안전한 탐색을 위한 가우시안 프로세스 기반 MDP 탐험 알고리즘
본 논문은 안전 제약이 사전에 알려지지 않은 유한 마코프 결정 과정(MDP)에서, 가우시안 프로세스(GP)로 모델링한 안전 함수의 규칙성을 활용해 안전하게 전체 탐색 가능한 영역을 식별하는 SAFE‑MDP 알고리즘을 제안한다. 알고리즘은 안전, 도달 가능성, 복귀 가능성을 동시에 만족하는 상태‑행동 쌍만을 선택적으로 방문하며, 고확률 안전 보장과 완전 탐색을 이론적으로 증명한다. 디지털 지형 모델을 이용한 로버 실험을 통해 실제 적용 가능성을 …
저자: Matteo Turchetta, Felix Berkenkamp, Andreas Krause
**1. 서론 및 동기**
로봇이 실세계에서 자율적으로 학습·탐색하려면 사전에 모든 상황을 모델링할 수 없으며, 탐색 과정에서 발생할 수 있는 위험을 최소화해야 한다. 기존 강화학습은 단기 손실을 감수하고 장기 보상을 추구하지만, 안전이 하드 제약인 로봇 시스템에서는 허용되지 않는다. 따라서 안전 제약이 미리 알려지지 않은 상황에서도 안전하게 탐색할 수 있는 방법이 필요하다.
**2. 관련 연구**
위험 민감 강화학습, 백업 정책 기반 안전 보장, 에르고딕 정책 최적화 등 다양한 접근이 존재한다. 그러나 대부분은 위험을 확률적으로 최소화하거나, 사전에 정의된 위험 상태·백업 정책을 필요로 한다. 베이지안 최적화 분야에서는 안전 제약을 만족하면서 전역 최적점을 찾는 방법이 제안됐지만, 이는 밴드잇(단일 행동) 설정에 국한된다. 본 논문은 이러한 한계를 넘어 MDP의 전이 구조와 반환 가능성을 동시에 고려한다.
**3. 문제 정의 및 가정**
- 환경은 유한 상태 집합 S와 결정적 전이 함수 f(s,a)를 갖는 MDP이다.
- 안전 함수 r(s,a)는 미지이며, 임계값 h보다 크면 안전하다고 정의한다.
- r은 GP 사전 r(s)∼GP(0,k) 로 모델링되며, RKHS 노름이 유계이고 L‑리프시츠 연속성을 가진다.
- 초기 안전 시드 S₀가 주어지며, S₀ 내부는 상호 도달·복귀가 가능하도록 구성된다.
**4. 안전, 도달, 복귀 연산자**
- **R_safe^ε(S)**: 현재 안전 집합 S와 GP 신뢰 구간을 이용해 ε 정확도 내에서 안전하다고 판단되는 상태를 확장한다.
- **R_reach(S)**: 현재 안전 집합에서 한 단계 전이로 도달 가능한 상태를 정의한다.
- **R_ret(S,Ŝ)**: 현재 후보 집합 Ŝ에서 다시 안전 집합 S 로 복귀할 수 있는 상태를 정의한다. n‑step 복귀 연산자를 반복 적용해 장기 복귀 가능성을 확보한다.
- 최종 허용 탐색 집합은 세 연산자의 교집합 **R^ε(S)=R_safe^ε(S)∩R_reach(S)∩R_ret(R_safe^ε(S),S)** 로 정의된다.
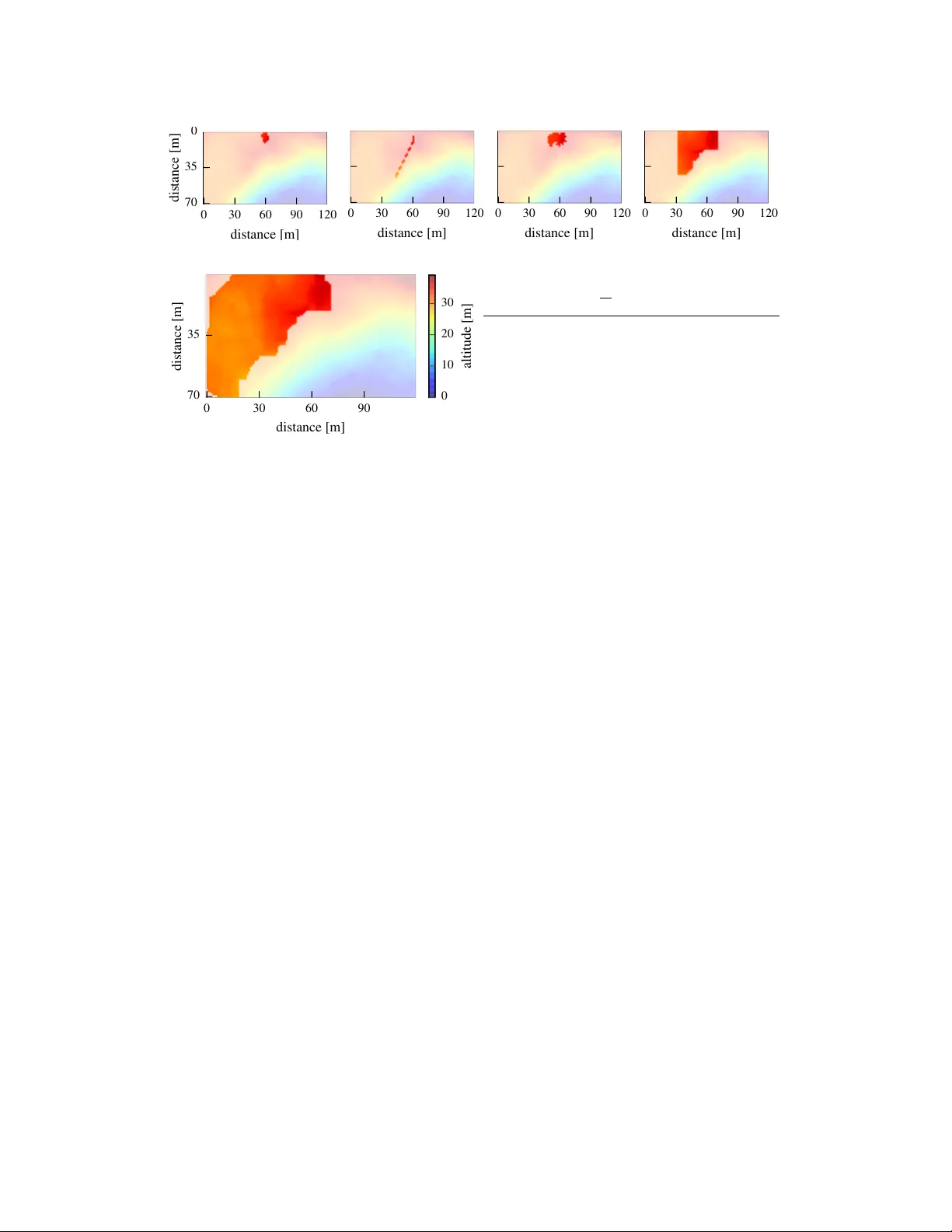
**5. SAFE‑MDP 알고리즘**
1. 초기화: C₀(s)=
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기