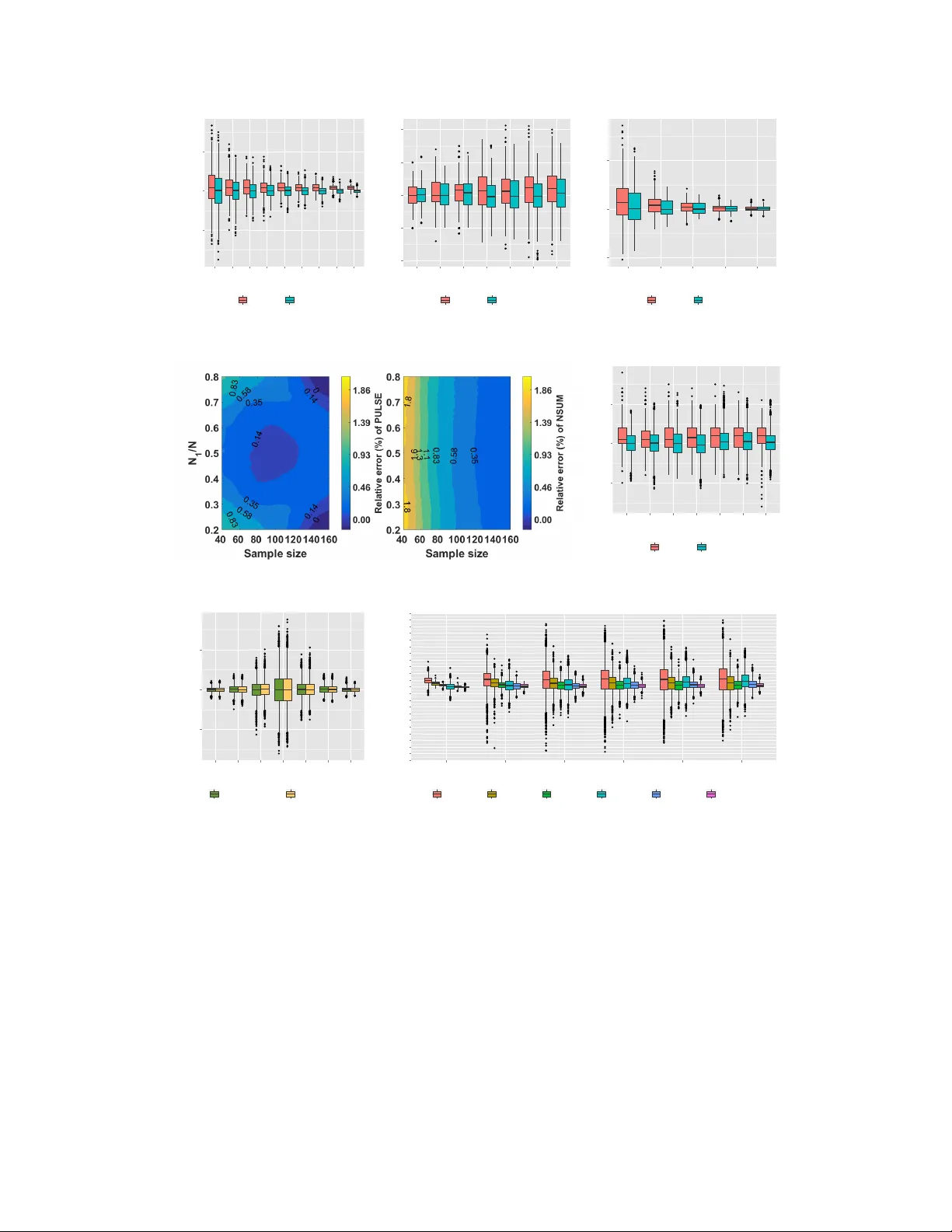
무작위 샘플로부터 대규모 네트워크와 커뮤니티 규모 추정
본 논문은 확률적 블록 모델(SBM)로 생성된 대규모 그래프에서, 무작위로 선택된 정점 집합의 유도 서브그래프와 각 정점의 전체 차수·블록 정보를 이용해 전체 정점 수와 각 커뮤니티 규모를 효율적으로 추정하는 베이지안 알고리즘 PULSE를 제안한다. 이론적 정당성을 보이고, 기존 네트워크 스케일‑업 추정기(NSUM)와 비교한 실험에서 편향·분산 모두에서 우수함을 입증한다.
저자: Lin Chen, Amin Karbasi, Forrest W. Crawford
본 논문은 “무작위 샘플로부터 대규모 네트워크와 커뮤니티 규모 추정”이라는 문제를 다루며, 특히 확률적 블록 모델(SBM)이라는 통계적 그래프 생성 모델을 전제로 한다. SBM은 K개의 블록(또는 커뮤니티)으로 구성된 정점 집합 V와, 블록 i와 j 사이에 정점 쌍이 연결될 확률 p_{ij}를 정의한다. 이러한 모델은 실제 소셜 네트워크, 웹 페이지, 인터넷 라우터 등 다양한 실세계 네트워크가 보이는 커뮤니티 구조를 수학적으로 포착한다.
연구자는 전체 정점 수 N=|V|와 각 블록의 정점 수 N_i (i=1,…,K)를 직접 관측하기 어려운 상황을 가정한다. 대신, 전체 정점 집합에서 균등 무작위로 n개의 정점 W를 선택하고, 그에 대한 유도 서브그래프 G(W)와 각 샘플 정점 v∈W의 전체 차수 d(v) 및 블록 레이블 t(v)를 관측한다. 여기서 중요한 점은 d(v)에서 샘플 내부에 존재하는 이웃을 제외한 ‘펜던트 차수’ ˜d(v) 를 계산할 수 있다는 것이다. ˜d(v)는 v가 샘플 외부에 있는 정점들과 맺고 있는 에지 수를 의미하지만, 그 대상 정점들의 블록은 알 수 없다.
이러한 불완전 정보를 활용하기 위해 저자들은 베이지안 추정 프레임워크를 설계한다. 우선 각 블록 간 연결 확률 p_{ij}에 독립적인 베타 사전 B(α_{ij},β_{ij})를 부여하고, 외부 정점 수 ˜N_i=N_i−|W∩V_i|에 대해서는 일반적인 비음이 아닌 사전 φ(˜N) (예: 균등 혹은 지수형)를 설정한다. 관측 데이터 D=(G(W),{d(v)}, {t(v)})에 대한 전체 우도는 두 부분으로 나뉜다.
1. **내부 에지 우도 L_W**: 샘플 W 내부에서 관측된 에지 수 E_{ij}는 이항 분포를 따르며, L_W는 ∏_{i≤j} p_{ij}^{E_{ij}}(1−p_{ij})^{V_i V_j−E_{ij}} 형태이다.
2. **펜던트 에지 우도 L_{¬W}**: 각 정점 v에 대해 외부 정점 중 블록 i와 연결된 수 y_i(v) 를 정의한다. y_i(v)는 정수이며 Σ_i y_i(v)=˜d(v) 를 만족한다. 주어진 ˜N_i와 p_{ij} 하에서 y_i(v)는 다항형(다중 이항) 분포를 따른다. 따라서 L_{¬W}=∏_{v∈W}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기