큰 오류에 민감한 신경망 학습을 위한 가변 민감도 기법
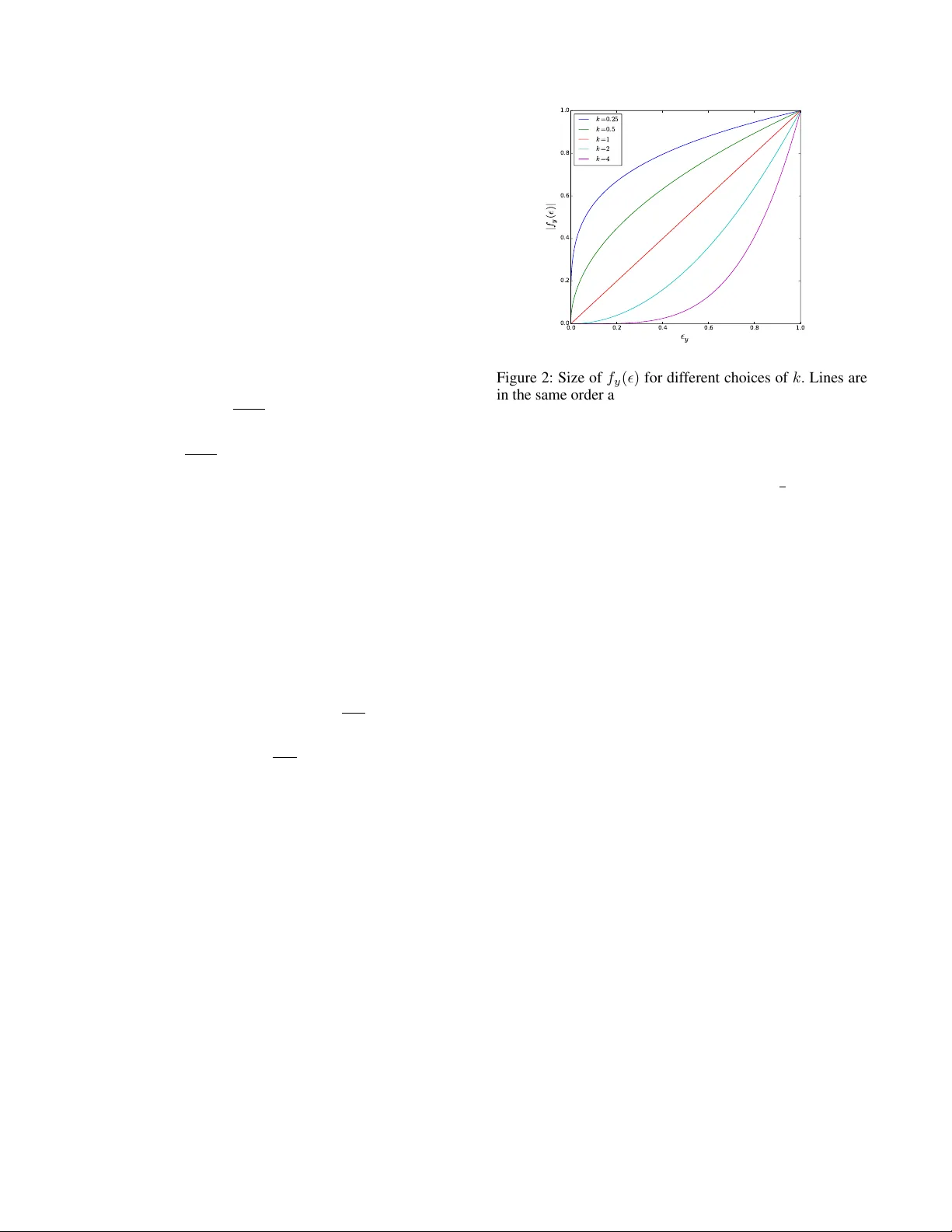
본 논문은 인간이 학습 과정에서 어려운 예제를 단계적으로 다루는 방식을 모방하여, 신경망 훈련 시 큰 예측 오류에 대한 민감도를 조절할 수 있는 새로운 그래디언트 일반화 기법을 제안한다. 파라미터 k (>0)를 통해 하드 샘플에 대한 영향력을 강화하거나 약화시킬 수 있으며, 실험 결과 깊은 네트워크일수록 k 값을 크게 잡는 것이 최적 성능을 내는 것으로 확인되었다.
저자: Gil Keren, Sivan Sabato, Bj"orn Schuller
본 논문은 인간이 새로운 개념을 배울 때 처음에는 이해하기 어려운 예제를 무시하고, 학습이 진행됨에 따라 점차 그 예제들을 활용한다는 인지적 현상을 신경망 학습에 적용하고자 한다. 이를 위해 저자들은 교차엔트로피 손실의 그래디언트를 일반화하는 새로운 프레임워크를 제시한다.
1. **배경 및 동기**
교차엔트로피 손실은 예측 편향 γ_j (예측 확률과 실제 라벨 간 차이)에 대해 선형적인 그래디언트를 제공한다. 따라서 잘못된 고신뢰 예측이 큰 업데이트를 일으키고, 반대로 낮은 신뢰도의 오류는 작은 영향을 미친다. 그러나 실제 학습에서는 하드 샘플이 모델의 표현력을 향상시키는 중요한 정보원이 될 수 있다. 기존 커리큘럼 학습은 샘플을 쉬운 순서대로 제공하지만, 데이터 순서를 무작위로 유지하면서도 하드 샘플에 대한 민감도를 조절하는 방법은 부족했다.
2. **문제 정의 및 기호**
다층 피드포워드 신경망을 가정하고, 소프트맥스 출력 p_j(x;Θ) 와 라벨 y 에 대해 교차엔트로피 ℓ = −log p_y 을 사용한다. 편향 γ_j 는 p_j − 1 (y=j) 혹은 p_j (그 외) 로 정의한다.
3. **그래디언트 일반화**
기존 그래디언트 ∂ℓ/∂θ = ∑_j ∂z_j/∂θ · γ_j 을 기반으로, 새로운 함수 f:
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기