트위터 해시태그 전염성 모델링
본 연구는 뉴욕과 샌프란시스코 지역에서 수집한 트위터 해시태그 데이터를 이용해 SIR·SIRI 전염병 모델과 베이지안 MCMC 추정법을 적용, 각 해시태그의 감염률(β)과 회복률(γ·ν)을 추정하고 기본 재생산수 R을 계산한다. 분석 결과 해시태그는 대체로 R≈1에 가까운 약한 전염성 그룹과 R≫1인 강한 전염성 그룹으로 구분되며, 지리적 차이는 미미함을 보인다.
저자: Jonathan Skaza, Brian Blais
본 논문은 트위터 해시태그의 확산 과정을 전염병 모델링 기법으로 분석하여, 해시태그가 얼마나 ‘전염성’ 있는지를 정량적으로 평가한다. 서론에서는 트위터가 3억 명 이상의 월간 활성 사용자를 보유하고 있으며, 하루 5억 건 이상의 트윗이 생성된다는 배경을 제시한다. 해시태그는 트윗을 메타데이터로 묶어 주제별 검색을 가능하게 하지만, 기존 키워드 기반 검색은 긍정·부정 문맥을 구분하기 어려워 해시태그를 ‘프록시’로 활용하는 접근법을 제시한다.
관련 연구 파트에서는 전통적인 SIR 모델이 전염병 예측에 널리 쓰였으며, 이를 정보 확산에 적용한 선행 연구들을 소개한다. 특히, 감염률 β와 회복률 γ를 파라미터화한 미분 방정식이 해시태그의 시간적 변화를 설명할 수 있음을 논한다. 또한, 회복 과정이 단순 시간 감소가 아니라 회복 인구에 의존한다는 가정 하에 SIRI 모델을 도입한다.
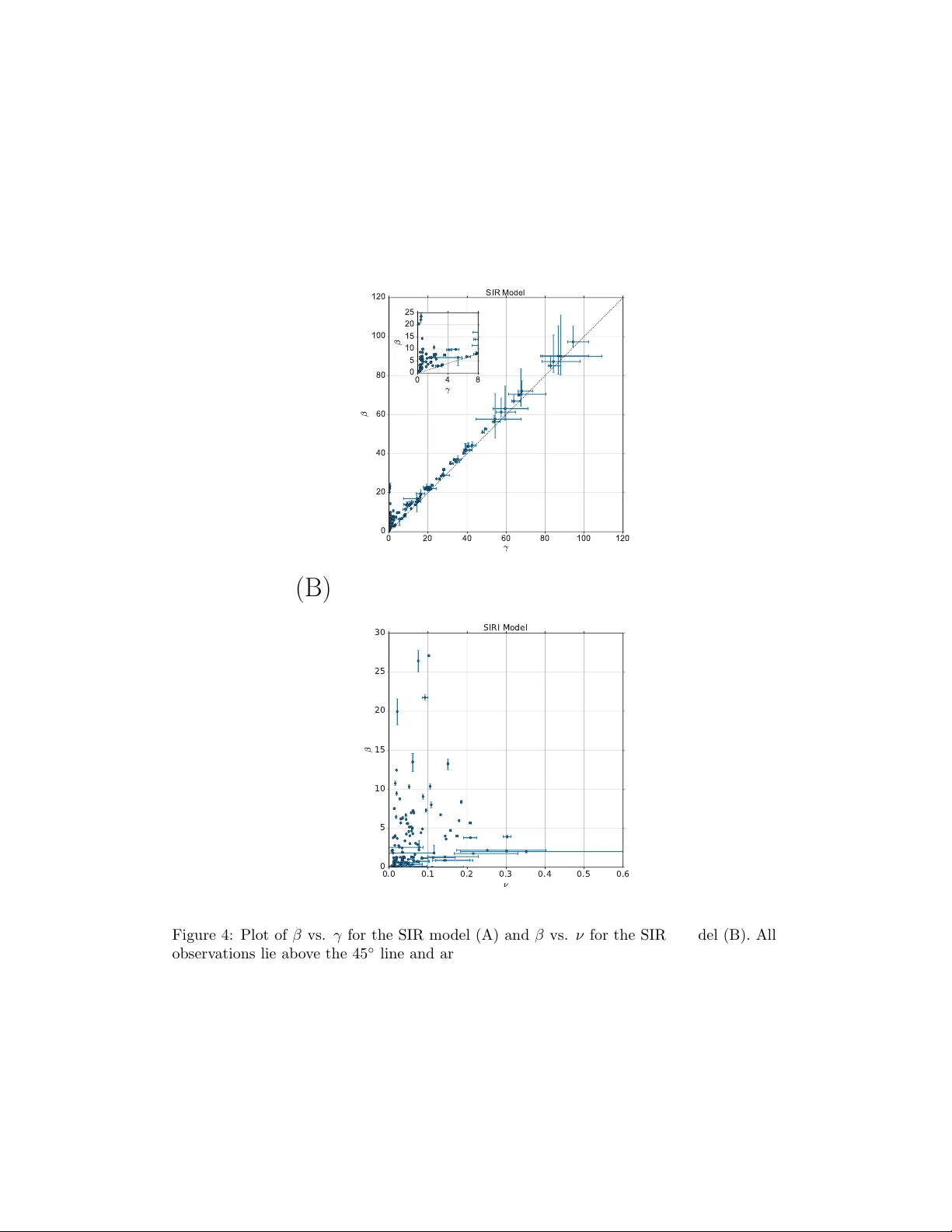
데이터 수집은 트위터 스트리밍 API와 파이썬 스크립트를 이용해 뉴욕시와 샌프란시스코의 지리적 트렌딩 토픽을 실시간으로 캡처한다. 수집된 트윗은 해시태그를 기준으로 시간 스탬프와 함께 저장되며, 1시간 이동 평균을 적용해 연속적인 시계열로 변환한다. 이후 피크 탐지를 자동화하여 각 해시태그별 ‘감염 구간’을 정의한다. 구간은 피크값의 1/100 수준까지 감소하는 전후 시점을 t₁, t₂ 로 설정하고, 이 구간 내 데이터를 모델 피팅에 사용한다.
모델링 단계에서는 SIR 및 SIRI 두 종류의 미분 방정식을 파라미터 β, γ(또는 ν)와 초기 상태 I₀, S₀와 함께 베이지안 프레임워크에 통합한다. 파라미터 사전분포는 균등분포를 가정하고, affine‑invariant ensemble sampler를 이용해 500,000 번의 MCMC 샘플링을 수행한다. 버닝 단계(50%)를 제외한 사후 샘플을 통해 각 파라미터의 평균값과 신뢰구간을 추정하고, 기본 재생산수 R을 계산한다. R>1이면 전염성, R≈1이면 경계 상태, R<1이면 소멸을 의미한다.
실험 결과는 크게 세 부분으로 제시된다. 첫째, 개별 해시태그에 대한 시계열 피팅 예시를 통해 SIR 모델이 대부분의 데이터에 대해 좋은 적합도를 보이며, 다중 피크가 있는 경우 첫 번째 피크를 중심으로 모델링하거나 전체 피크를 평균화하는 방식을 사용한다. 둘째, 전체 해시태그에 대한 β와 γ(또는 ν) 산점도를 그린 결과, 대부분의 점이 45도 선 근처에 몰려 있어 평균 R이 1에 가깝다는 것을 확인한다. 그러나 하단 좌측에 위치한 약 20%의 해시태그는 선 위쪽에 있어 R이 크게 1을 초과, 즉 매우 높은 전염성을 나타낸다. 셋째, R 값의 히스토그램을 통해 두 도시 간 차이가 없으며, SIRI 모델이 피드백 효과를 반영해 전반적으로 더 높은 R 값을 도출함을 확인한다.
논의에서는 해시태그가 두 그룹(약한 전염성, 강한 전염성)으로 구분된다는 점을 강조하고, 모델 가정(예: 감수 인구 고정, 회복이 선형 등)의 민감도 분석 필요성을 언급한다. 또한, 전 세계적인 데이터 확장, 다른 전염 모델과의 비교, 그리고 트렌드 라벨링 시스템에의 적용 가능성을 제시한다. 결론적으로, 이 연구는 해시태그 확산을 전염병 모델로 정량화함으로써 소셜 미디어 트렌드 분석에 새로운 도구를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기