예측 API를 통한 머신러닝 모델 탈취
본 논문은 공개 예측 API를 제공하는 ML‑as‑a‑Service 환경에서, 공격자가 모델 파라미터나 구조를 거의 완벽히 복제할 수 있는 “모델 추출” 공격을 제시한다. 신뢰도(Confidence) 값과 부분 입력 허용을 이용해 로지스틱 회귀, 신경망, 결정 트리 등 다양한 모델을 적은 쿼리로 복원하고, 신뢰도 값을 제거한 경우에도 적응형 알고리즘으로 높은 정확도의 추출이 가능함을 실험적으로 증명한다.
저자: Florian Tram`er, Fan Zhang, Ari Juels
본 논문은 머신러닝 모델이 클라우드 기반 서비스 형태로 제공될 때, 공개된 예측 API를 통해 모델 자체를 탈취할 수 있는 “모델 추출(Model Extraction)” 공격을 체계적으로 연구한다. 저자들은 먼저 모델 기밀성에 대한 필요성을 강조한다. 의료 기록, 금융 데이터 등 민감한 훈련 데이터와 모델 자체가 상업적 가치를 가지는 경우가 많으며, 이러한 모델을 pay‑per‑query 형태로 제공하는 ML‑as‑a‑Service(MLaaS) 플랫폼이 급증하고 있다. 이러한 환경에서 모델에 대한 블랙박스 접근만으로도 모델을 복제할 수 있다면, 서비스 제공자는 수익을 잃고, 사용자는 민감한 데이터가 유출될 위험에 처한다.
논문의 핵심 기여는 다음과 같다.
1. **Confidence 기반 방정식 풀이 공격**
- 대부분의 상용 서비스는 예측 결과와 함께 각 클래스에 대한 확률(Confidence) 값을 반환한다. 로지스틱 회귀의 경우, Confidence는 1/(1+e^{-(w·x+β)}) 형태의 로짓 함수이며, d 차원 입력에 대해 d+1개의 무작위 질의를 보내면 선형 방정식 시스템을 구성할 수 있다. 이를 풀어 w와 β를 정확히 복원한다.
- 다중 클래스 로지스틱 회귀와 완전 연결 신경망에도 동일한 원리를 적용한다. 각 출력 뉴런에 대한 선형 결합을 추정하고, 활성화 함수가 알려진 경우(예: 시그모이드, 소프트맥스) 파라미터를 역추정한다.
- 실험에서는 Amazon ML의 로지스틱 회귀 모델을 650개의 질의로 100% 복제했으며, 신경망 모델도 수천 개의 질의로 거의 완전한 복원을 보였다.
2. **결정 트리 구조 추출**
- 트리 모델은 비선형 구조이므로 단순 방정식 풀이가 적용되지 않는다. 그러나 서비스가 반환하는 Confidence 값은 해당 입력이 트리의 어느 리프에 도달했는지를 나타내는 “경로 식별자” 역할을 한다.
- 저자들은 이 값을 이용해 리프마다 고유한 식별자를 부여하고, 부분 입력(특정 피처를 누락한 질의)을 활용해 각 노드의 분할 조건을 추정한다. 예를 들어, 특정 피처를 고정하고 다른 피처를 변화시켜 Confidence 값이 변하는 지점을 찾음으로써 분할 임계값을 알아낸다.
- 이러한 탐색을 반복하면 트리의 전체 구조와 리프에 저장된 클래스 비율을 복원할 수 있다. BigML 서비스에서 1,150개의 질의만으로 원본 트리와 동일한 구조를 얻었다.
3. **Confidence 값 제거에 대한 대응 공격**
- 가장 직관적인 방어책은 Confidence 값을 반환하지 않고 클래스 라벨만 제공하는 것이다. 저자들은 이 경우에도 모델 추출이 가능함을 보인다.
- Lowd와 Meek가 제안한 적응형 선형 분류기 추출 알고리즘을 다중 클래스와 신경망에 확장하였다. 질의를 통해 경계면을 점진적으로 탐색하고, 각 클래스에 대한 결정 경계를 근사한다.
- 또한, Cohn 등의 아그노스틱 학습 기법을 변형해 다중 클래스 로지스틱 회귀와 신경망에 적용했으며, 99% 이상의 정확도로 모델을 복제했다. 다만, Confidence 값을 이용한 경우보다 질의 수가 10배~100배 정도 증가한다.
4. **실험 및 결과**
- 저자들은 공개 데이터셋(예: MNIST 손글씨, Adult 인구통계, German Credit 등)을 사용해 모델을 학습하고, 해당 모델을 실제 서비스에 배포한 뒤 공격을 수행했다.
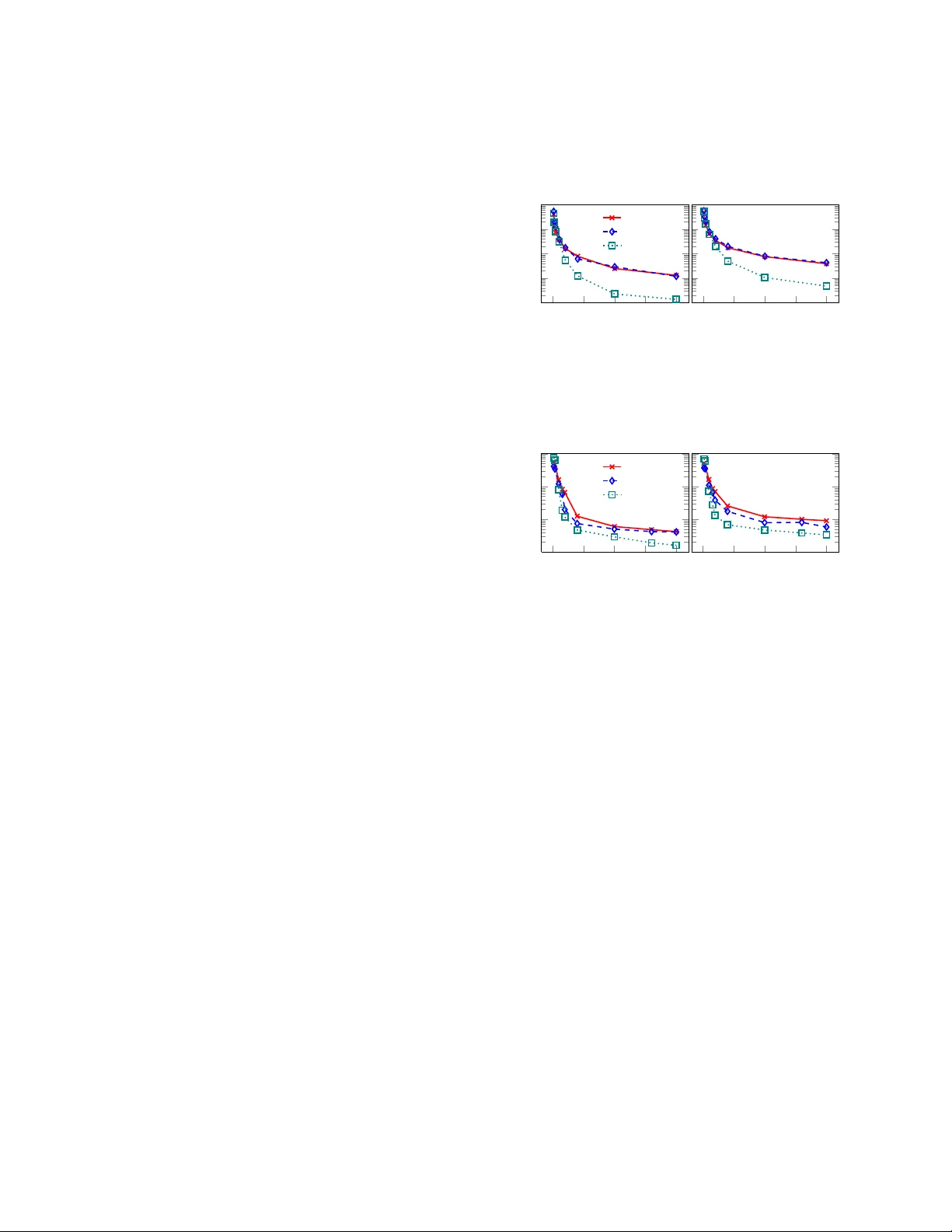
- Table 1에 제시된 바와 같이, 로지스틱 회귀, SVM, 신경망, 결정 트리 모두 100% 동등한 모델을 수천 개 이하의 질의로 복제했다.
- 또한, Amazon 서비스에서 모델 추출을 통해 훈련 데이터의 평균, 분산 등 통계 정보를 유추할 수 있었으며, 커널 로지스틱 회귀의 경우 개별 훈련 샘플에 대한 정보를 부분적으로 복원할 수 있음을 보였다.
5. **보안·프라이버시 함의**
- 모델 추출 자체가 비즈니스 모델을 위협한다. 공격자는 저렴한 비용으로 모델을 복제해 자체 서비스에 활용하거나, 무료로 제공받을 수 있다.
- 추출된 모델을 이용해 모델 역전(model inversion)이나 속성 추론(attribute inference) 공격을 수행하면 훈련 데이터의 민감한 정보를 유출할 위험이 있다.
- 논문은 단순 출력 제한만으로는 충분하지 않으며, 질의 제한, 차등 프라이버시, 모델 난수화 등 보다 근본적인 방어 메커니즘이 필요함을 주장한다.
6. **결론**
- 현재 상용 MLaaS가 제공하는 API 설계는 모델 기밀성을 크게 위협한다. Confidence 값과 부분 입력 허용은 공격자가 모델 파라미터와 구조를 효율적으로 역추정할 수 있게 만든 핵심 요인이다.
- 저자들은 실용적인 공격 방법을 제시함으로써 서비스 제공자와 연구 커뮤니티가 보다 강력한 방어 전략을 모색하도록 촉구한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기