DNA 시퀀스의 가변 길이 kmer를 위한 일관된 벡터 표현
본 논문은 DNA 서열을 3~8 염기로 구성된 가변 길이 kmer에 대해 word2vec의 skip‑gram 방식을 차용한 dna2vec 모델을 학습한다. 100차원 연속 벡터 공간에 모든 kmer를 매핑함으로써, one‑hot 인코딩의 차원 폭발과 거리 균일성 문제를 해결한다. 실험에서는 벡터 합이 서열 연결과 유사함을 보였으며, 코사인 유사도와 Needleman‑Wunsch 정렬 점수 사이에 높은 상관관계가 있음을 확인한다. 또한, kmer…
저자: Patrick Ng
본 논문은 DNA 서열 분석에서 널리 사용되는 kmer 분할 방식의 한계를 극복하기 위해, 가변 길이 kmer를 연속적인 저차원 벡터 공간에 매핑하는 새로운 임베딩 기법 dna2vec을 제안한다. 기존의 one‑hot 인코딩은 k가 커질수록 차원이 기하급수적으로 증가하고, 모든 벡터 간 거리가 동일해 서열 간 유사성을 구분하기 어렵다는 문제점이 있었다. 이러한 문제를 해결하고자 저자는 자연어 처리 분야에서 성공적으로 활용된 word2vec의 skip‑gram 모델을 DNA 서열에 적용하였다.
학습 파이프라인은 네 단계로 구성된다. 첫째, 인간 게놈(hg38)에서 X·Y·미토콘드리아 등 특수 염색체를 제외하고, 연속적인 DNA 조각을 추출한다. 둘째, 각 조각을 3~8 염기 길이의 kmer로 겹치게 슬라이딩하면서, k값을 균등 분포에서 무작위로 선택한다. 이를 통해 가변 길이 kmer들의 시퀀스가 생성된다. 셋째, 생성된 kmer 시퀀스를 word2vec의 skip‑gram 방식으로 학습한다. 컨텍스트 윈도우는 앞뒤 10개의 kmer를 사용하며, 부정 샘플링(negative sampling)으로 파라미터를 최적화한다. 마지막으로, 학습된 전체 임베딩 모델을 k 길이별로 분리해 각각의 kmer 전용 서브 모델을 만든다.
임베딩 차원은 100으로 고정했으며, gensim 라이브러리를 이용해 10 epoch 동안 학습하였다. 학습 시간은 4코어 CPU와 8 GB 메모리 환경에서 약 3일에 달했으며, 학습된 벡터는 공개 저장소에 제공한다.
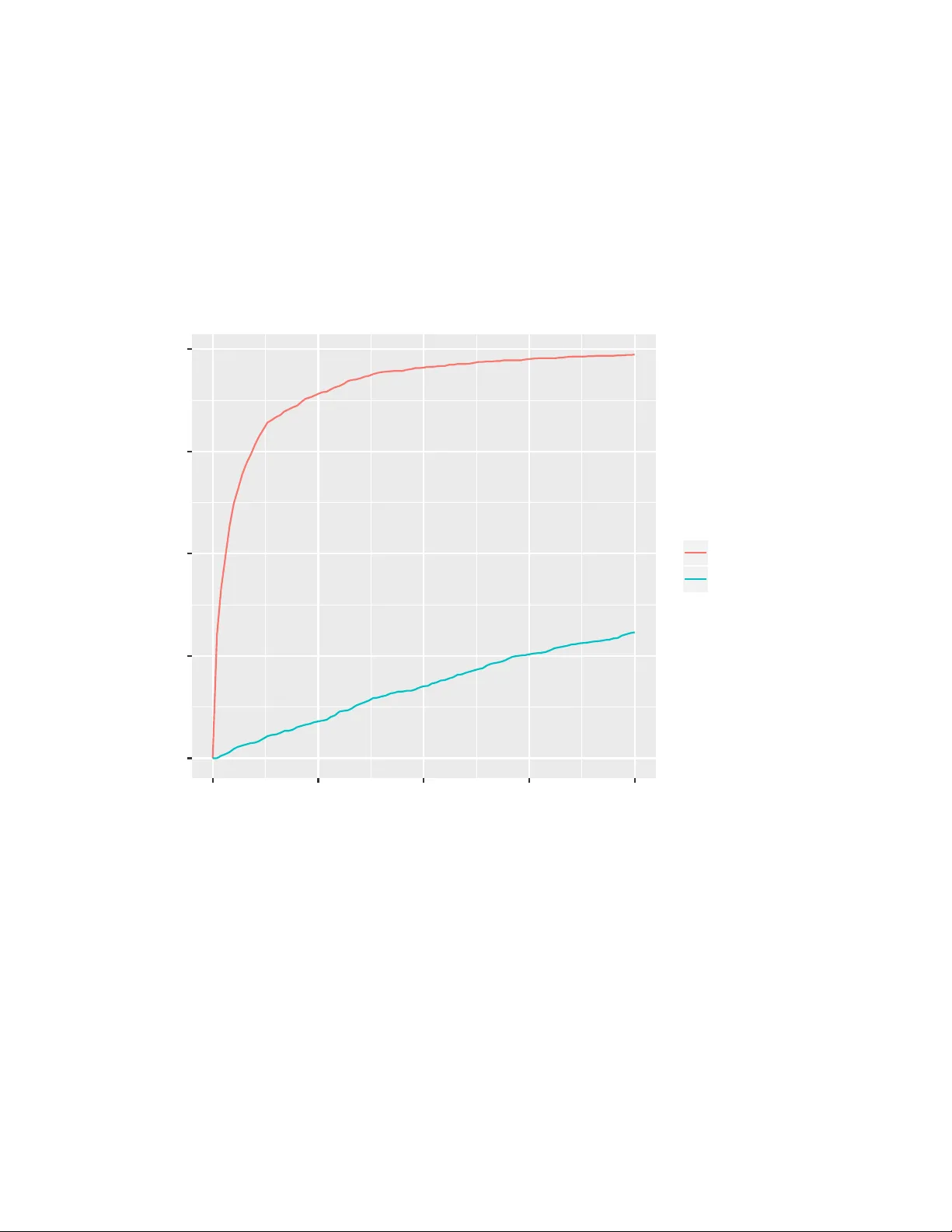
실험에서는 세 가지 주요 평가를 수행했다. 첫째, 벡터 연산이 서열 연결과 얼마나 일치하는지를 확인하기 위해 두 kmer의 벡터를 합산하고, 그 결과 벡터의 최근접 이웃이 원래 두 kmer를 연결한 서열(예: AAC + TCT → AACTCT 또는 TCTAAC)과 겹치는 비율을 측정했다. 1‑NN에서는 28 %~73 %의 일치율을 보였으며, 10‑NN에서는 94 %~99 %에 이르는 높은 성공률을 기록했다. 이는 벡터 합이 실제 서열 연결을 근사한다는 강력한 증거다.
둘째, 코사인 유사도와 전통적인 Needleman‑Wunsch 전역 정렬 점수 사이의 상관관계를 조사했다. 8‑mer 1 000쌍을 샘플링해 두 지표를 비교한 결과, 스피어만 상관계수 0.831을 얻었으며, 가장 유사한 kmer 쌍은 dna2vec에서도 높은 코사인 유사도를 보였다. 이는 dna2vec이 서열 정렬 거리와도 일관된 거리 구조를 형성함을 의미한다.
셋째, ‘강한 연결’(같은 끝에 스니펫 삽입)과 ‘약한 연결’(양쪽 끝 중 하나에 삽입)이라는 두 유형의 유추 실험을 수행했다. 예를 들어, vec(ACGAT) − vec(GAT) + vec(ATC) ≈ vec(ACATC)와 같은 연산이 실제 서열 연결을 재현한다는 것을 확인했다. 8‑mer와 4‑nt 스니펫을 이용한 약한 연결에서는 10‑NN 기준 88 %의 정확도를 달성했으며, 무작위 스니펫을 사용한 대조 실험에 비해 현저히 높은 성공률을 보였다.
논문은 또한 기존의 BioVec·seq2vec와 차별화되는 점을 강조한다. 이들 방법은 고정 길이 kmer에만 적용되었지만, dna2vec은 3~8 길이의 kmer를 동일한 임베딩 공간에 매핑함으로써 길이 독립적인 표현을 가능하게 한다.
결론에서는 dna2vec이 차원 저주를 극복하고, 서열 유사성 및 연산적 특성을 보존하는 강력한 도구임을 재확인한다. 향후 연구 과제로는 다른 종의 게놈, 메타게놈 데이터에 대한 일반화 검증 및, 학습된 임베딩을 직접 활용한 분류·클러스터링·예측 모델 구축이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기