 자체는 선형 디코더 w·φ(x, t̂) 를 사용한다. 여기서 φ는 입력 신호 x와 가설 경계 t̂ (= (t̂_b, t̂_e))를 매핑해 실수 벡터로 변환하는 ‘특징 함수’이며, w는 학습 가능한 가중치 벡터다. 예측은 f_w(x)=argmax_{t̂∈T²} w·φ(x, t̂) 로 정의된다.
학습 목표는 실제 주석 t와 예측 f_w(x) 사이의 손실 γ(t, t̂) 의 기대값을 최소화하는 것이다. 손실 함수는
γ(t, t̂)=max(0,|t̂_b−t_b|−τ_b)+max(0,|t̂_e−t_e|−τ_e)
형태로, 초반 τ_b, τ_e 프레임 이내의 오차는 허용하고 그 이상일 경우에만 벌점을 부여한다. 이는 인간 주석의 불확실성을 반영한다.
직접 손실 최소화(Direct Loss Minimization, DLM) 알고리즘을 적용해 파라미터 w 를 최적화한다. DLM은 출력이 이산적이더라도 입력이 연속적인 경우 손실에 대한 기대값의 그래디언트를 닫힌 형태로 계산할 수 있음을 이용한다. 구체적으로는 w_{t+1}=w_t+η_t·(φ(x, f_w(x))−φ(x, f_w^ε(x))) 로 업데이트한다. 여기서 f_w^ε(x)=argmax_{t̂}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기