GRU 기반 텍스트 추천: 다중과제 학습으로 강화된 딥 콜라보레이티브 필터링
이 논문은 논문 초록과 같은 텍스트를 아이템으로 갖는 추천 시스템에서, 텍스트를 순서까지 고려한 GRU(게이트 순환 유닛) 인코더를 이용해 아이템 잠재 요인을 직접 학습한다. 다중과제 학습으로 아이템 메타데이터(태그) 예측을 함께 수행함으로써 모델을 정규화하고, 특히 콜드 스타트 상황에서 기존 토픽 모델 기반 방법보다 크게 성능을 향상시킨다.
저자: Trapit Bansal, David Belanger, Andrew McCallum
본 논문은 텍스트가 핵심 콘텐츠인 아이템(논문, 영화, 뉴스 등)에 대한 추천 시스템을 설계하고 평가한다. 전통적인 협업 필터링은 사용자‑아이템 평점 행렬만을 이용해 잠재 요인 행렬을 학습하지만, 새로운 아이템에 대한 임베딩이 없어서 콜드 스타트 문제에 취약하다. 이를 보완하기 위해 기존 연구들은 아이템 메타데이터를 활용하거나, 토픽 모델(예: LDA) 혹은 평균 워드 임베딩을 사용해 텍스트를 잠재 요인으로 매핑했다. 그러나 이러한 방법들은 단어 순서를 무시하고, 텍스트와 평점 사이의 복잡한 비선형 관계를 충분히 포착하지 못한다는 한계가 있다.
저자들은 이러한 한계를 극복하기 위해 텍스트 인코더를 게이트 순환 유닛(GRU) 기반의 양방향 RNN으로 설계한다. 구체적으로, 각 단어는 사전 학습된 워드 임베딩(e_w)으로 변환되고, 두 층의 GRU 네트워크를 차례로 통과한다. 첫 번째 층은 양방향으로 동작해 앞뒤 컨텍스트를 모두 고려하고, 두 번째 층은 단방향으로 깊이를 추가한다. 두 번째 층의 모든 은닉 상태를 평균 풀링해 고정 차원의 텍스트 벡터 g(X_j)를 만든다. 이 벡터에 아이템 고유 임베딩 ˜v_j 를 더해 최종 아이템 표현 f(X_j)=g(X_j)+˜v_j 를 얻는다.
추천 예측은 사용자 임베딩 ˜u_i 와 아이템 표현 f(X_j) 의 내적에 사용자·아이템 바이어스(b_i, b_j)를 더한 형태로 계산된다: ŷ_{ij}=b_i+b_j+˜u_i^T f(X_j). 손실 함수는 암묵적 피드백 상황을 반영한 가중 제곱 오차이며, 관측된 긍정 피드백에 높은 가중치(c^+), 비관측 피드백에 낮은 가중치(c^−)를 부여한다. 이는 기존의 Weighted Matrix Factorization과 동일한 형태이다.
모델이 과도히 복잡해 과적합될 위험을 완화하기 위해 다중과제 학습을 도입한다. 아이템 텍스트 인코더를 공유하면서 부가 과제로 아이템 메타데이터(태그)를 예측한다. 태그 예측은 다중 라벨 로지스틱 회귀 손실을 사용해 동시에 최적화되며, 이는 인코더가 텍스트의 의미적·주제적 정보를 더 풍부히 학습하도록 유도한다. 태그는 학습 단계에서만 필요하고, 테스트 시에는 없어도 된다.
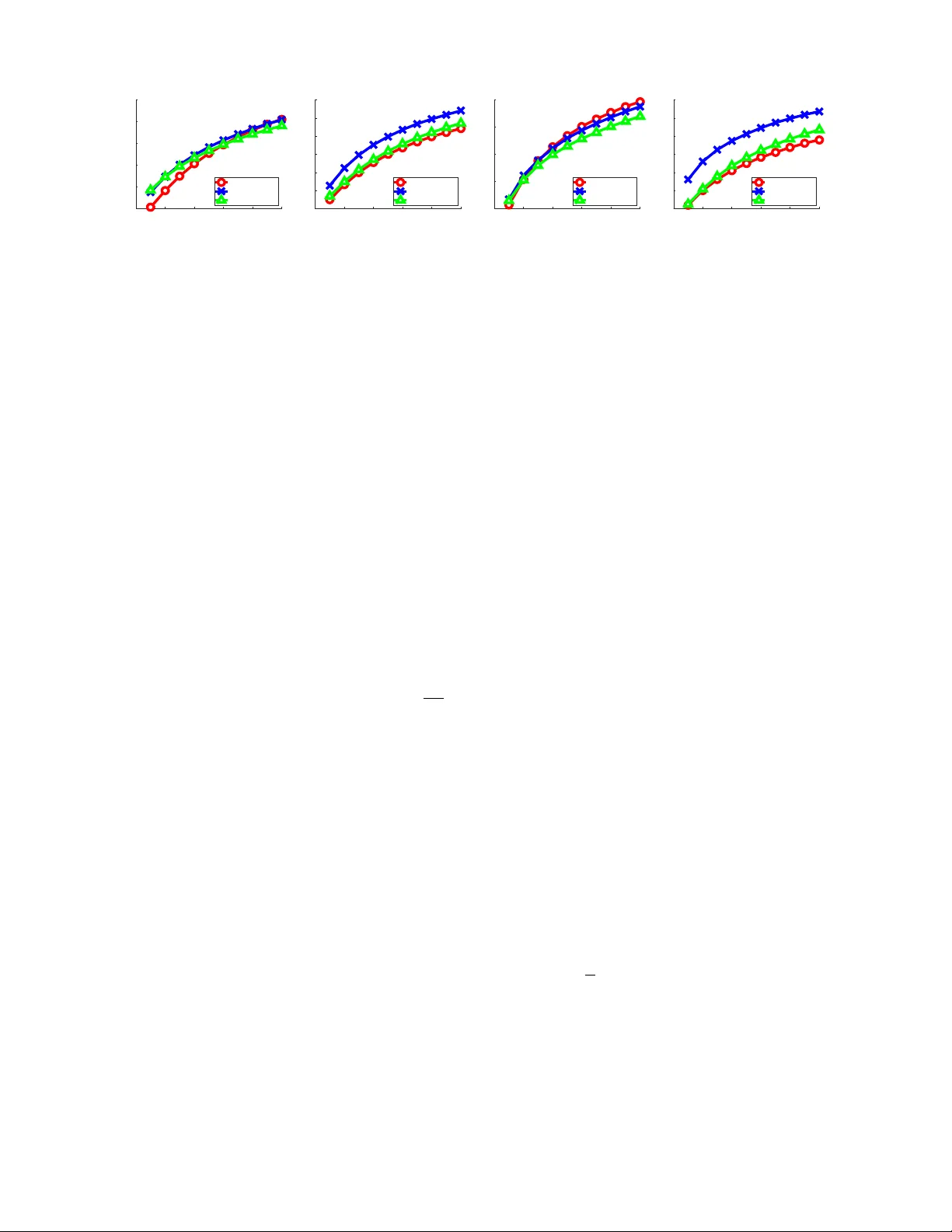
실험은 두 개의 공개 논문 데이터셋(ArXiv와 DBLP)에서 수행되었다. 각 논문은 초록 텍스트와 키워드(태그)를 제공한다. 평가는 콜드 스타트(새 아이템, ˜v_j=0)와 웜 스타트(기존 아이템, ˜v_j 학습) 두 시나리오로 나뉘며, Recall@50과 NDCG@50을 주요 지표로 사용한다. 비교 대상은 (1) Collaborative Topic Regression(CTR), (2) 평균 워드 임베딩 기반 모델, (3) 단순 선형 베이스라인이다.
결과는 다음과 같다. 콜드 스타트 상황에서 GRU 기반 모델은 CTR 대비 Recall@50에서 약 34% 향상을 보였으며, 평균 워드 임베딩 모델 대비도 유의미하게 앞섰다. 웜 스타트에서는 성능 차이가 다소 줄어들지만 여전히 경쟁력 있는 결과를 기록했다. 다중과제 학습을 적용했을 때는 모든 모델이 평균 5~7%의 추가 향상을 보였으며, 특히 태그 예측 정확도와 추천 성능이 동시에 개선되는 상호 보완 효과가 확인되었다.
논문의 주요 기여는 (1) 텍스트 순서를 고려한 GRU 인코더를 협업 필터링에 직접 통합함으로써 콜드 스타트 문제를 효과적으로 해결한 점, (2) 다중과제 학습을 통해 텍스트 인코더를 정규화하고 메타데이터 예측이라는 부가 정보를 활용한 점, (3) 실험을 통해 기존 토픽 모델 기반 방법보다 뛰어난 성능을 입증한 점이다.
한계점으로는 (a) 짧거나 품질이 낮은 텍스트에 대한 표현력 감소, (b) 태그가 없는 도메인에서 부가 과제 설계의 어려움, (c) 현재는 평균 풀링을 사용했으나 어텐션 메커니즘 등 더 정교한 집계 방법이 필요함을 들 수 있다. 향후 연구 방향은 (i) 사전 학습된 대규모 언어 모델(BERT, RoBERTa 등)과 결합해 인코더 성능을 극대화, (ii) 사용자 생성 텍스트(리뷰, 코멘트)를 함께 인코딩해 사용자‑아이템 상호작용을 더 풍부히 모델링, (iii) 어텐션 기반 풀링 및 하이퍼파라미터 자동 튜닝을 통한 모델 경량화 등이 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기