다양한 규모의 가치 학습을 위한 적응형 정규화
본 논문은 강화학습에서 값 함수의 크기가 정책 변화에 따라 크게 달라지는 문제를 해결하기 위해, 목표값을 실시간으로 정규화하는 “Pop‑Art”(Preserving Outputs Precisely while Adaptively Rescaling Targets) 기법을 제안한다. 기존 DQN에서 사용하던 보상 클리핑을 없애고도 학습 안정성을 유지하면서, 여러 Atari 게임에 동일한 하이퍼파라미터로 적용할 수 있음을 실험으로 보여준다.
저자: Hado van Hasselt, Arthur Guez, Matteo Hessel
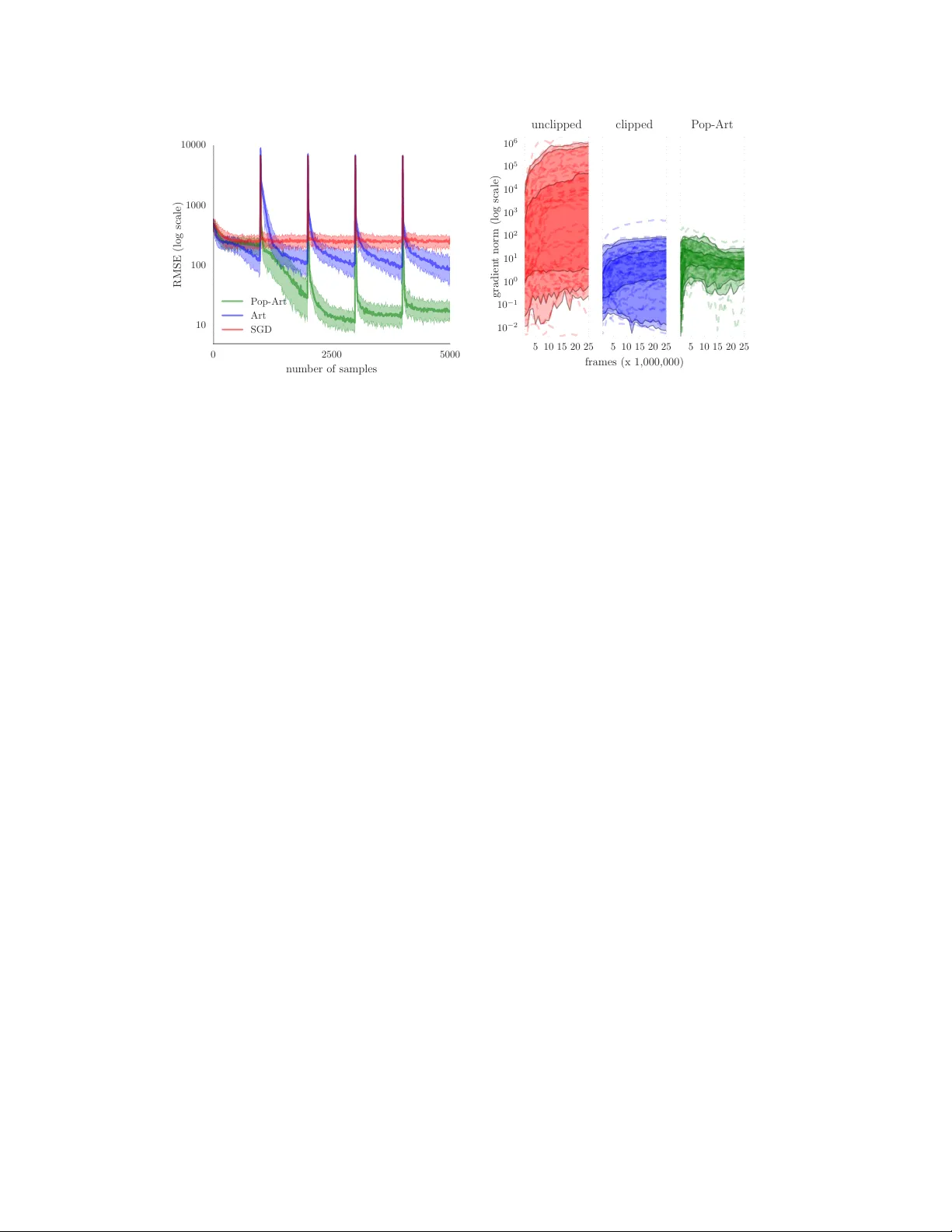
본 논문은 강화학습, 특히 딥 Q‑네트워크(DQN)에서 보상의 규모 차이가 학습에 미치는 부정적 영향을 해결하고자 “Pop‑Art”(Preserving Outputs Precisely while Adaptively Rescaling Targets)라는 적응형 목표 정규화 기법을 제안한다. 기존 DQN은 다양한 Atari 게임에 동일한 하이퍼파라미터를 적용하기 위해 보상과 TD‑오차를 \(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기