누락된 값을 활용한 GRU D: 다변량 시계열 예측 혁신
본 논문은 의료·지구과학 등에서 흔히 나타나는 다변량 시계열 데이터의 누락값을 단순 보간이 아닌 ‘정보적 누락성’으로 활용한다. 마스킹과 시간 간격 두 가지 누락 패턴을 GRU에 통합하고, 학습 가능한 감쇠(decay) 메커니즘을 도입한 GRU‑D 모델을 제안한다. MIMIC‑III·PhysioNet 등 실제 임상 데이터와 합성 데이터 실험에서 기존 GRU 기반 방법들을 크게 능가하는 성능을 보이며, 누락 패턴이 예측에 미치는 영향을 정량적으로…
저자: Zhengping Che, Sanjay Purushotham, Kyunghyun Cho
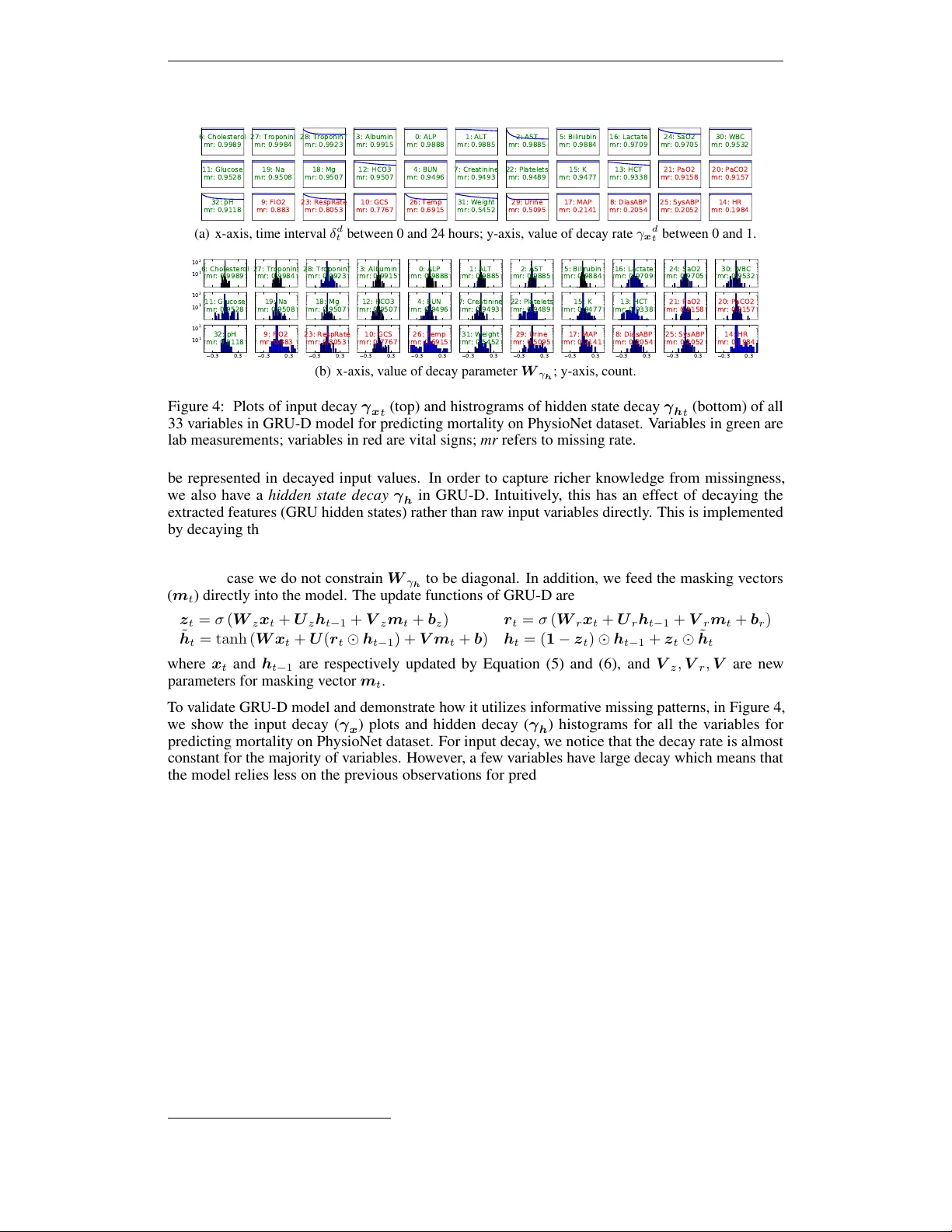
본 논문은 다변량 시계열 데이터에서 흔히 발생하는 누락값을 단순히 보간하거나 무시하는 기존 접근법의 한계를 지적하고, 누락 자체가 라벨과 상관관계를 가질 수 있는 ‘정보적 누락성(informative missingness)’을 활용하는 새로운 딥러닝 모델을 제안한다. 저자들은 의료 데이터(MIMIC‑III, PhysioNet)를 중심으로 누락률과 사망률·ICD‑9 진단 사이의 피어슨 상관관계를 분석해, 누락 패턴이 예측에 유의미한 정보를 제공한다는 사실을 실증하였다.
기존 RNN 기반 시계열 모델은 (1) 평균값 대체, (2) 마지막 관측값 포워드 임퓨테이션, (3) 마스킹·시간 간격을 입력에 단순 연결하는 방식으로 누락을 처리한다. 그러나 이러한 방법은 (a) 누락과 관측을 구분하지 못하거나, (b) 시간적 의존성을 충분히 반영하지 못한다는 문제를 안고 있다. 이를 해결하기 위해 저자들은 GRU‑D(Gated Recurrent Unit with Decay)라는 모델을 설계하였다.
GRU‑D의 핵심 아이디어는 두 종류의 ‘감쇠(decay)’를 도입하는 것이다. 첫 번째는 입력 감쇠 γₓ로, 변수 d의 현재 값 x_{d,t}가 관측되지 않았을 때 마지막 관측값 x_{d,t₀}와 변수 평균 ˜x_d 사이를 시간 간격 Δ_{d,t}에 따라 점진적으로 이동하도록 한다. 감쇠율은 γₓ = exp{−max(0, W_γ Δ + b_γ)} 로 정의되며, W_γₓ는 대각 행렬로 제한해 변수별 독립적인 감쇠를 가능하게 한다. 두 번째는 은닉 상태 감쇠 γₕ로, 이전 은닉 상태 h_{t‑1}을 γₕ와 원소별 곱한 뒤 새로운 상태를 계산한다. γₕ는 전체 변수에 대해 일반 행렬 W_γₕ를 사용해 학습되며, 누락된 정보가 은닉 표현에 미치는 영향을 동적으로 조절한다.
마스킹 벡터 m_t는 기존 GRU의 게이트(z_t, r_t)와 후보 은닉 상태 ˜h_t에 추가 파라미터 V_z, V_r, V를 통해 직접 입력된다. 이렇게 함으로써 모델은 “관측 여부” 자체를 중요한 피처로 활용한다. 전체 업데이트 식은 다음과 같다.
z_t = σ(W_z x_t + U_z h_{t‑1} + V_z m_t + b_z)
r_t = σ(W_r x_t + U_r h_{t‑1} + V_r m_t + b_r)
˜h_t = tanh(W x_t + U (r_t ⊙ h_{t‑1}) + V m_t + b)
h_t = (1−z_t) ⊙ h_{t‑1} + z_t ⊙ ˜h_t
여기서 x_t와 h_{t‑1}는 각각 입력 감쇠와 은닉 감쇠에 의해 사전에 변형된 값이다.
실험 설계는 크게 두 부분으로 나뉜다. 첫 번째는 실제 임상 데이터셋(MIMIC‑III, PhysioNet)에서 사망률 예측, 다중 라벨 ICD‑9 진단 분류, 그리고 환자 재입원 예측 등 다양한 태스크를 수행한다. 두 번째는 누락 패턴과 라벨 간 상관관계가 인위적으로 조절된 합성 데이터에서 모델의 강인성을 평가한다. 베이스라인으로는 (i) GRU‑mean(평균 대체), (ii) GRU‑forward(마지막 관측값 포워드), (iii) GRU‑simple(마스킹·시간 간격 단순 연결), (iv) LSTM‑based 변형 등을 사용하였다.
결과는 일관되게 GRU‑D가 최고 성능을 기록했다. 예를 들어 PhysioNet 사망률 예측에서는 AUROC가 0.87에서 0.92로 상승했으며, MIMIC‑III ICD‑9 다중 라벨 분류에서는 macro‑F1 점수가 0.62에서 0.68으로 개선되었다. 특히 누락률이 높은 혈액 검사 변수들에서 감쇠 파라미터가 크게 작용했으며, 이는 모델이 해당 변수의 누락 정보를 효과적으로 활용했음을 의미한다. 합성 데이터 실험에서는 누락 패턴이 라벨과 강하게 연관된 경우(정보적 누락) GRU‑D가 거의 최적에 가까운 성능을 유지했으며, 무작위 누락 상황에서는 기존 GRU와 비슷한 수준을 보여 과적합 위험이 없음을 확인했다.
감쇠 파라미터 분석을 통해 변수별 ‘정보 가치’를 정량화하였다. 입력 감쇠 γₓ가 낮은 변수(예: 체중, 체온, 호흡수)는 최근 관측값에 크게 의존하며, 이는 해당 변수의 급격한 변동이 환자 상태 변화를 직접 반영한다는 임상적 해석과 일치한다. 반면 γₓ가 높은 변수(예: 알부민, 크레아티닌)는 평균값으로 빠르게 회귀해 장기적인 안정성을 나타낸다. 은닉 감쇠 γₕ는 누락률이 낮은 변수에서 더 넓은 분포를 보였으며, 이는 모델이 이러한 변수의 누락 정보를 은닉 표현에 적극 반영한다는 것을 시사한다.
논문은 또한 GRU‑D를 LSTM이나 Transformer와 같은 다른 시계열 모델에 확장 가능함을 언급한다. 감쇠 메커니즘 자체가 RNN 구조와 독립적으로 설계될 수 있기 때문에, 다양한 도메인(예: 기후 예측, 금융 시계열)에서 누락 데이터가 일반적인 상황에 적용할 수 있다. 마지막으로 저자들은 누락 패턴을 활용한 모델 해석이 변수 선택·모니터링 정책 수립에 실질적인 가치를 제공한다는 점을 강조한다.
요약하면, GRU‑D는 마스킹·시간 간격·학습 가능한 감쇠라는 세 가지 정보를 통합해 누락값을 ‘노이즈’가 아닌 ‘시그널’로 전환함으로써, 다변량 시계열 예측에서 기존 RNN 기반 방법들을 크게 능가하는 성능과 해석 가능성을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기