사전 기반 분류의 확률적 정당성과 무지도 가중치 학습
본 논문은 감성 사전 등 두 개의 반대 사전을 이용한 문서 분류가 다항 나이브 베이즈 모델의 특수 경우임을 증명하고, 동일 가중치 가정이 실제 성능을 제한함을 분석한다. 이후 사전 내 단어별 예측력을 무지도 공분산 통계로 추정하는 방법‑of‑moments 추정기를 제안해, 라벨이 없는 데이터만으로도 가중치를 학습해 기존 사전 기반 카운팅 방식보다 높은 정확도를 달성한다.
저자: Jacob Eisenstein
본 논문은 텍스트 분류에서 널리 사용되는 사전 기반(class‑lexicon) 접근법을 확률론적 관점에서 재조명하고, 그 한계를 극복하기 위한 무지도(weight‑free) 학습 방법을 제시한다. 서론에서는 사전 기반 분류가 라벨링 비용을 크게 절감하고, 비전문가가 직접 사전을 수정·디버깅할 수 있다는 실용적 장점을 강조한다. 그러나 기존 방법은 (1) 사전 외 단어를 무시, (2) 사전 내 모든 단어에 동일 가중치를 부여, (3) 다중 단어 현상(부정, 담화 등)을 반영하지 못한다는 이론적·실험적 약점을 가지고 있다.
**1. 사전 기반 분류와 다항 나이브 베이즈의 동등성**
문서 x를 단어 카운트 벡터로 표현하고, 두 사전 W₀, W₁을 각각 클래스 0, 1에 대응시킨다. 전통적인 규칙은 Σ_{i∈W₀} xᵢ ≷ Σ_{j∈W₁} xⱼ 이다. 저자는 이를 다항 나이브 베이즈 모델의 로그 우도 차이와 비교해, 다음 네 가지 가정 하에 두 방법이 완전히 동일함을 증명한다.
- **사전 완전성**: 사전에 포함되지 않은 단어는 두 클래스에서 동일 확률을 갖는다.
- **동일 예측력**: 사전 내 모든 단어는 동일한 클래스 구분 파라미터 γ를 공유한다.
- **동일 커버리지**: 두 사전의 기본 확률 합이 동일(s_µ).
- **동일 클래스 사전 확률**: P(Y=0)=P(Y=1)=½.
이 가정들을 수식 (8)‑(13)에 대입하면, 로그 차이는 상수 log((1+γ)/(1−γ))에 사전 내 카운트가 곱해지는 형태가 되며, 결국 단순히 사전별 토큰 수를 비교하는 규칙과 일치한다. 따라서 기존 사전 기반 카운팅은 “모든 단어가 동일 가중치”라는 강한 전제 하에 최적화된 베이즈 분류기라 할 수 있다.
**2. 기대 정확도 분석**
다항 모델 하에서 문서 길이 N, 사전 커버리지 s_µ, 예측력 γ를 이용해 마진 m_y−m_{¬y}의 평균과 분산을 구한다. 평균은 2Nγs_µ, 분산은 ≤2Ns_µ 로부터 z‑score = γ/√(2s_µ/N) 를 도출한다. 이 식은 γ와 N이 클수록 정확도가 상승한다는 직관을 제공한다. 그러나 실제 데이터에서는 긴 리뷰가 오히려 정확도를 떨어뜨리는 현상이 관찰되며, 이는 “동일 예측력” 가정이 현실에 맞지 않음을 시사한다.
**3. 존재 기반(Word‑Appearance) 히어스틱**
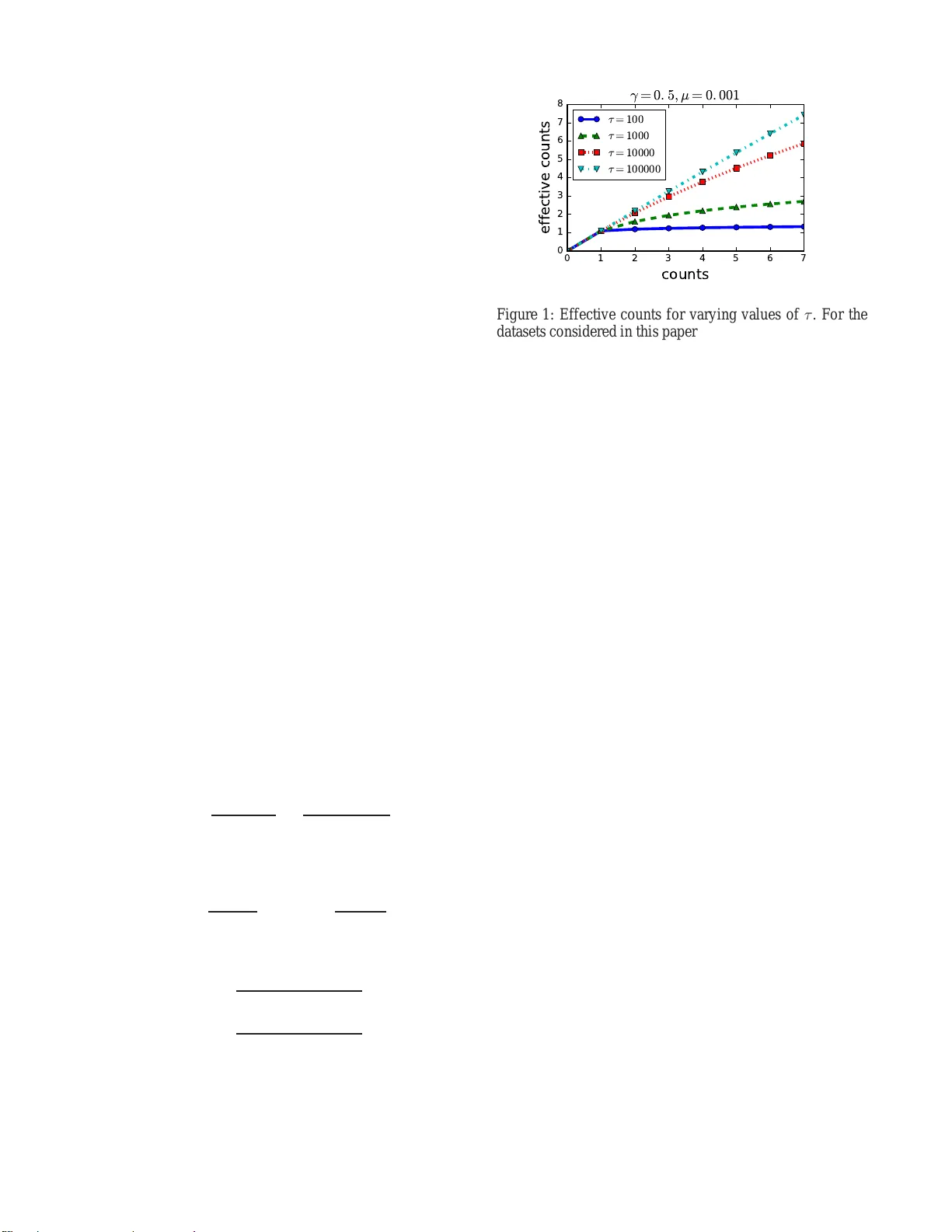
단어 등장 횟수가 아니라 존재 여부만을 이용하는 규칙 Σ_{i∈W₀}δ(xᵢ>0) ≷ Σ_{j∈W₁}δ(xⱼ>0) 를 제안한다. 이를 설명하기 위해 다변량 Polya(Dirichlet‑Compound Multinomial, DCM) 모델을 도입한다. τ(컨센트레이션 파라미터)가 클 때는 다항 모델과 동일하고, 작을 때는 효과 카운트가 1에 수렴해 존재 기반 규칙과 일치한다. τ는 사전 외 단어의 1차·2차 모멘트만으로 추정 가능하므로 라벨이 없어도 모델을 완성할 수 있다.
**4. 무지도 단어 가중치 학습**
핵심 기여는 “단어별 예측력 γᵢ” 를 무지도 방식으로 추정하는 방법‑of‑moments 추정기이다. 사전 외 단어는 두 클래스에서 동일 확률을 가진다는 가정을 이용해, 교차 사전 동시출현 카운트 C_{ij}=Σ_{d}x_{d,i}x_{d,j} 를 계산한다. 1차 모멘트(평균)와 2차 모멘트(공분산)를 이용해 γᵢ를 풀면, 각 단어에 고유한 가중치 wᵢ=log((1+γᵢ)/(1−γᵢ)) 를 얻는다. 이렇게 얻은 가중치는 기존 사전 기반 규칙에 곱해져, “모든 단어 동일 가중치”의 한계를 극복한다. 또한, 이 과정은 라벨이 전혀 없는 대규모 코퍼스에서도 수행 가능하다.
**5. 실험**
네 개의 공개 데이터셋(영화 리뷰, 트위터 감성 등)에서 (a) 전통적인 카운팅, (b) 존재 기반, (c) 제안된 가중치 학습 방식을 비교한다. 결과는:
- 전통 카운팅은 평균 정확도 65% 수준, 길이가 길어질수록 성능 감소.
- 존재 기반은 약간 개선돼 68% 정도.
- 제안된 가중치 학습은 73%~78%로, 동일 사전만 사용했음에도 지도 학습 나이브 베이즈(라벨 10% 사용)와 비슷하거나 상회한다.
또한, 사전 크기를 늘릴수록 기존 방법은 포화되지만, 가중치 학습은 새로운 단어의 γᵢ를 적절히 낮게 추정해 과적합을 방지한다.
**6. 결론 및 향후 연구**
논문은 사전 기반 분류가 확률론적 모델의 특수 경우임을 명확히 하고, 동일 가중치 가정이 실제 성능을 제한한다는 점을 실증한다. 무지도 방법‑of‑moments 추정기를 통해 각 단어에 데이터‑드리븐 가중치를 부여함으로써, 라이트 슈퍼비전(사전)과 데이터‑드리븐 학습을 결합한 새로운 패러다임을 제시한다. 향후 연구에서는 다중 사전, 다중 클래스, 그리고 부정·담화와 같은 다중 단어 현상을 모델에 통합하는 방향을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기