대규모 적대적 학습의 비밀
본 논문은 ImageNet 수준의 대형 신경망에 적대적 훈련을 적용하여, 단일 단계 공격에 대한 강인성을 크게 향상시키고, 다중 단계 공격의 전이성을 낮추는 방법을 제시한다. 또한 라벨 누수 현상을 규명하고 이를 완화하는 전략을 제공한다.
저자: Alexey Kurakin, Ian Goodfellow, Samy Bengio
본 논문은 적대적 예제(adversarial examples)가 머신러닝 모델, 특히 딥러닝 기반 이미지 분류기에 미치는 위협을 다루며, 기존 연구가 주로 소규모 데이터셋(MNIST, CIFAR‑10)에서 적대적 훈련(adversarial training)을 검증한 것에 반해, 저자들은 이를 ImageNet 규모와 Inception‑v3 아키텍처에 적용하는 방법을 제시한다. 연구 목표는 네 가지로 요약된다: (1) 대규모 모델과 데이터에 적대적 훈련을 성공적으로 확장하기 위한 실천적 권고, (2) 단일 단계 공격에 대한 강인성 향상 확인, (3) 다중 단계 공격이 단일 단계 공격보다 전이성이 낮아 블랙박스 공격에 덜 유리함을 입증, (4) 라벨 누수(label leaking) 현상의 원인 규명 및 완화.
논문 초반부에서는 적대적 예제의 정의와 전이성(transferability)을 설명하고, 기존 방어 기법(적대적 훈련, 방어적 디스틸레이션 등)이 소규모 데이터에만 검증된 한계를 지적한다. 이어서 적대적 예제 생성 방법을 체계적으로 정리한다. 단일 단계 방법으로는 Fast Gradient Sign Method(FGSM)와 true label을 이용한 step‑ll(least‑likely) 및 step‑rnd(random) 변형이 소개된다. 다중 단계 방법으로는 기본 iterative(FGSM 반복)와 iterative‑ll(least‑likely 타깃) 두 가지가 제시된다.
핵심 기여는 적대적 훈련 알고리즘의 스케일링이다. 저자들은 배치 정규화(batch normalization)를 도입하고, 각 미니배치에 정상 이미지와 적대적 이미지를 혼합해 학습한다. 손실 함수는 L_clean과 L_adv를 각각 λ와 (1‑λ) 비율로 가중합해, λ=0.3, 배치 크기 m=32, 적대적 샘플 수 k=16을 사용한다. 또한 ε(perturbation magnitude)를 고정하지 않고 각 샘플마다 0~16 범위의 절단 정규분포(N(0,8))에서 무작위 추출한다. 이러한 설계는 특정 ε에 대한 과적합을 방지하고, 다양한 강도의 공격에 대한 일반화된 방어를 가능하게 한다.
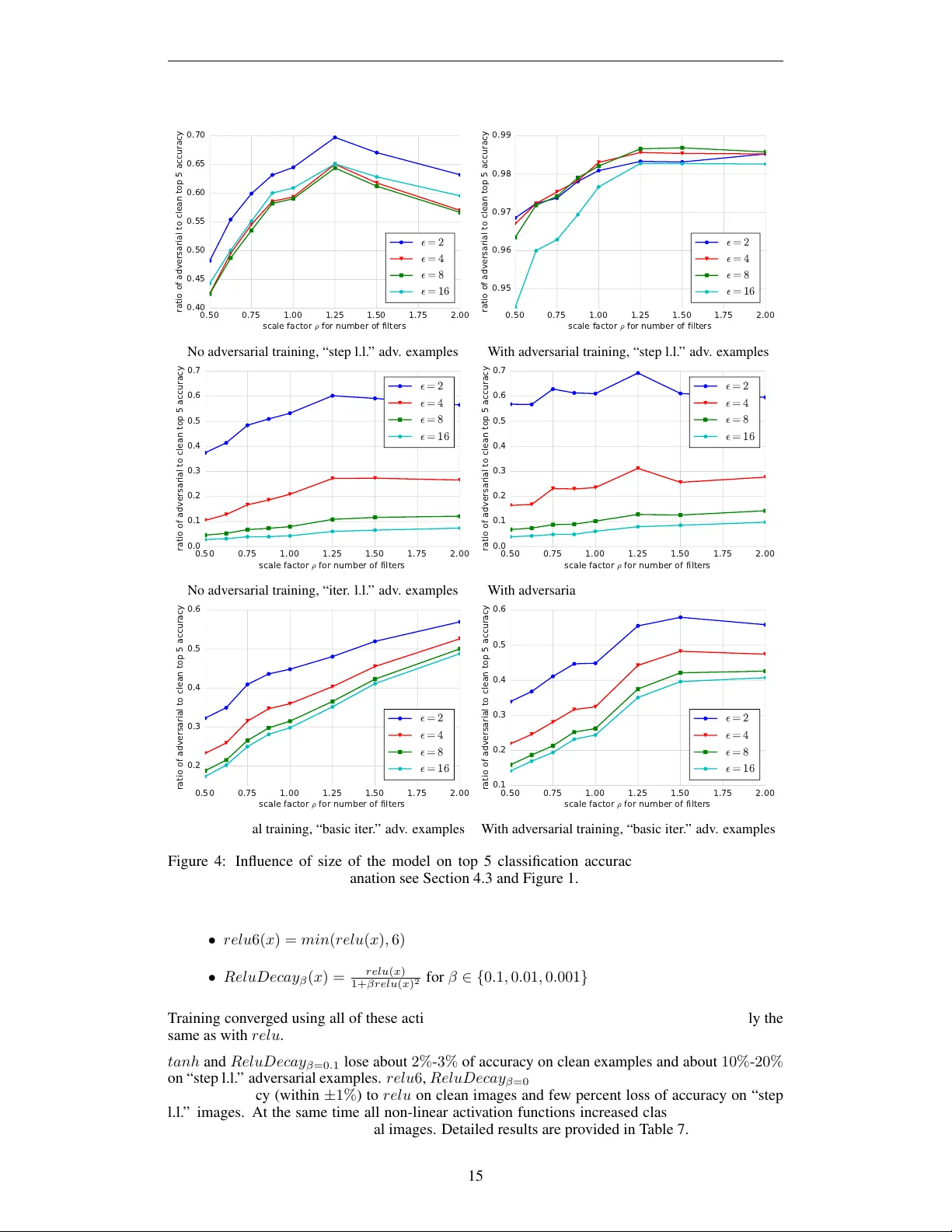
실험은 50대의 머신을 이용한 동기식 분산 학습으로 진행되었으며, RMSProp 옵티마이저와 초기 학습률 0.045를 사용한다. 적대적 훈련 전후의 모델 성능을 clean 이미지와 다양한 ε값(2,4,8,16)에서의 FGSM 기반 적대적 이미지에 대해 평가한다. 표 1에 따르면, 표준 훈련 모델은 ε=2일 때 top‑1 정확도가 30.8%에 불과했으나, 적대적 훈련을 적용한 모델은 73.5%까지 회복한다. 다만 clean 이미지에 대한 정확도는 0.8% 감소한다. 모델 용량을 늘려 Inception 블록을 두 개 추가한 깊은 모델은 동일한 훈련에서도 clean 정확도 감소가 0.2% 이하로 억제되고, 적대적 정확도는 약 2% 추가 향상된다.
다중 단계 공격에 대한 내성은 별도로 평가되었다. 표 2는 적대적 훈련이 단일 단계 공격에만 효과적이며, iterative‑ll이나 iterative‑basic 공격에 대해서는 거의 방어 효과가 없음을 보여준다. 이는 단일 단계 공격이 모델의 선형 근사에 크게 의존하고, 적대적 훈련이 그 선형 근사를 보정하는 데 초점을 맞추기 때문으로 해석된다.
라벨 누수 현상은 중요한 부수 결과이다. 적대적 샘플을 생성할 때 true label을 사용하면, 모델이 해당 라벨 정보를 이용해 “공격 생성 규칙”을 학습하게 된다. 결과적으로 적대적 이미지가 clean 이미지보다 높은 정확도로 분류되는 역설적인 현상이 발생한다. 이를 방지하기 위해 저자들은 라벨을 사용하지 않는 무작위 타깃 클래스(step‑rnd)나 라벨 스무딩을 비활성화하는 방식을 제안한다.
훈련 시점 지연 실험에서는 적대적 훈련을 0, 10k, 20k, 40k 스텝 이후에 시작했을 때, 10k 지연은 clean 정확도와 적대적 정확도에 큰 영향을 주지 않아 실용적인 선택으로 제시된다. 그러나 20k 이상 지연하면 높은 ε(≥8)에서 적대적 정확도가 최대 4%까지 감소한다.
결론적으로, 이 논문은 대규모 이미지 분류기에 적대적 훈련을 적용하기 위한 구체적인 프로토콜을 제공하고, 단일 단계 공격이 가장 위험한 블랙박스 시나리오임을 실증한다. 또한 라벨 누수 문제를 명확히 규명하고, 이를 완화하는 실용적인 방법을 제시함으로써 향후 방어 메커니즘 설계에 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기