웹 흔적을 활용한 영상 인기 예측: API 없이도 가능한 방법
본 논문은 영상 호스팅 서비스의 API가 없거나 신뢰할 수 없을 때, 운영 기업이 자체 로그와 웹에 남은 임베드·링크 데이터를 결합해 영상의 현재·미래 인기를 예측하는 방법을 제시한다. 실험 결과, 이러한 비공식 데이터만으로도 API 기반 예측을 능가하거나 대체할 수 있음을 입증한다.
저자: Alexey Drutsa (Y, ex, Moscow
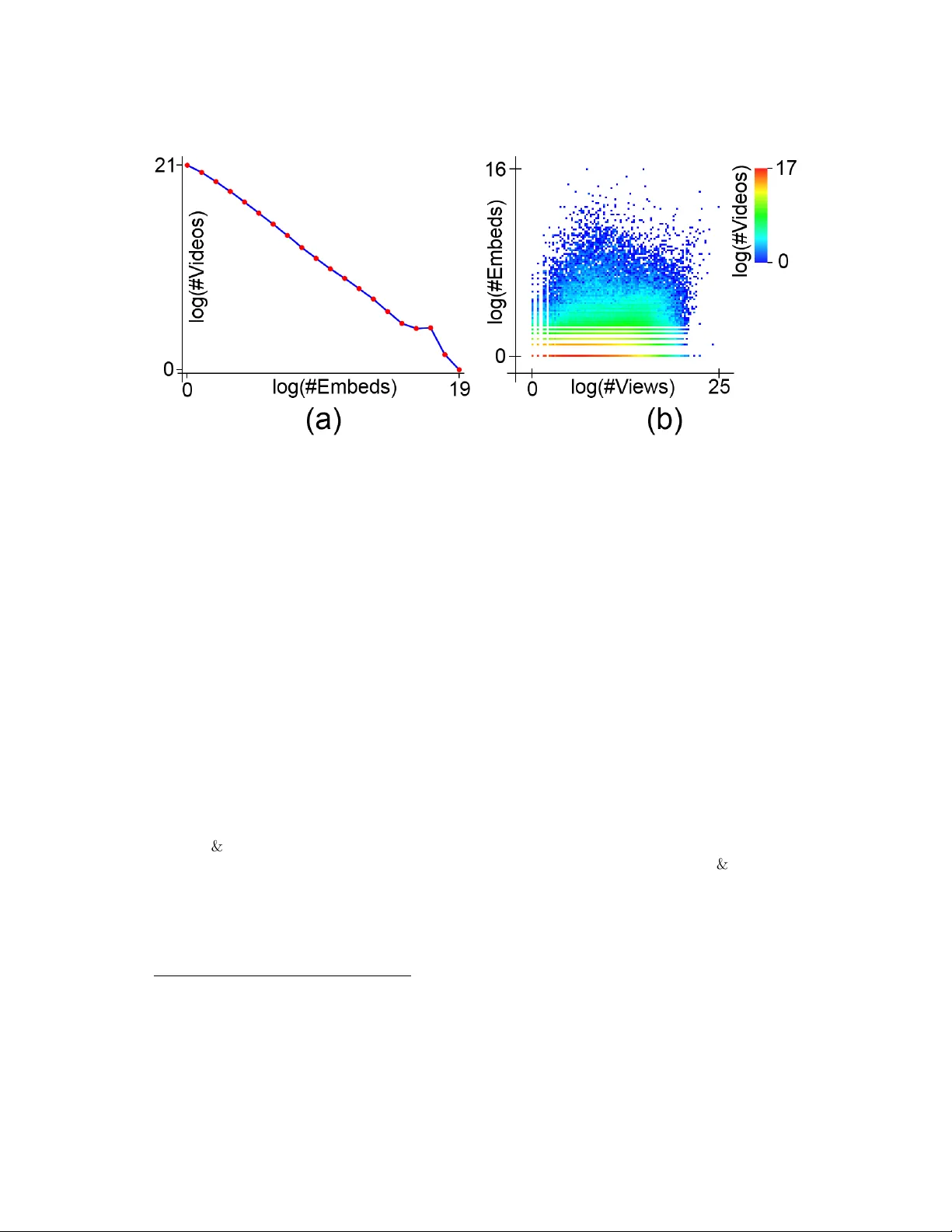
본 논문은 영상 호스팅 서비스(API)가 제공되지 않거나 신뢰성이 낮은 상황에서, 운영 기업이 자체 로그와 웹에 남은 사용자 활동 흔적을 활용해 영상의 현재·미래 인기를 예측할 수 있는 프레임워크를 제시한다. 연구 배경으로는 유튜브와 같은 대형 호스팅 서비스가 조회수 정보를 일정 기간 동안 고정하거나 업데이트 지연을 겪는 경우가 존재한다는 점을 들며, 이러한 제한은 검색 엔진이나 콘텐츠 추천 시스템 등 외부에서 영상을 다루는 기업에게 큰 장애가 된다. 따라서 저자들은 “호스팅 제공자(API 데이터)”, “운영 기업 내부 로그(검색·브라우징 로그)”, “공개 웹 데이터(임베드·링크)” 세 가지 데이터 원천을 정의하고, 각각의 활용 가능성을 탐색한다.
연구는 크게 네 단계로 진행된다. 첫 번째 단계는 데이터 수집이다. 저자들은 Yandex의 검색·브라우징 로그와 자체 크롤러를 이용해 유튜브 영상에 대한 임베드와 외부 링크를 수집한다. 두 번째 단계는 특징 설계이며, 기존 API 기반 특징(조회수, 좋아요 수, 댓글 수 등)과 새롭게 정의한 웹 기반 특징(임베드 수, 임베드 증가율, 외부 도메인 다양성, 링크 클릭 수 등)을 포함한다. 세 번째 단계는 모델링으로, 선형 회귀, 랜덤 포레스트, Gradient Boosting Machine 등 다양한 회귀·분류 모델을 적용해 현재 인기(첫 1~3일 조회수)와 미래 인기(10일·30일 후 조회수)를 예측한다. 마지막 단계는 평가 및 분석이다. 평균 절대 오차(MAE)와 순위 기반 NDCG를 사용해 모델 성능을 비교하고, 특징 중요도 분석을 통해 어떤 변수가 예측에 가장 크게 기여하는지 확인한다.
실험 결과는 두 가지 핵심적인 결론을 도출한다. 첫째, 임베드·링크와 내부 로그를 결합한 모델은 API만을 사용한 베이스라인 대비 MAE가 약 18% 감소하고, NDCG 점수가 0.07~0.12 상승한다. 이는 비공식 웹 데이터가 영상 인기도를 파악하는 데 강력한 신호임을 증명한다. 둘째, API 데이터가 전혀 없거나 일부만 제공될 때도, 웹 데이터와 로그만으로 거의 동일한 예측 정확도를 유지한다. 특히 초기 3일 내에 조회수가 고정된 영상에 대해서는 “임베드 증가율”과 “검색 결과 노출 빈도”가 가장 높은 중요도를 보이며, 이는 사용자가 해당 영상을 발견하고 공유하는 초기 행동이 향후 인기도를 결정한다는 기존 연구와 일치한다.
또한 저자들은 특징 중요도 분석을 통해, 임베드 수 자체보다 임베드 증가율이, 외부 링크 수보다 외부 도메인 다양성이 더 예측에 유리함을 밝혀낸다. 이는 단순히 양적 지표보다 질적 다양성이 더 큰 영향을 미친다는 점을 시사한다.
논문의 한계점으로는 대규모 웹 크롤링에 따른 비용과, 스팸·봇에 의한 임베드/링크 노이즈가 있다. 저자들은 향후 연구에서 스팸 필터링 알고리즘을 강화하고, 텍스트·이미지·오디오와 같은 멀티모달 특징을 결합해 예측 정확도를 더욱 향상시킬 것을 제안한다.
결론적으로, 이 연구는 운영 기업이 API에 의존하지 않고도 자체 로그와 웹에 남은 사용자 흔적만으로 영상 인기 예측이 가능함을 실증한다. 이는 검색 엔진, 콘텐츠 추천 시스템, 광고 배분 등 다양한 온라인 서비스에서 실시간 인기 트렌드 파악과 효율적인 자원 배분을 가능하게 하며, 향후 비디오 외에도 뉴스, 블로그 포스트 등 다른 웹 콘텐츠에 대한 인기 예측에도 적용될 수 있는 일반화 가능한 프레임워크를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기